
ビッグデータの分析基盤、機械学習を導入するにあたり、「ストリーム処理」という言葉をよく目にするようになりました。
一方で「ストリーム処理」に関する説明が抽象的でイメージが掴みにくいのが実情です。
そこで今回は以下の項目について「ストリーム処理」を説明したいと思います。
- ストリーム処理とはなんなのか?
- バッチ処理と何が違うのか?
- 具体的にどんなことができるのか?
- どんなOSSやサービスでストリーム処理を実現するか?
最初に
本記事は以下の書籍を参考にしています。
本記事は、以下のビッグデータ分析基盤シリーズの「ストリーム処理」編です。
- 【ビッグデータ入門1】ビッグデータ分析基盤
- 【ビッグデータ入門2】ストリーム処理
- 【ビッグデータ入門3】fluentd
- 【ビッグデータ入門4】Elasticsearch
- 【ビッグデータ入門5】Apache Kafka
- 【ビッグデータ入門6】Apache Hadoop
- 【ビッグデータ入門7】Apache Spark
- 【ビッグデータ入門8】Apache Hive
ストリーム処理とは
ストリーム処理とは、ストリーミングデータ(時間の経過とともに無限に発生するデータ)をリアルタイムで継続処理することです。
例えば、ベルトコンベアーを流れるTシャツに対して、センサーを使って色ごとに分別してダンボールに詰める場合を考えます。
この場合、「ストリーミングデータ」と「ストリーム処理」はそれぞれ以下のとおりです。
- ストリーミングデータ:センサーが送信する T シャツの画像
- ストリーム処理:センサーから受信した T シャツの画像を元に AI がリアルタイムで色を判断
ストリーム処理 VS バッチ処理
ここでは、ストリーム処理とバッチ処理を比較することでストリーム処理の特性を理解します。
ストリーム処理とバッチ処理の違いは、時間軸の違いです。
| ストリーム処理 | バッチ処理 | |
|---|---|---|
| 目的 | リアルタイム重視 | スループット重視 |
| 処理するタイミング | ストリーミングデータが発生した時 | ハードウェアリソースが余った時 |
| 処理にかかる時間 | 数ミリ秒〜数秒 | 数分〜数時間 |
| ユースケース | クレジットカードの不正検出 ゲームのリアルタイム世界ランキング IoT デバイスデータの分析 |
夜間バッチ 店舗の月次処理 |
ユースケースを見てわかるように、ストリーム処理では時間の経過に伴って無限に発生するデータをリアルタイムで処理した場合に利用します。
例えば、クレジットカードの不正利用は1秒でも速く検知して、使用を止めたいですよね。翌月までに検知など悠長なことは言ってられないです。
ストリーミングデータとは
ストリーミングデータとは、無限のデータセットのことです。ここで言う無限とは、時間の経過とともに、新しいレコードが届き続けることを指します。
なお、ストリーミングデータは、「イベントストリーム」や「データストリーム」とも呼ばれます。
ストリーミングデータは無限という性質以外に、以下の3つ特性を持ちます。
- 順序付けされている
- イミュータブル(変更不可能)なデータレコード
- 再生可能 ※(※あると望ましい特性)
順序付けされている
イベント(ストリーミングデータの各レコード)には順序があります。
例えば、イベント1「給料 20 万円の振り込み」、イベント2「5 万円の引き出し」には順序があります。残高 0 円の口座の場合、イベント2が先に処理された場合は残高不足となってしまいます。
イミュータブル(変更不可能)なデータレコード
イベントは1度発生すると削除、変更できません。
例えば、イベント「5 万円の引き出し」を後から削除、変更することはできません。このイベントをキャンセル場合は、新しいイベント「5 万円を預け入れ」を実行します。
再生可能
順序付けされていて、イミュータブルなデータレコードのため、ストリーミングデータは再現可能です。
例えば、以下のイベントリストでは、現在の残高を求めることはもちろん、ある時点での残高を求めることも可能です。
イベント1「残高 0 円で口座開設」 イベント2「5 万円を預け入れ」 イベント3「10 万円を預け入れ」 イベント4「5 万円の引き出し」 イベント5「5 万円を預け入れ」 イベント6「10 万円の引き出し」
なお、イベントリストから、過去のある状態のデータを再現することをマテリアライズと言います。イベント4終了時点での「残高データ」をマテリアライズすると「10万円」となります。
ストリーム処理における時間の概念
ストリーム処理では、時間をベースにしてストリーミングデータを処理を可能なため、正確な時間概念を定義することが重要です。ストリーム処理では以下の3つの時間の概念を利用します。
- イベント時間 (Event Time)
- 取り込み時間 (Ingest Time)
- 処理時間 (Processing Time)
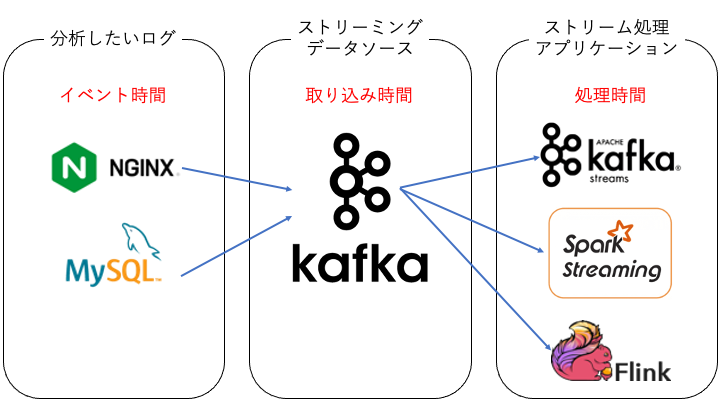
イベント時間 (Event Time)
イベント時間は、イベントが発生した際にレコードを作成した時刻です。
イベント時間は、ストリーミングデータを分析するために利用します。
- Web サイトにアクセスする時間のピーク
- 時間ごとに売上が伸びる商品の種類
取り込み時間 (Ingest Time)
取り込み時間は、イベントがストリーミングデータソースに到着した時刻です。
ストリーム処理ではリアルタイムに処理を行うため、通常「イベント時間」と「取り込み時間」はほぼ同じです。
ネットワーク障害等により、データの到着に遅延が発生した場合に「イベント時間」と「取り込み時間」は乖離します。
処理時間 (Processing Time)
処理時間は、ストリーム処理アプリケーションで実際に処理した時刻です。
「処理時間」と「取り込み時間」に大きな乖離がある場合は、アプリケーション側でストリーム処理が間に合っていない可能性があります。
タイムウィンドウ
ストリーム処理では、ストリーミングデータに対して、時間ベースでウィンドウ操作することが可能です。
ウィンドウ操作とは、制限した範囲のレコードごとに操作することです。この制限した範囲のことをウィンドウサイズと呼びます。
タイムウィンドウでは、時間をベースにウィンドウサイズを決定します。(10 秒ごとに、溜まったレコードを処理する等)
タイムウィンドウのタイプには、ウィンドウの移動頻度(前進間隔)によって主に以下の3種類があります。
| ウィンドウの移動頻度(前進間隔) | 処理の重複 | |
|---|---|---|
| タンブリングウィンドウ | ウィンドウサイズと同じ | しない |
| ホッピングウィンドウ | ウィンドウサイズより小さい | する |
| スライディングウィンドウ | ウィンドウ内にあるイベントが変化する度 | することもある |
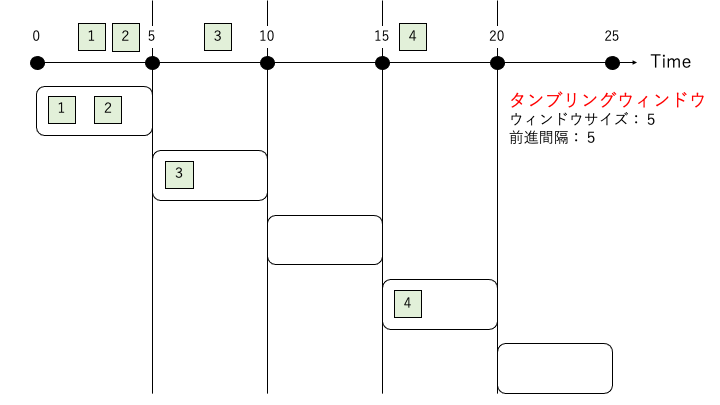
タンブリングウィンドウ
「前進間隔」 = 「ウィンドウサイズ」となるウィンドウタイプです。
イベントに対する処理が重複しない特徴を持ちます。
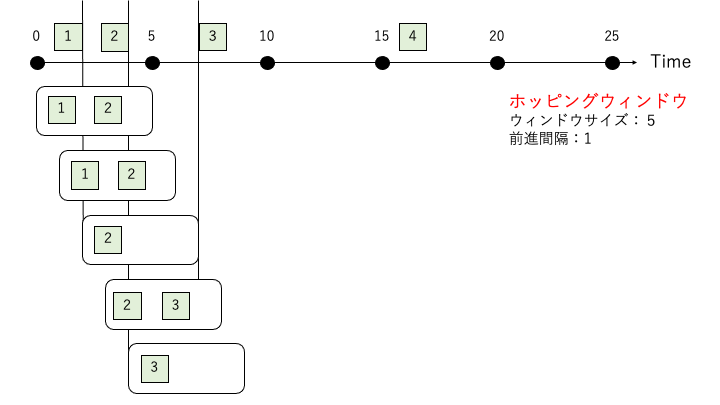
ホッピングウィンドウ
「前進間隔」 < 「ウィンドウサイズ」となるウィンドウタイプです。
イベントに対する処理が重複する特徴を持ちます。
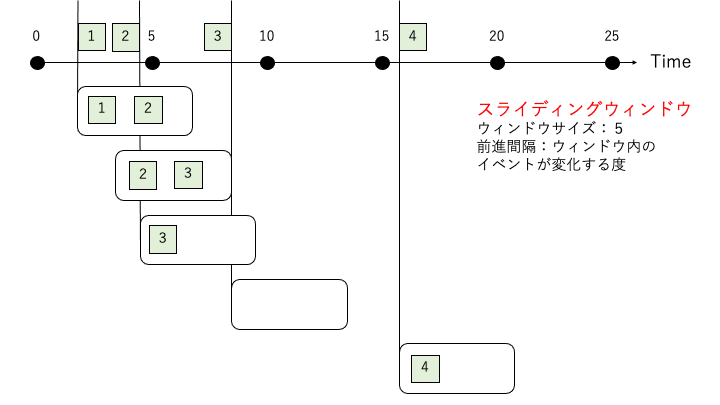
スライディングウィンドウ
「前進間隔」 = 「ウィンドウ内にあるイベントが変化する時」となるウィンドウタイプです。
ウィンドウ内にあるイベントが変化しない時、何も処理を実行しません。(SQL クエリの場合、結果を出力しません。)
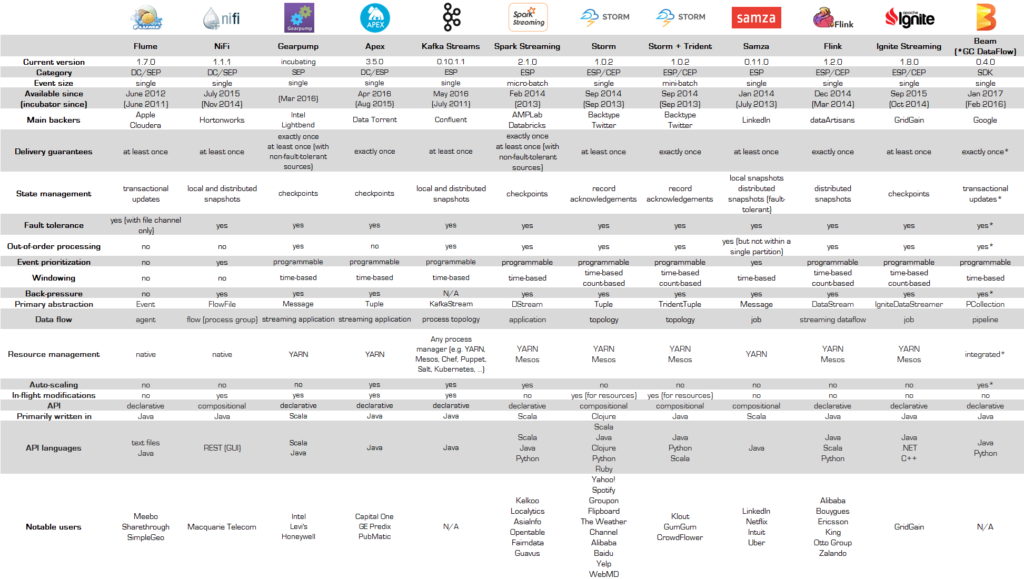
ストリーム処理を実現する OSS やサービス
ストリーム処理は、以下の2つを用いて実現します。
- 分散ストリーミングデータソース(イベントをキューイングするデータソース)
- 分散ストリーム処理アプリケーション(キューのイベントにストリーム処理を実施)
分散ストリーミングデータソース
分散ストリーミングデータソースでは、主に以下の Pub/Sub メッセージングキューを利用します。
- Apache Kafka
- Amazon Kinesis Data Streams
分散ストリーミングデータソースとして Apache Kafka を利用する場合は以下の記事をご覧ください。

分散ストリーム処理アプリケーションで利用するエンジン
分散ストリーム処理アプリケーションでは、主に以下の分散処理エンジンを利用します。
- Kafka Streams(Apache Kafka の Streams API)
- Kinesis Data Analytics
- Apache Flink
- Apache Spark Streaming
- Apache Storm
- Apache Samza
企業におけるストリーム処理の事例
ストリーム処理(Apache Kafka + Kafka Streams)を企業で使用した例を載せます。
- LINE社: 大規模Kafkaプラットフォームの裏側
- Disney+ Hotstar社: Explosive Growth with Real-Time Event Streaming on Confluent Platform
- Cerner社: 大手ヘルスケアIT企業 Cerner社のKafka活用事例
- Bosch社: Tools Streams IoT Data with Confluent Cloud
関連記事
ビッグデータ分析基盤入門シリーズの続きは以下です。
- 【ビッグデータ入門1】ビッグデータ分析基盤
- 【ビッグデータ入門2】ストリーム処理
- 【ビッグデータ入門3】fluentd
- 【ビッグデータ入門4】Elasticsearch
- 【ビッグデータ入門5】Apache Kafka
- 【ビッグデータ入門6】Apache Hadoop
- 【ビッグデータ入門7】Apache Spark
- 【ビッグデータ入門8】Apache Hive