「ビッグデータを1台のコンピュータで処理すると時間がかかりすぎるため、コンピューターをいっぱい並べて高速に処理しよう。」というのが Hadoop 導入のモチベーションになります。
初めに
本記事は、ビッグデータ分析基盤シリーズの Hadoop 編です。
- 【ビッグデータ入門1】ビッグデータ分析基盤
- 【ビッグデータ入門2】ストリーム処理
- 【ビッグデータ入門3】fluentd
- 【ビッグデータ入門4】Elasticsearch
- 【ビッグデータ入門5】Apache Kafka
- 【ビッグデータ入門6】Apache Hadoop
- 【ビッグデータ入門7】Apache Spark
- 【ビッグデータ入門8】Apache Hive
本記事の対象者
- Hadoopって何?どんな構成なの?
- Hadoop エコシステム(できること)一覧を知りたい
- Hadoop の環境構築をしたい
- WordCount(Hadoop における Hello World)が実行できるようになりたい
Hadoop を構成する3つのレイヤー
Hadoop のアーキテクチャは、主に以下の3つのレイヤーから構成されます。
- 分散処理エンジン(Hadoop では Hadoop MapReduce を利用)
- リソースマネージャー(Hadoop では Hadoop YARN を利用)
- 分散ファイルシステム(Hadoop では HDFS を利用)
また、Hadoop ではデータにアクセスするためにクエリエンジンを利用することが多いです。
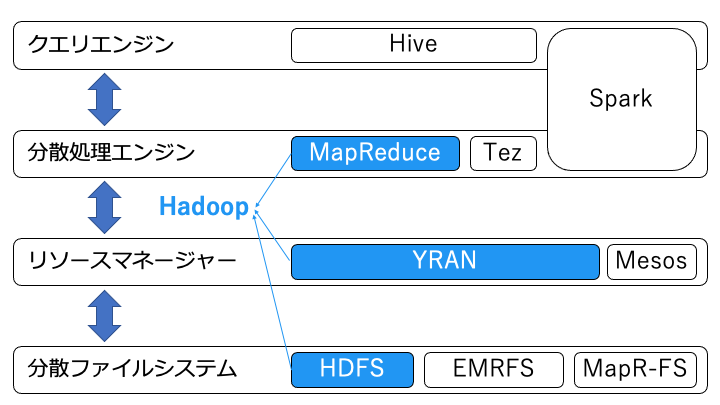
Hadoop では、すべてのコンピュータに上記の構成をインストールし、データの読み書きや処理を分散します。
分散処理エンジン
分散処理エンジンは、Hadoop における並列分散処理を担うソフトウェア群のことです。
デフォルトでは MapReduce と呼ばれる分散処理エンジンが稼働しています。
MapReduce 処理の概要について
MapReduce は以下の手順で分散処理を行います。
- Map: 入力を key-value 形式として出力、各 Map をノードごとに分散可能
- Shuffle: Map の出力をソート
- Reduce: 同じキーを集約
https://software.fujitsu.com/jp/manual/manualfiles/m160011/j2ul1930/02z200/j1930-00-01-01-00.html
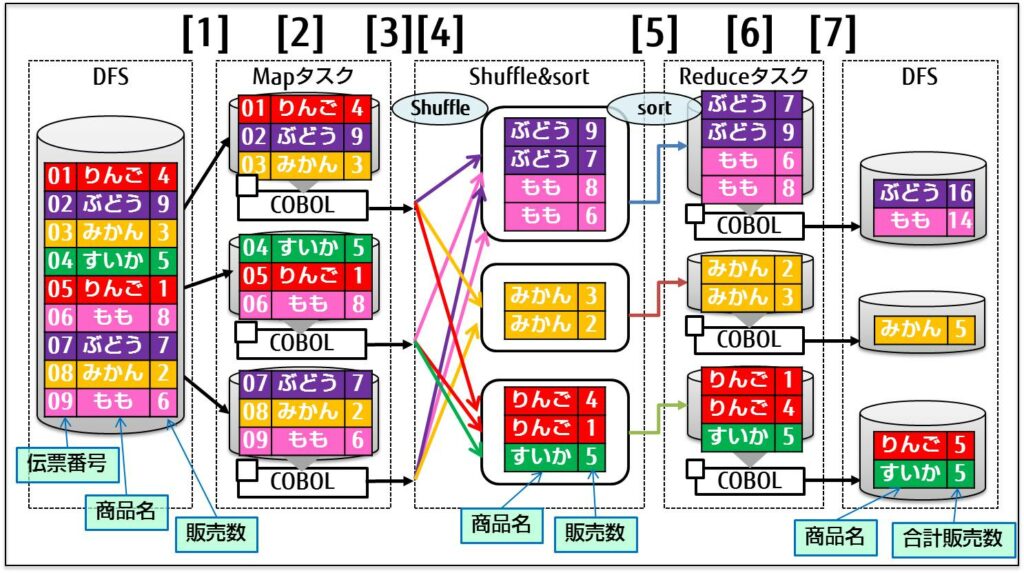
代表的な分散処理エンジンの特徴は以下のとおりです。下に行くほど速いです。
Spark については以下の記事で詳細を解説しているのでご覧ください。
ちなみに MapReduce はオワコンらしいので Tez か Spark を使いましょう。
リソースマネージャー
リソースマネージャーは、Hadoop におけるリソース(CPU ,メモリ)管理を担います。
MapReduce で利用するリソースマネージャーは、アプリケーションレベルのコンテナを管理する Hadoop YARN です。Hadoop YANR の動作については下記の記事がわかりやすいです。

その他にも OS レベルのコンテナを管理する Apache Mesos もあります。こちらは docker と同じ技術(Linux コンテナ)を利用します。
分散ファイルシステム
分散ファイルシステムは、Hadoop におけるデータの読み書きの分散を担います。Hadoop 上で利用される分散ファイルシステムには以下のものがあります。
他にもストレージとして Cloud Storage や Blob Storage を利用可能なようですが、内部でどんな分散ファイルシステムを利用するのかは不明です。(公開されていたら誰か教えて下さい)
Hadoop エコシステム一覧
デフォルト以外の Hadoop を構成するソフトウェア、もしくは周辺のソフトウェアを Hadoop エコシステムと言います。
Hadoop エコシステムは以下のように組み合わせることで、様々な分散処理が実現可能です。

- 全文検索構成例:Hadoop + Elasticsearch
Elasticsearch for Apache Hadoop を利用して全文検索サービスを実装できます。Hadoop の分散ファイルシステムとして Elasticsearch クラスターを利用します。
Elasticsearch については以下の記事で解説しています。

- ストリーム処理構成例:各サーバーや IoT機器 --> Kafka --> Hadoop
複数のサーバーや IoT 機器からストリーム処理を行い、Hadoop にデータを集約する場合は Kafka を利用します。
Kafka については以下に記事で解説しています。

以下に代表的な Hadoop エコシステムや関連するシステムと、その機能を紹介します。
| Hadoop エコシステム | 実現する機能 |
|---|---|
| Apache Accumulo | KVS型のNoSQL。セキュリティ重視 |
| Apache Atlas | ガバナンスコントロール、コンプライアンス対応 |
| Cascading | MapReduceを簡単に扱うAPI |
| Apache Drill | エッジ機器のデータを操作する分散SQLエンジン |
| Apache falcon | データライフサイクルを管理 |
| Apache Flume | 複数のデータソースからHadoopに非構造化データを集約(ストリームデータ処理) |
| Apache HBase | KVS型のNoSQL |
| Apache Hive | SQLライク(HiveQL)なクエリでデータを操作できる。対障害性重視する場合。DWHを実現 |
| Apache Hue | HadoopやHadoopエコシステムGUIで操作 |
| Apache Impala | SQLライク(Impala SQL)なクエリでデータを操作できる。速度を重視する場合。リアルタイム処理を実現 |
| Apache Kafka | 複数のデータソースからHadoopに非構造化データを集約(ストリームデータ処理)。flumeとの違いはここ |
| Apache Knox | 集中管理型の認証・アクセス管理 |
| Apache Mahout | 線形代数、統計解析、機械学習ライブラリ |
| Apache Mesos | OS レベルのコンテナを管理するリソースマネージャー |
| Apache Oozie | ジョブのスケジューラ |
| Apache Phoenix | HBaseをデータストアとして利用するリアルタイムRDB |
| Apache Pig | データの加工(ETL)ツール |
| Apache Ranger | 認証済みのユーザーに対して属性ベースでアクセス権限を付与 |
| Apache Sentry | 認証済みのユーザーに対してロールベースでアクセス権限を付与 |
| Apache Slider | YARNアプリケーションの制御。長時間起動している場合はKillするなど |
| Apache Solr | 全文検索(Elasticsearchで利用されています。) |
| Apache Spark | 機械学習、SQL操作、R言語、グラフをインメモリで処理 |
| Apache Sqoop | RDBMSからHadoopに構造化データのインポート、エクスポート |
| Apache Tez | MapReduceより速い分散処理フレームワーク |
| Presto | 中間結果をメモリに出力する SQL クエリエンジン。 Hive との違いはこちら |
Hadoop をインストール
ここからは Hadoop をインストールし、実際に Hadoop を触ってみます。
事前準備:Java 8 をインストール
openjdk version "1.8.0_265" OpenJDK Runtime Environment (build 1.8.0_265-b01) OpenJDK 64-Bit Server VM (build 25.265-b01, mixed mode)
Hadoop をインストール
以下のサイトからダウンロードする Hadoop のバージョンに対応する URL を確認します。

今回は現時点での最新バージョンである hadoop-3.3.0 をダウンロードします。
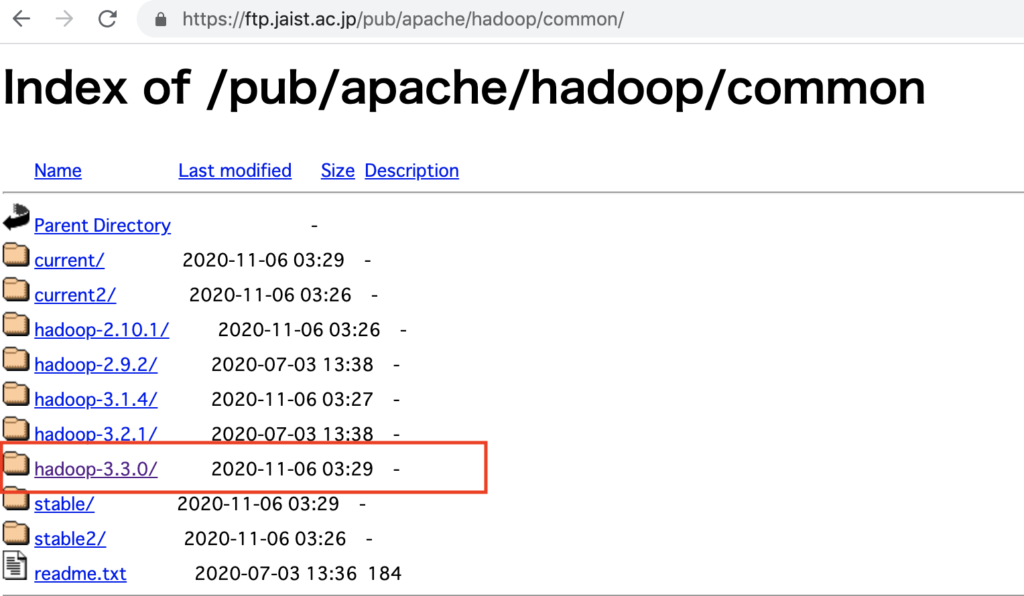
<現在の URL> + <ダウンロードするアーカイブ名> をメモします。
例:https://ftp.jaist.ac.jp/pub/apache/hadoop/common/hadoop-<バージョン名>/hadoop-<バージョン番号>.tar.gz
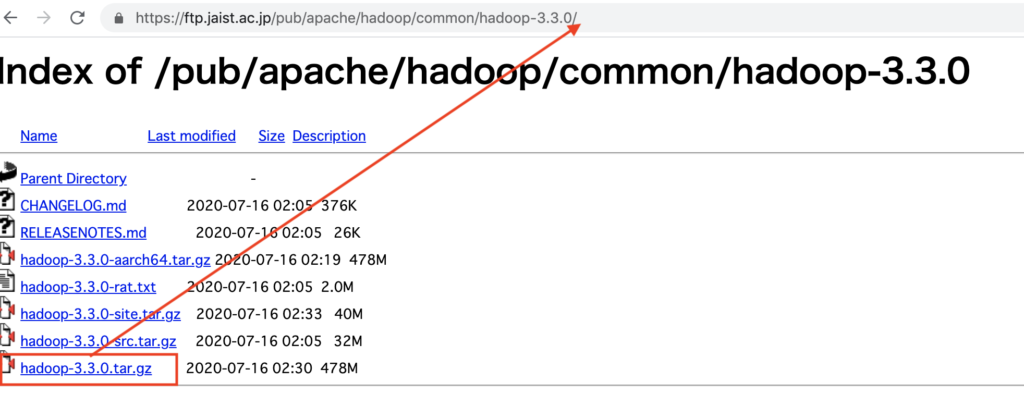
メモした URL を指定してダウンロードします。
※Hadoop が更新されると、リポジトリから古いバージョンは削除されるため必ず赤線箇所のバージョンは上記でメモした URL に置き換えてください
Hadoop を利用するための設定
Hadoop 自体の設定
Hadoop で利用する JAVA_HOME 環境変数を設定します。
export JAVA_HOME=$(dirname $(readlink $(readlink $(which java)))|sed 's/\/jre\/bin//g')
JAVA_HOME の場所は /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.265.b01-1.amzn2.0.1.x86_64 となるようなコマンドを実行しています。
次に分散ファイルシステム HDFS にアクセスする URL を設定します。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/ec2-user/var/lib/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/ec2-user/var/lib/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
赤線箇所は必ず自分のホームディレクトリ(Hadoop をインストールしたディレクトリ)を指定してください。
Hadoop を起動
まずは Hadoop を初期化します。
tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN 7707/java tcp 0 0 127.0.0.1:9000 127.0.0.1:37980 ESTABLISHED 7707/java tcp 0 0 127.0.0.1:37980 127.0.0.1:9000 ESTABLISHED 7868/java
9000 番ポートが LISTEN になっていない場合、どこかの設定が間違っている可能性があります。
作成したディレクトリが表示されれば成功です。実行したコマンドの詳細は次節で解説します。補足ですが、Hadoop を停止するには「$HADOOP_HOME/sbin/stop-dfs.sh」コマンドを実行します。
Hadoop 分散ファイルシステムの使い方
Hadoop の分散ファイルシステムは hadoop fs コマンドで操作します。
Found 1 items drwxr-xr-x - ec2-user supergroup 0 2020-11-25 16:59 /user
その他にも hadoop fs コマンドでは、Linux でよく利用する cat, rm, cp など様々なオプションが用意されています。hadoop fs コマンドのオプション一覧は以下の公式ドキュメントをご覧ください。

なお、通常の ls コマンドの結果と比較することで、ローカルのファイルシステム(Linux では xfs ファイルシステムなど)とHadoop の分散ファイルシステムでは、別のファイルが管理されていることがわかります。
bin boot dev etc home lib lib64 local media mnt opt proc root run sbin srv sys tmp usr var
ローカルのファイルシステムから Hadoop の分散ファイルシステムにファイルを移動
Hadoop でファイルを処理するためには、Hadoop の分散ファイルシステムにファイルを置く必要があります。
ローカルのファイルシステムから Hadoop の分散ファイルシステムにファイルをコピーする場合は put オプションを利用します。
コピーするファイルの準備
put オプションを利用して分散ファイルシステムにファイルをコピー
ローカルファイルシステムにあるファイル file01, file02 を Hadoop の分散ファイルシステムにある /user/hadoop パスにコピーします。
Found 2 items -rw-r--r-- 1 hadoop hadoop 22 2020-11-24 14:10 /user/hadoop/file01 -rw-r--r-- 1 hadoop hadoop 28 2020-11-24 14:10 /user/hadoop/file02
Hadoop の分散ファイルシステムの /user/hadoop パスに file01, file02 がコピーできていることがわかります。
Hadoop MapReduce で WordCount を実装
MapReduce は 分散処理エンジンの章で記載したとおり Hadoop で稼働するデフォルトの分散処理エンジンです。
ここでは Hadoop の分散処理における HelloWorld 的な立ち位置にいる WordCount プログラムを実装します。WordCount とはファイルに含まれる単語ごとの出現回数を分散処理でカウントするプログラムです。
本記事では Hadoop で王道の Java を使ったプログラミングと、僕みたいに Java が嫌いな人の逃げ先用の Python を使ったプログラミングの2種類を紹介します。
【Java】Hadoop MapReduce で WordCount を実装
Mapreduce を利用した WordCount の実装は、以下の Apache Hadoop 公式チュートリアルに従います。

事前準備
WordCount プログラムでカウントする用のファイルを分散ファイルシステムに配置
前章の put オプションの説明を参考に WordCount でカウントする用のファイルを分散ファイルシステムに配置する
Hello World Bye World
Hello Hadoop Goodbye Hadoop
ソースコードを配置するディレクトリを作成
Gradle をインストール
以下を参考に Gradle をインストールします。(自分で依存関係を解決できる場合は不要です。)

WordCount プログラムを作成
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}WordCount プログラムをコンパイル
コンパイル用のビルドスクリプトを作成します。
plugins {
id 'java'
}
archivesBaseName = 'wc'
//リポジトリの設定
repositories {
mavenCentral() //https://repo.maven.apache.org/maven2/ から取得
}
//リポジトリから取得するモジュールの設定
dependencies {
compile group: 'org.apache.hadoop', name: 'hadoop-common', version: '3.3.0'
compile group: 'org.apache.hadoop', name: 'hadoop-mapreduce-client-core', version: '3.3.0'
}
WordCount プログラムをコンパイルします。
build/libs/wc.jar
WordCount を実行
ポートのエラーが出た場合は、メッセージに記載されたポートを開けてください。以下のエラーが出た場合はメモリ不足なので実行環境のスペックを上げてください。
There is insufficient memory for the Java Runtime Environment to continue.
Found 4 items -rw-r--r-- 1 hadoop hadoop 0 2020-11-24 15:08 /user/hadoop/output/_SUCCESS -rw-r--r-- 1 hadoop hadoop 8 2020-11-24 15:08 /user/hadoop/output/part-r-00000 -rw-r--r-- 1 hadoop hadoop 16 2020-11-24 15:08 /user/hadoop/output/part-r-00001 -rw-r--r-- 1 hadoop hadoop 17 2020-11-24 15:08 /user/hadoop/output/part-r-00002
私の環境では3ノードで実行したため、3つのファイルが作成されていることが確認できました。
正しく単語がカウントできていることを確認
part-r-0000* の内容を見ると、file01 と file02 に含まれる単語が正しくカウントできていることがわかります。
Hello 2 Bye 1 Goodbye 1 Hadoop 2 World 2
Hello World Bye World
Hello Hadoop Goodbye Hadoop
処理を分散していることを確認
各ファイルを確認するとノードごとにカウントするワードを手分けすることで処理を分散していることがわかります。
Hello 2
Bye 1 Goodbye 1
Hadoop 2 World 2
【Python】 Hadoop MapReduce で WordCount を実装
MapReduce を Java 以外の言語で使用する場合は、Hadoop Streaming というユーティリティを使用します。
Hadoop Streaming では mappers, reducers に実行可能ファイルを指定すると、指定したファイルを起動して map, reduce 処理を行います。つまり python ファイルを指定すれば python ファイルで MapReduce 処理が行えます。
Hadoop Streaming を利用した WordCount の実装は以下の Apache Hadoop 公式チュートリアルに従っています。

事前準備
WordCount プログラムを作成
#!/usr/bin/python3
import sys
def generateLongCountToken(id):
return "LongValueSum:" + id + "\t" + "1"
def main(argv):
line = sys.stdin.readline() #-input オプションで指定したディレクトリにあるファイルから1行ずつ読む
try:
while line:
line = line[:-1]
fields = line.split(" ") #空白区切りで単語を区切る
for word in fields:
print(generateLongCountToken(word)) #["LongValueSum:" + 単語 + "\t" + "1"] の形で出力
line = sys.stdin.readline()
except "end of file":#ファイルが終わるまで
return None
if __name__ == "__main__":
main(sys.argv)
Hadoop Streaming で WordCount プログラムを実行
端末上で下記のコマンドを入力します。 mapper には先程作成したプログラム、reducer には aggregate を指定します。
mapred streaming \ -input myInputDirs \ -output myOutputDir \ -mapper myAggregatorForKeyCount.py \ -reducer aggregate \ -file myAggregatorForKeyCount.py
MapReduce で WordCount 処理が成功した場合は以下のようなファイルが作成されます。
Found 2 items -rw-r--r-- 1 ec2-user supergroup 0 2020-11-26 14:05 /user/ec2-user/myOutputDir/_SUCCESS -rw-r--r-- 1 ec2-user supergroup 41 2020-11-26 14:05 /user/ec2-user/myOutputDir/part-00000
part-0000*は Hadoop のノードの数だけ作成されます。(処理が分散されるため)
Bye 1 Goodbye 1 Hadoop 2 Hello 2 World 2
インプットしたファイルは以下のとおりのため、単語ごとに正しく出現回数をカウントできていることがわかります。
Hello World Bye World Hello Hadoop Goodbye Hadoop
関連記事
ビッグデータ分析基盤入門シリーズの続きは以下です。
- 【ビッグデータ入門1】ビッグデータ分析基盤
- 【ビッグデータ入門2】ストリーム処理
- 【ビッグデータ入門3】fluentd
- 【ビッグデータ入門4】Elasticsearch
- 【ビッグデータ入門5】Apache Kafka
- 【ビッグデータ入門6】Apache Hadoop
- 【ビッグデータ入門7】Apache Spark
- 【ビッグデータ入門8】Apache Hive
参考サイト
本記事を記載するにあたり、下記のサイト、書籍を参考にしました。
公式ドキュメント
