初めに
本記事は、以下のビッグデータ分析基盤シリーズの Apache Spark 編です。
- 【ビッグデータ入門1】ビッグデータ分析基盤
- 【ビッグデータ入門2】ストリーム処理
- 【ビッグデータ入門3】fluentd
- 【ビッグデータ入門4】Elasticsearch
- 【ビッグデータ入門5】Apache Kafka
- 【ビッグデータ入門6】Apache Hadoop
- 【ビッグデータ入門7】Apache Spark
- 【ビッグデータ入門8】Apache Hive
対象者
- Apache Spark をゼロ知識から知りたい人
- Apache Spark が動く環境が欲しい人
Apache Spark とは
簡単に言うとたくさんのコンピュータを使ってめっちゃ早く計算するためのライブラリ群です。かしこまった言い方をすると・・・
Apache Spark は並列分散処理の基盤上にて、インメモリで処理を行うためのコンピューティングフレームワークです。
並列分散処理とは
並列分散処理とは、複数のコンピュータが協力して処理を行うことです。
1 人で作業するより、10 人で分担したほうが速いよねっていう話です。ただし、あまりにも簡単な作業の場合、分担作業をする間に一人でやったほうが早い点には注意してください。
ビッグデータ分析において Spark の立ち位置は ETL, SQL クエリエンジン(Spark SQL)に当たります。詳細は以下の記事をご覧ください。
Apache Spark は単体(Spark Standalone Cluster)で起動することも、Hadoop で起動することも可能です。
Hadoop で起動する場合は、Spark が Hadoop 上でどの機能に位置するのかについては以下の記事をご覧ください。
インメモリとは
インメモリとは、データストレージとしてストレージデバイス(SSD, HDD)ではなく、メインメモリを利用する方式のことです。
ストレージデバイスやメインメモリや後述するレジスタの違いは以下の記事のハードウェアの章で解説しています。

インメモリの利点を見るために、従来方式とインメモリ方式を比較します
従来方式:ストレージデバイスをデータストレージとして利用する場合
HDD や SSD をデータストレージとして利用する場合、以下のように処理を実施します。
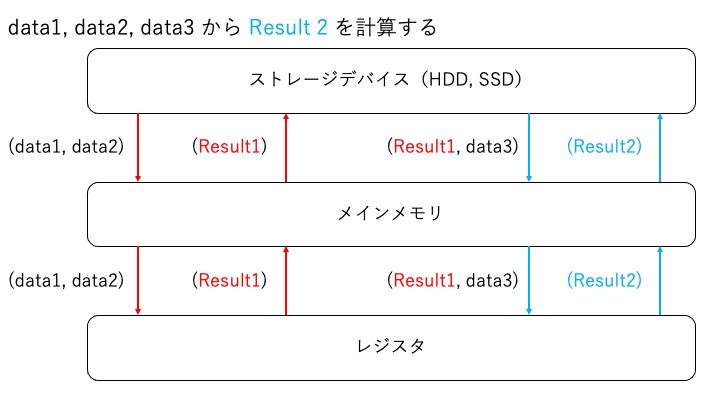
上記の方式を見て、「Result1 を 1 度 HDD, SDD に書き戻して、もう 1 度読み直す処理なんて非効率だ!Result1 をメインメモリに置きっぱなしにしよう!」という考えに基づいて開発されたのがインメモリ方式の Apache Spark です。
インメモリ方式:メインメモリをデータストレージとして利用する場合
メインメモリをデータストレージとして利用する場合、以下のように処理を実施します。Apache Spark のフレームワークではこちらの方式を利用します。また、最終結果 Result2 のデータストレージとして HDD, SSD に Result2 を出力することも可能です。
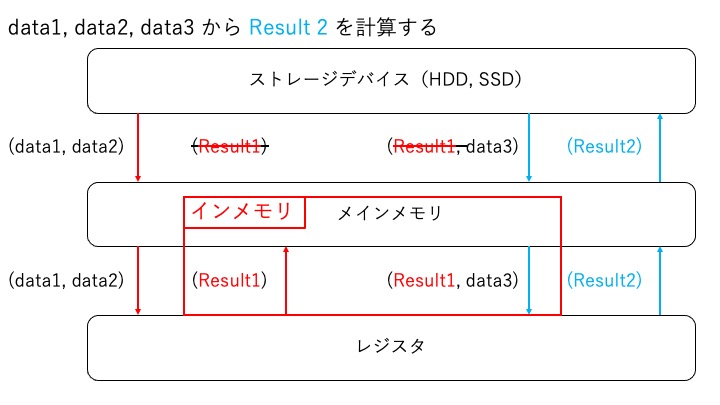
インメモリを利用すると高速化される点は以下の 2 点です。
- HDD, SSD へ Result1 の書き込みをスキップすることで高速化
- HDD, SSD の代わりにメインメモリから Result1 を読み込むことで高速化
前者は手順が無くなるため高速化され、後者はメインメモリと SSD へのアクセス速度の差で高速化されます。
下記のブログによるとメインメモリへのアクセス速度は SSD へのアクセス速度と比較して 500 倍高速だそうです。メインメモリからの読み込みが増えるほど高速化が期待できますね。
- メインメモリへのアクセスは 100 * 10-9 s
- NVMe SSD へのアクセスは 50 * 10-6 s

さて、ここでもう 1 度 Apache Spark の説明を見て見ましょう。
Apache Spark は並列分散処理の基盤上にて、インメモリで処理を行うためのコンピューティングフレームワークです。
Apache Spark は大規模なデータに対して高速に処理するために用意されたフレームワークであることが理解できるはずです。
Apache Spark をインストール
- sudo yum install -y java-1.8.0-openjdk
-
現在ダウンロード可能なバージョンを http://ftp.jaist.ac.jp/pub/apache/spark/ で確認します。
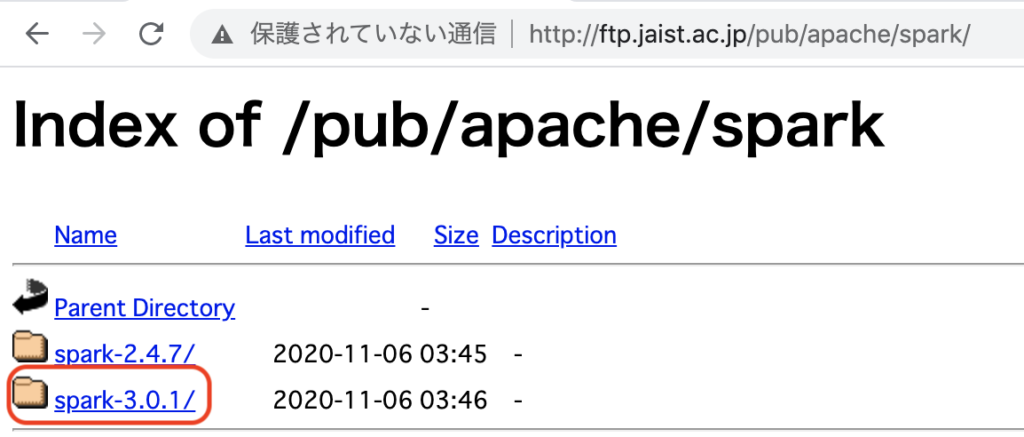
spark-3.x.x をクリック URL と Spark 名の名前を合わせたものをメモします。
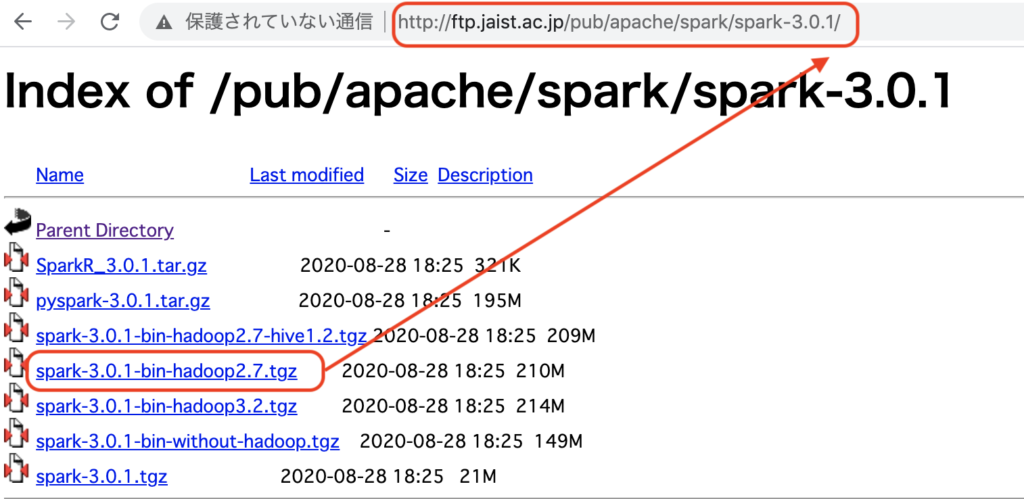
URL + <ダウンロードするファイル名> を手順2の curl コマンドで指定する 上記でメモした URL + spark 名を以下のコマンドでインストールします。赤線の場所で spark のバージョンを指定しています。
- sudo tar zxvf spark-3.0.1-bin-hadoop2.7.tgz -C /usr/local/lib/
以下のエラーメッセージが出た場合
tar: これは tar アーカイブではないようです gzip: stdin: not in gzip format tar: Child returned status 1 tar: Error is not recoverable: exiting now
spark で最新バージョンがリリースされており、古い URL が存在しないと考えられます。Spark の最新バージョンの URL を確認するために、手順2からやり直してください。
- vim ~/.bash_profile
export SPARK_HOME=/usr/local/lib/spark export PATH=$SPARK_HOME/bin:$PATH
- bash_profile のリロードsource ~/.bash_profile
-
pysparkなお、Scala 版は spark-shell コマンドで起動できます。
Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.0.0 /_/ Using Python version 2.7.16 (default, Dec 12 2019 23:58:22) SparkSession available as 'spark'.
無事に Apache Spark の インタラクティブシェルが起動できました。ちなみにこの状態では、単体サーバーで Apache Spark を起動しています。
並列分散処理の基盤上で pyspark を起動させたい場合
ここでは、並列分散処理の基盤に Spark Standalone Cluster を利用して pyspark を起動させてみます。Spark Standalone Cluster に参加するそれぞれのサーバーを「ノード」と言います。ノードは役割によって次の 2 種類が存在します。
以降ではサーバー A をマスターノード、サーバー B をスレーブノードとする Spark Standalone Cluster を構築します。サーバー A の作業
- サーバー A を Spark Standalone Cluster のマスターノードとして稼働する
$ cd $SPARK_HOME
$ ./sbin/start-master.sh - localhost:8080 にアクセスして、マスターノードの URL を確認する。

サーバー B の作業(要: Apache Spark インストール)
- サーバー B を Spark Standalone Cluster のスレーブノードとして稼働する
$ cd $SPARK_HOME
$ ./sbin/start-slave.sh "<マスターノードの URL>" - サーバー B クラスターに参加して PySpark を起動
$ pyspark --master "<マスターノードの URL>"
おめでとうございます。並列分散処理の基盤(Spark Standalone Cluster)上で pyspark を起動することができました。
なお、pyspark コマンドのオプション --master では Spark Standalone Cluster 以外のマスターノードも指定できます。詳細な説明は下記のリンクに記載があります。

Apache Spark の使い方
pyspark 上で Spark Python API を利用して Apache Spark を動かしてみます。
Apache Spark ではデータを RDD (resilient distributed dataset) と呼ばれるコレクションとして扱うことで、インメモリ上で並列処理が可能となります。
RDD の細かい仕様は今は気にする必要はありませんが、詳しく知りたい人はこちらがわかりやすいです。
● テスト用の List 型データ list を作成
list = [1,2,3,4,5]
● RDD を作成 parallelize()
Spark 上でデータを操作するためには、RDD 型に変換する必要があります。RDD 型にはparallelize() メソッドを利用して変換します。
rdd = sc.parallelize(list)
● RDD の要素をカウント count()
rdd.count()
5
● RDD の要素を値の大きいものから順番に返す top()
値の大きい要素、上位2つを返却してみます。
rdd.top(2)
[5, 4]
値の大きいもの 2 つが返却されていることがわかります。
とても簡単ですね。後は自分のやりたい計算に応じて、以下の記事を参考に API を探してみてください。

本記事は入門編なので、ここで終わりにしたいと思います。この記事では Apache Spark の概要からインストールし実際に API を操作するところまでで説明しました。Apache Spark って意外と簡単に触れるんだよってことが多くの人に伝われば幸いです。
関連記事
ビッグデータ分析基盤入門シリーズの続きは以下です。
- 【ビッグデータ入門1】ビッグデータ分析基盤
- 【ビッグデータ入門2】ストリーム処理
- 【ビッグデータ入門3】fluentd
- 【ビッグデータ入門4】Elasticsearch
- 【ビッグデータ入門5】Apache Kafka
- 【ビッグデータ入門6】Apache Hadoop
- 【ビッグデータ入門7】Apache Spark
- 【ビッグデータ入門8】Apache Hive