 ビッグデータ分析
ビッグデータ分析 【入門】ビッグデータ分析基盤とは?データパイプラインを構築
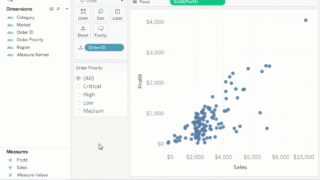
ビッグデータ ビッグデータとは、通常のソフトウェアでは処理できないほどの大規模な (テラバイト、ペタバイト、エクサバイト規模の) データのことです。本記事では、ビッグデータを以下のように可視化、分析することをゴールとします。ビッグデータがス...
ビッグデータ分析  コンテナ
コンテナ  ビッグデータ分析
ビッグデータ分析