
本記事はデータベース入門記事の第4回「バックアップ・クラスター・レプリケーション」です。
本記事は以下の書籍を参考に執筆しています。
一番初めに読む本
経験者向けの入門本
MySQL を触る方におすすめ
なお、本記事ではデータベースの耐障害性・障害復旧に焦点を当てて以下の技術を解説します。
| 概念 | 説明 | 対策可能な障害 |
|---|---|---|
| バックアップ | ある時点のデータの複製 | ストレージのデータロスト |
| クラスター | ノード(コンピュータ)を複数用意 | ノード障害 |
| レプリケーション | 稼働中のデータの複製 クラスターのノード間でデータを複製する技術 | ストレージのデータロスト ノード障害 |
その他のデータベースの入門記事ついては以下の記事をご確認ください。
- 【データベース入門1】データベースとは
- 【データベース入門2】SQL コマンドとは、SQL 文の一覧
- 【データベース入門3】トランザクションと ACID 特性とは
- 【データベース入門4】バックアップ・クラスター・レプリケーション ←今ここ
- 【データベース入門5】テーブル設計・正規化
- 【データベース入門6】オプティマイザー・実行計画
バックアップ
バックアップ手法には次の3グループの手法があります。
- 「ホットバックアップ」or「コールドバックアップ」
- 「物理バックアップ」or「論理バックアップ」
- 「フルバックアップ」or「差分/増分バックアップ」
「ホットバックアップ」or「コールドバックアップ」
ホットバックアップとは、バックアップ対象のデータベースを稼働したままでバックアップデータを取得する方法です。
コールドバックアップとは、バックアップ対象のデータベースを停止してバックアップデータを取得する方法です。
代表的な RDBMS で各バックアップを取得する方法は以下のとおりです。
| RDBMS | ホットバックアップ | コールドバックアップ |
|---|---|---|
| MySQL | mysqldump | OS のコマンド:cp, tar コマンド等 |
| PostgreSQL | pg_dump | OS のコマンド:cp, tar コマンド等 |
「物理バックアップ」or「論理バックアップ」
物理バックアップとは、物理的なファイルをバックアップする方法です。
論理バックアップとは、SQL ベース等でバックアップする方法です。
「物理バックアップ」と「論理バックアップ」の性質の違いは以下のとおりです。
| 性質 | 物理バックアップ | 論理バックアップ |
|---|---|---|
| フォーマット | バイナリ形式 | テキスト形式 |
| バックアップ速度 | 速い | 遅い(バイナリ⇔テキストの変換が必要) |
| バックアップサイズ | 小さい | 大きい |
| 移植性 | 低い(他のバージョンや他のDBMSに移行不可能) | 高い(他のバージョンや他のDBMSに移行可能) |
| データ書き換え | 困難 | 容易(SQL 文を書き換えるだけ) |
代表的な RDBMS で各バックアップを取得する方法は以下のとおりです。
| RDBMS | 物理バックアップ | 論理バックアップ |
|---|---|---|
| MySQL | MySQLEnterpriseBackup | mysqldump |
| PostgreSQL | pg_basebackup | pg_dump |
「フルバックアップ」or「差分/増分バックアップ」
フルバックアップは、データベース全体をバックアップする方法です。

差分/増分バックアップは、直近のバックアップ以降に更新されたデータのみをバックアップする方法です。
- 差分バックアップ:直近のフルバックアップ以降に更新されたデータをバックアップする方法
- 増分バックアップ:直近のバックアップ(種別はフルとは限らない)以降に更新されたデータをバックアップする方法

「フルバックアップ」と「差分/増分バックアップ」の性質の違いは以下のとおりです。
| 性質 | フルバックアップ | 差分/増分バックアップ |
|---|---|---|
| リストア | 単純 | 複雑(PITR 後述します) |
| バックアップ取得時間 | 長い | 短い(変更したデータだけ) |
| バックアップサイズ | 大きい | 小さい |
代表的な RDBMS で各バックアップを取得する方法は以下のとおりです。
PITR(Point In Time Recovery)
PITR とは、「バックアップ + アーカイブログ(バックアップから変更した内容)」を利用して、特定の時点までデータをリカバリすることです。
PITR を利用したデータの復旧は以下の流れとなります。
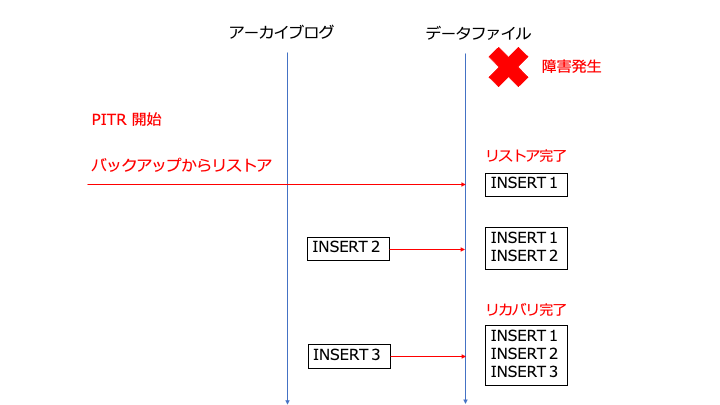
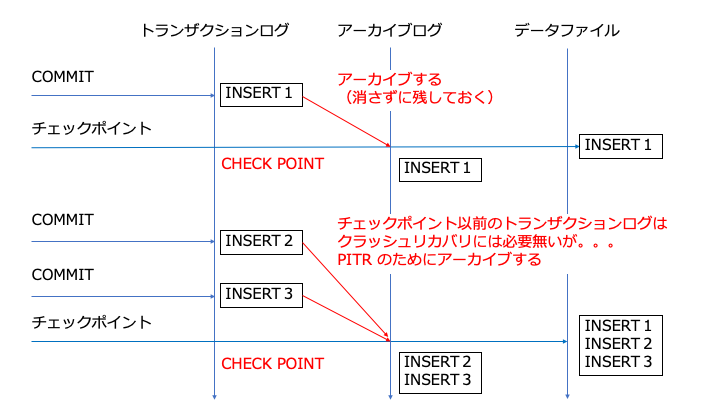
PITR はクラッシュリカバリのトランザクションログを利用した仕組みです。
多くの DBMS では、以下のようにトランザクションログをアーカイブし、アーカイブログとします。(MySQL の場合はバイナリログを利用します。)
クラスターとは
クラスターとは、1つの機能を実行するために、複数のコンピュータを利用することです。
構成をクラスター化する理由は、主に次の2つを向上させるためです。
- 「可用性(継続的に稼働すること)」
- 「パフォーマンス」
データベースにおけるクラスターには次の2つの概念があります。
- シェアードディスク vs シェアードナッシング
- アクティブ/アクティブ vs アクティブ/パッシブ(アクティブ/スタンバイ)
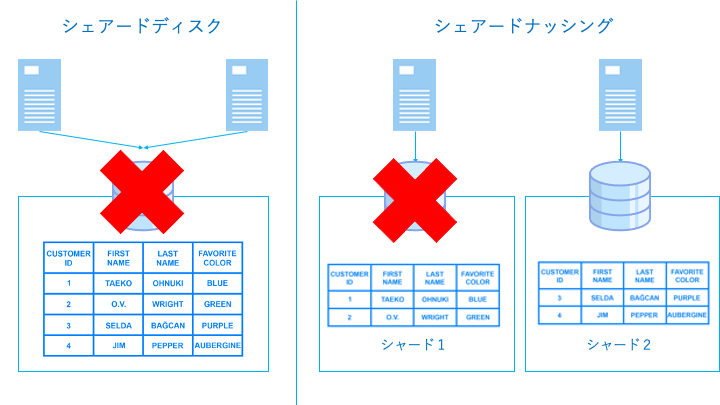
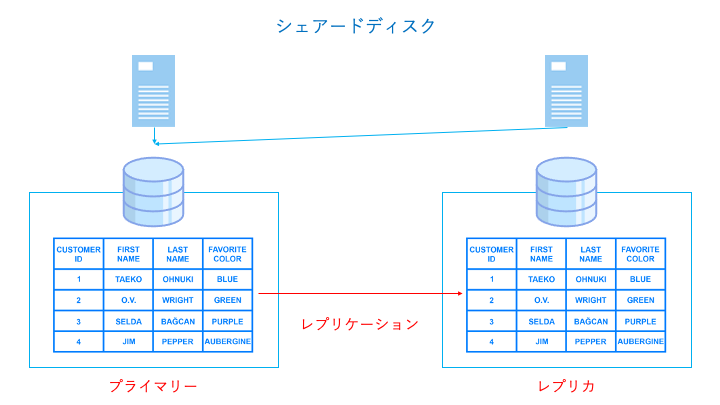
シェアードディスクとは
シェアードディスクとは、各ノード(コンピュータ)が共通のストレージを利用して並列して処理を行うことで、パフォーマンスを向上させるクラスター構成です。
シェアードディスクでは以下のように各ノードが共通のストレージを利用します。
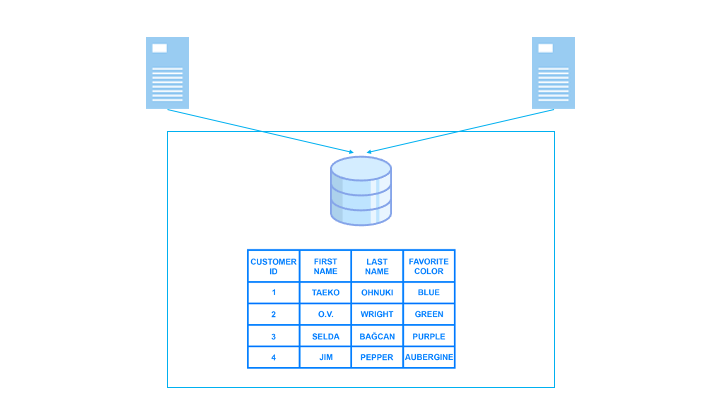
これにより、ノードを増やすことで CPU やメモリ等のリソースを追加することができます。
ただし、複数のノードが同じフィールドに対して同時に書き込むと、書き込みロックが発生します。また、ストレージは追加できないため、ストレージへのアクセスがボトルネックとなります。
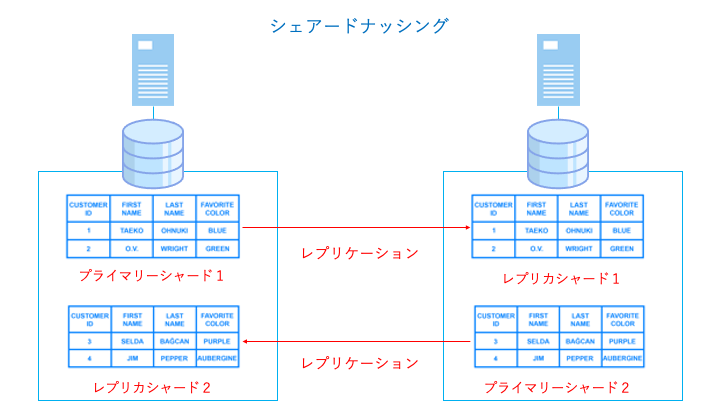
シェアードナッシングとは
シェアードナッシングとは、各ノード(コンピュータ)が別々のストレージを持つことでパフォーマンスを向上させるクラスター構成です。
シェアードナッシングでは、以下のように各ノードは別々のテーブル情報を持ちます。
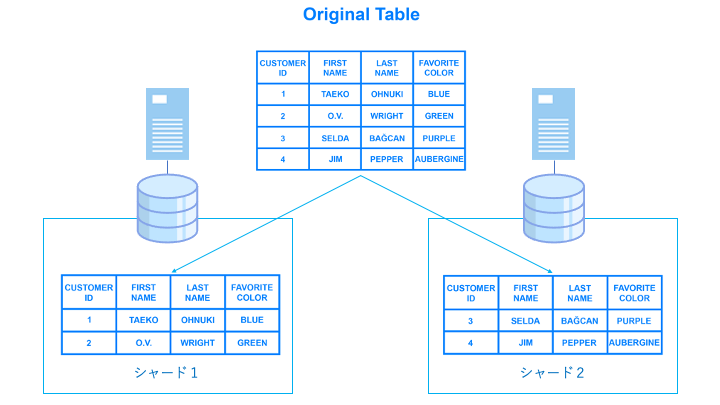
このテーブルを分割する単位をシャードと呼び、処理するテーブルデータが被らないようにします。これにより、各ノードは必ず処理するデータが他のノードと被らないため、ロックが発生しません。
つまりノードを増やせば増やすほどストレージの読み書きを分散できるため、パフォーマンスが求められる NoSQL で利用されることがあります。
シャーディング(レコードをシャードに振り分ける)には、次の3つの方法があります。
- Key Based Sharding
- Range Based Sharding
- Directory Based Sharding
Hash Base Sharding (Key Based Sharding)
Hash Base Sharding とは、指定したカラムのハッシュ値を元にレコードをシャードに振り分ける方法です。
以下の図は COLUMN1 に対してハッシュ関数を利用して、シャード1、2のどちらかにレコードを割り当てています。
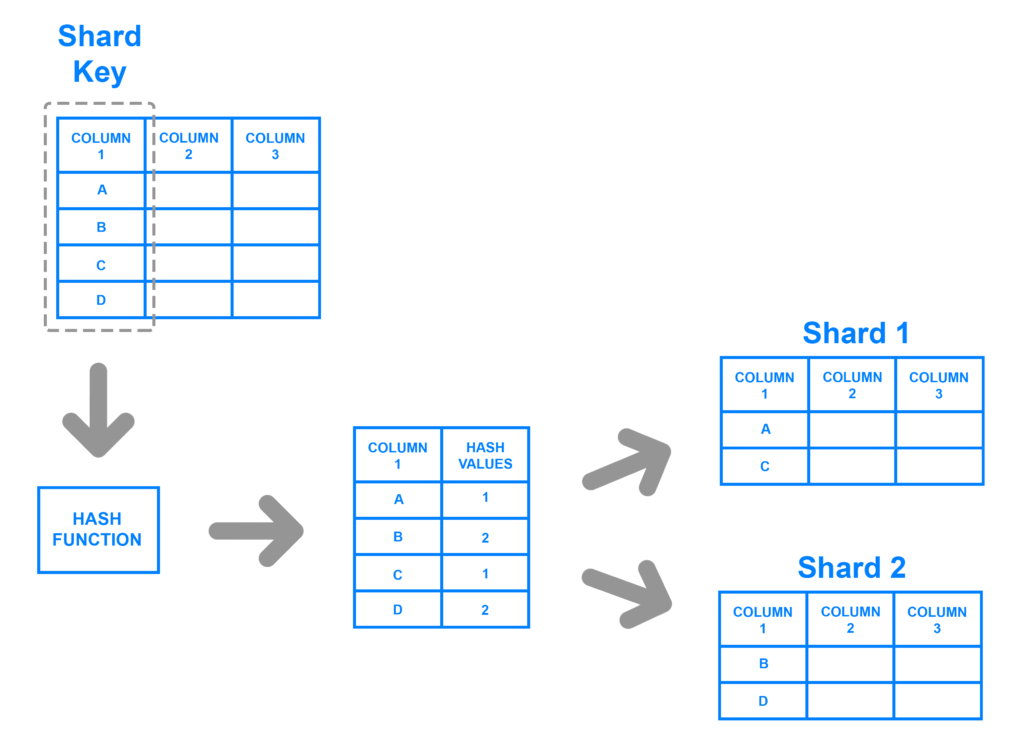
ハッシュ値のとりうる値 = シャードの数です。
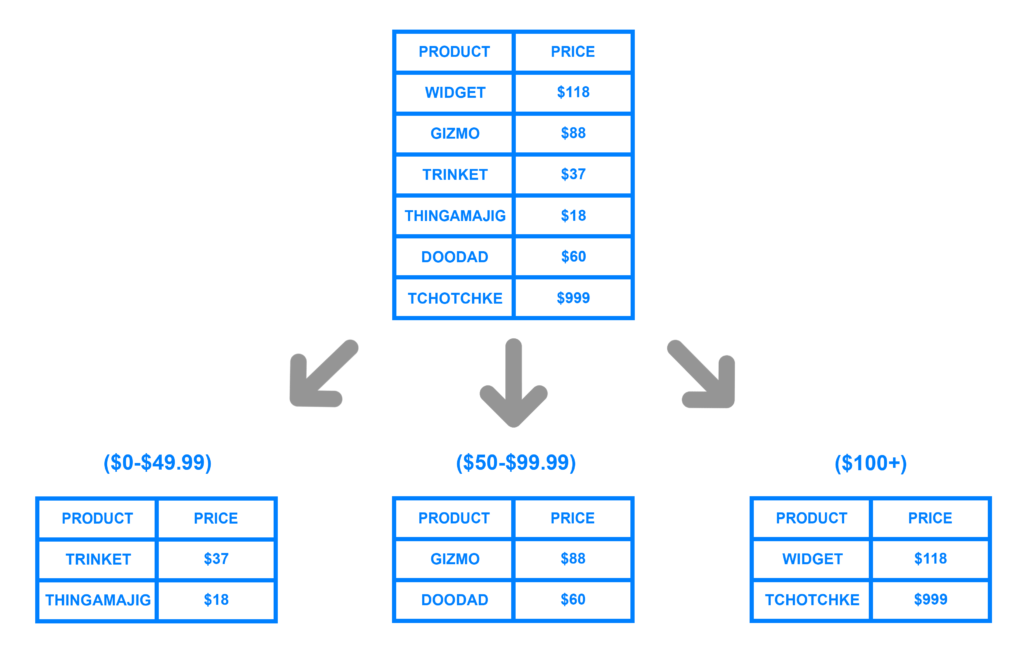
Range Based Sharding
Range Based Sharding とは、値の範囲ごとにレコードをシャードに振り分ける方法です。
以下の例では、PRICE カラムの値を元に3つのシャードに振り分けています。
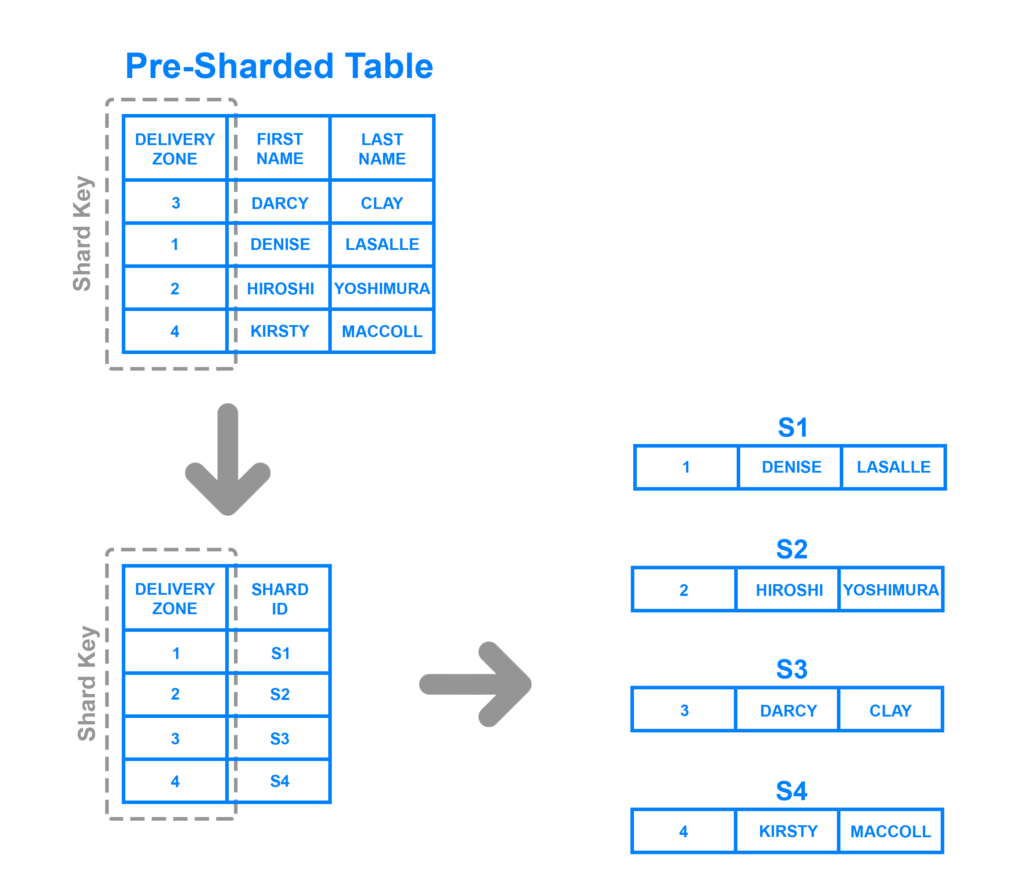
Directory Based Sharding
Directory Based Sharding は、カラムでシャードを指定することで、レコードをシャードに振り分ける方法です。
以下の例では、DELIVERY ZONE カラムで振り分けるシャードを指定しています。
アクティブ/パッシブ(アクティブ/スタンバイ)構成とは
アクティブ/パッシブ構成とは、いくつかのノードを待機状態にして、障害時に切り替えて処理を引き継ぐことで可用性を向上させるクラスター構成です。
アクティブ/パッシブ構成の動作は以下のとおりです。

アクティブ/パッシブ構成は、パッシブ側の状態によって次のように分かれます。
コールドスタンバイにする理由は、待機中のデータベースライセンス費をカットできることです。その代わり、障害が発生してからデータベースを起動するため、切り替えが遅くなります。
アクティブ/アクティブ構成とは
アクティブ/アクティブ構成とは、通常時は全てのノードを稼働させパフォーマンスを向上し、障害発生時は残ったノードで処理を継続することで可用性を向上させるクラスター構成です。
アクティブ/アクティブ構成の動作は以下のとおりです。

アクティブ/アクティブでは、アクティブ/パッシブとは異なり正常時は両方のノードが稼働します。
障害時は残ったノードに負荷が集中する点については注意が必要です。
また、複数のノードがほぼ同時に書き込みを行うと、後から書き込んだノードに上書きされることを防ぐために以下の対策があります。
- シェアードディスク:行ロック
- シェアードナッシング:シャーディング
レプリケーション
レプリケーションとは、データの複製(レプリカ)を別のストレージにも保存することです。
レプリケーションでは、役割ごとに以下のように呼びます。
- 書き込み/読み込み可能:マスター・プライマリー等と呼ぶ
- 読み込みのみ可能:レプリカ・セカンダリ・スレーブ・スタンバイ等と呼ぶ
今まで紹介したクラスター構成では、ストレージに障害が発生すると、一部もしくは全てのデータを失います。
そこで、ストレージにあるデータをレプリケーションすることで冗長化します。
なお、レプリカは読み込み可能なので、クライアントからの読み込みクエリを負荷分散可能という副産物もあります。
レプリケーションのやり方には次の2種類の方法があります。
- シングルマスターレプリケーション(レプリケーションは通常、こちらを指す)
- マルチマスターレプリケーション
シングルマスターレプリケーションとは
シングルマスターレプリケーションとは、1つのマスターと1つ以上のレプリカを持つ構成のことです。
そのため、クライアントからの書き込みクエリはマスターの役割を持つノードでしか行なえません。
シングルマスターレプリケーションでは、バイナリログ(MySQL の場合)やトランザクションログ(PostgreSQL の場合 WAL ログ)を利用して、マスター側の更新をレプリカ側に反映します。
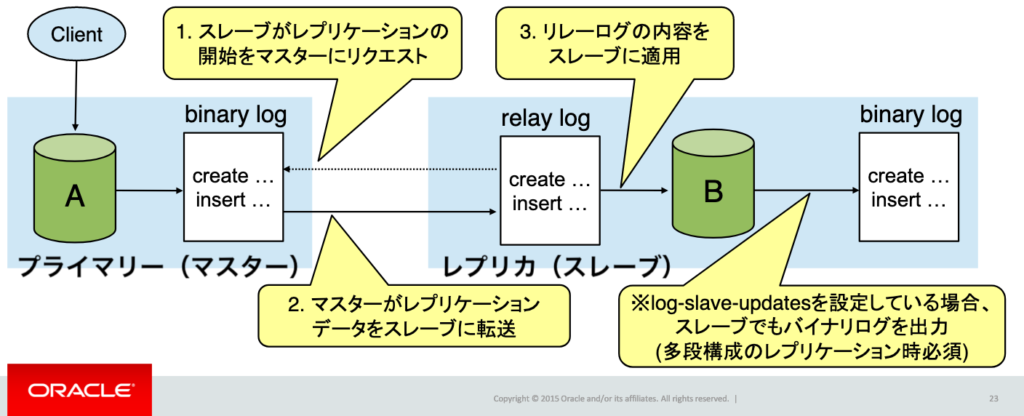
https://downloads.mysql.com/presentations/20151207_02_MySQL_Replication_for_Beginners.pdf
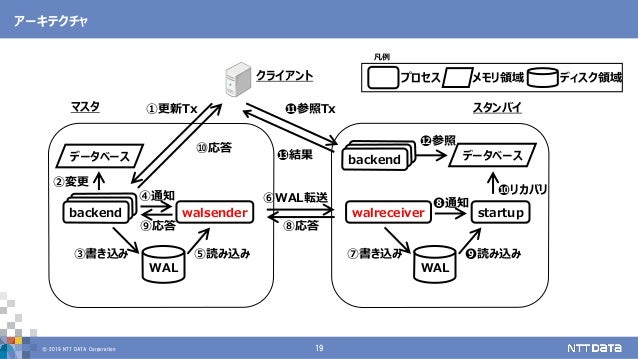
※スタンバイ=レプリカ
https://www.slideshare.net/nttdata-tech/postgresql-replication-10years-nttdata-fujii-masao
マスターの役割を持つノードに障害が発生した場合、レプリカの役割を持つノードがマスターに切り替わります(フェイルオーバーと言います)。
マルチマスターレプリケーションとは
マルチマスターレプリケーションとは、全てのノードがマスターとなる構成のことです。
マルチマスターレプリケーションでは全てのノードでクライアントからの書き込みクエリが実行可能です。また、全てのマスターが他のマスターの更新結果のレプリケーションを受け取ります。
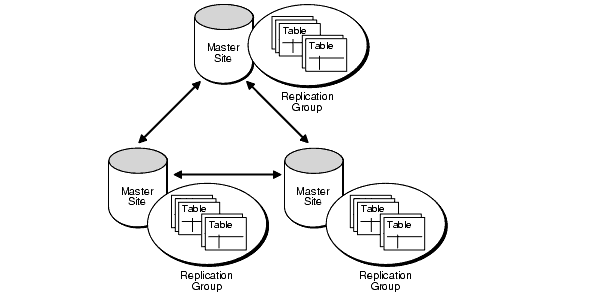
複数のノードが同じテーブルに書き込む場合、後から書き込んだ内容に上書きされることを防ぐために、テーブルロックを行ったり、シャーディングを行うことで対策します。
最後に
データベース入門記事「バックアップ・クラスター・レプリケーション」に関する説明は以上となります。
その他のデータベースの入門記事ついては以下の記事をどうぞ。
- 【データベース入門1】データベースとは
- 【データベース入門2】SQL コマンドとは、SQL 文の一覧
- 【データベース入門3】トランザクションと ACID 特性とは
- 【データベース入門4】バックアップ・クラスター・レプリケーション ←今ここ
- 【データベース入門5】テーブル設計・正規化
- 【データベース入門6】オプティマイザー・実行計画
参考資料・おすすめの書籍
一番初めに読む本
経験者向けの入門本
MySQL を触る方におすすめ
MySQL5.7入門(バックアップ編)
https://downloads.mysql.com/presentations/20151208_01_MySQL_Backup_for_Beginners.pdf
MySQL 5.7入門(レプリケーション編)
https://downloads.mysql.com/presentations/20151207_02_MySQL_Replication_for_Beginners.pdf