
Apache Kafka を学習する上で以下のような疑問が生まれたため、本記事にまとめました。
- どんなことができるの?分散ストリーミング処理システムって何?
- そもそも何に使うのこれ?メッセージキューイングシステムでよくない?
- どうやって使うの?
初めに
本記事は以下の書籍を参考にしています。
本記事は、以下のビッグデータ分析基盤シリーズの Apache Kafka 編です。
- 【ビッグデータ入門1】ビッグデータ分析基盤
- 【ビッグデータ入門2】ストリーム処理
- 【ビッグデータ入門3】fluentd
- 【ビッグデータ入門4】Elasticsearch
- 【ビッグデータ入門5】Apache Kafka
- 【ビッグデータ入門6】Apache Hadoop
- 【ビッグデータ入門7】Apache Spark
- 【ビッグデータ入門8】Apache Hive
Apache Kafka とは
Apache Kafka とは、分散 Publish/Subscribe メッセージングシステムです。
Publish/Subscribe メッセージングシステムとは
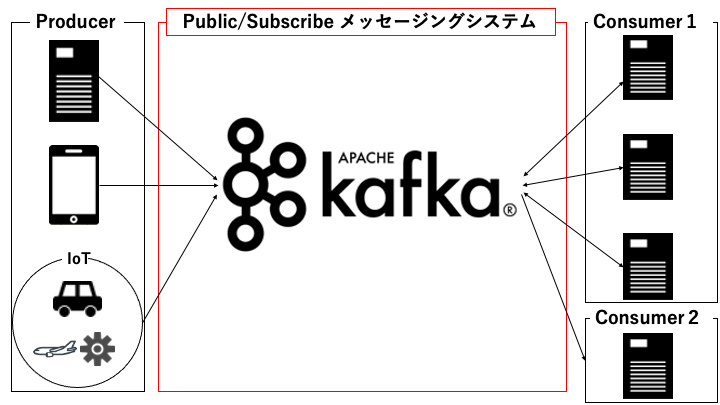
Publish/Subscribe メッセージングシステムとは、Publisher(送信側)から送信したメッセージ(順序付けられた文字列)を、非同期的に Subscriber(受信側)が受信可能なシステムです。
要はメッセージをソースからターゲットに集約するシステムです。
データ収集がビッグデータ分析の上でどの工程に位置するかについては以下の記事をご覧ください。

Publish/Subscribe 型のシステムでは、以下の用語はだいたい同じ意味だと理解してください。
- メッセージの生成(送信)側
- Publisher
- Producer (Kafka ではこの用語を使います)
- Writer
- メッセージの消費(受信)側
- Subscriber
- Consumer (Kafka ではこの用語を使います)
- Reader
メッセージキューイングシステム と何が違うの?
メッセージキューイングシステムとの違いは以下のとおりです。
| Publish/Subscribe メッセージングシステム | メッセージキューイングシステム | |
|---|---|---|
| メッセージの消費 | 複数回可能(Producer はメッセージを1回送信すればよい) | 1回のみ(Producer はメッセージを消費する回数だけ送信する必要がある) |
fluentd と何が違うの?
fluentd の詳細は以下をご覧ください。
以下のように Kafka は fluentd と比較して信頼性の高いシステムとなります。
| Kafka(分散 Pub/Sub メッセージングシステム) | fluentd | |
|---|---|---|
| Semantics | Exactly Once(1回だけ) | At Least Once(少なくとも1回。重複を許す) |
| キューイング機能 | あり(時間的制約の分離が可能) | なし |
| 冗長性 | あり(分散保存により故障耐性あり) | なし |
以下のように1つの fluentd にデータを集約する場合、Kafka を挟むことで「時間的制約の分離」と「冗長性」を確保できます。
この時 fluentd の役割は以下のとおりです。
分散Publish/Subscribe メッセージングシステムのメリット
Publish/Subscribe メッセージングシステムを初めて知った感想は以下のとおりでした。
「Producer 側から Consumer 側に直接メッセージを送ればよくない?1箇所に集めたら何が良いんだ??」
そこでまずは Publish/Subscribe メッセージングをなんのために利用するか説明します。
メリット1:メッセージを中央集中管理可能
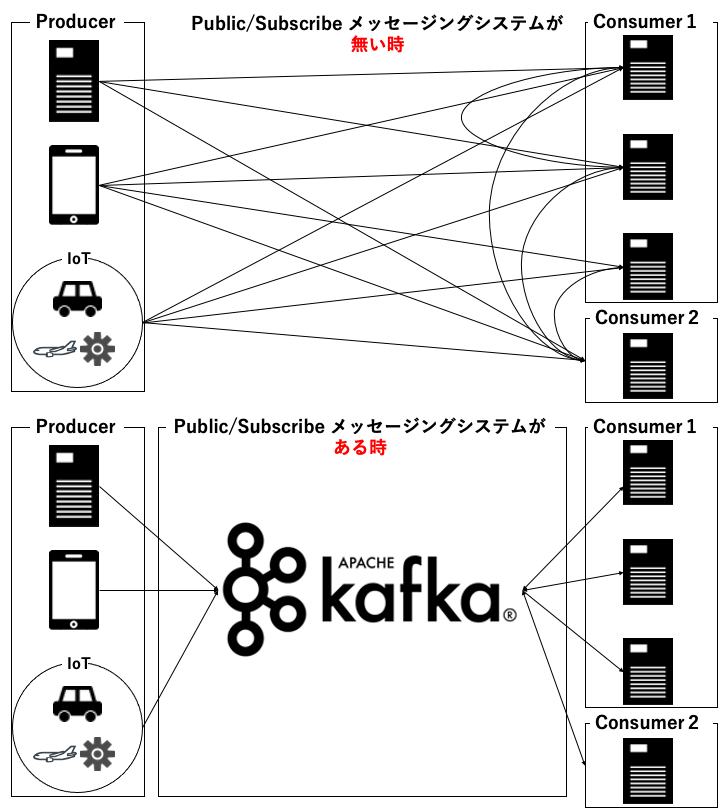
下記の図のようにメッセージを中央集中管理できるため、以下のような問題を解決できます。
- その ETL 機能って A 部署でも B 部署でも重複して開発しててもったいないよね
- あのデータは誰が持っている?
- 加工後のデータはどこに渡せばいい?
メリット2:Producer の追加、削除が容易
Producer 側で既存の Consumer を1つ1つ探し、メッセージを送信する必要もありません。1つの Publish/Subscribe メッセージングシステムにメッセージを送信するだけです。
具体例を見る(Producer を追加する)
例えば、以下のようなシステムが存在したとします。
- Producer: Web サイトAのログ、ショッピングサービスのログ
- Consumer: モニタリング、機械学習、データベース
この時、「チャットサービス」のログでもモニタリング、機械学習、分析を利用したくなったとします。そのため、Producer に「チャットサービス」を追加します。
■Publish/Subscribe メッセージングシステムが存在しない場合
「チャットサービス」はモニタリング、機械学習、分析(複数箇所)にログを送信するように実装する必要があります。
■Publish/Subscribe メッセージングシステムが存在する場合
「チャットサービス」は Publish/Subscribe メッセージングシステム(1箇所)にログを送信するだけOKです。
メリット3:Consumer の追加、削除が容易
先程と似ていますが、Consumer を新しく追加しても、既存の Producer のメッセージ送信先を変更する必要がありません。
具体例を見る(Consumer を追加する)
例えば、開発部署に以下のようなシステムが存在したとします。
- Producer: Web サイトA, ショッピングサービス, チャットサービスのログ
- Consumer: モニタリング、機械学習、データベース
この時、営業部署でマーケティング調査のために、「分析システム」で Web サイトAのログ, チャットサービスのログを利用したくなりました。そのため、「分析システム」を Consumer に追加します。
■Publish/Subscribe メッセージングシステムが存在しない場合
Web サイトA、ショッピングサービス、チャットサービス(Producer)は、新しく「分析システム」にメッセージを送信するように変更する必要があります。
■Publish/Subscribe メッセージングシステムが存在する場合
Web サイトA、チャットサービス(Producer)は、既に Publish/Subscribe メッセージングシステムにメッセージを送信しているため、「分析システム」のために Producer の処理を変更する必要はありません。
メリット4:時間的制約を分離するバッファとして利用可能
ピーク時に Consumer 側の処理が間に合わない場合は、Publish/Subscribe メッセージングシステムにメッセージを一時的に保管することができます。
具体例を見る(時間的制約を分離するバッファ)
例えば以下のようなシステムを例に考えます。
- お客様がネット通販で注文した商品を Producer が Publish/Subscribe メッセージングシステムに送信
- Consumer が Publish/Subscribe メッセージングシステムからお客様の注文した商品を取得し、発送準備を行う
上記のシステムでは Producer 側と Consumer 側で以下のように時間的制約が異なります。
- Publisher 側は可能な限り早い応答が求められる
- 注文ボタンをクリックしてから、画面遷移に20秒待たされるシステムは論外だろう
- Subscribe 側の発送準備はある程度の遅延は許容される
- 通常5秒で終わる発送準備が、10分後に発送準備が完了したところでブチ切れるお客様は少ないはず
そのため、Publisher 側と Subscribe 側の時間的制約を分離するバッファとして 以下のように Publish/Subscribe メッセージングシステム利用します。
- Publish/Subscribe メッセージングシステムに保存した時点で Producer 側で注文完了画面を表示します
- Consumer 側は Publish/Subscribe メッセージングシステムのメッセージを消費して淡々と発送準備をします(ピーク時刻を過ぎると徐々に処理が追いついてきます。)
メリット5:データの冗長性を確保
分散 Publish/Subscribe メッセージングシステムでは、複数のノードにレプリケートされます。そのため、1台のノードが障害でダウンした場合でも、データを失うことはありません。
Apache Kafka の企業での事例
Apache Kafka が企業でどのように使われているのか調査している人のために、事例を掲載します。
- LINE社: 大規模Kafkaプラットフォームの裏側
- Disney+ Hotstar社: Explosive Growth with Real-Time Event Streaming on Confluent Platform
- Cerner社: 大手ヘルスケアIT企業 Cerner社のKafka活用事例
- Bosch社: Tools Streams IoT Data with Confluent Cloud
分散ストリーミングプラットフォーム
Apache Kafka は「分散ストリーミングプラットフォーム」と呼ばれることもあります。
分散ストリーミングプラットフォームは明確な定義はありませんが、一般的には以下の2つから構成されるシステムと言われています。
- 分散データストリームのソース(Publish/Subscribe メッセージングシステム)
- 分散ストリーム処理
例: 分散データストリームのソース
主に以下のソフトウェアやサービスが分散データストリームのソースを提供します。
- Apache Kafka
- Amazon Kinesis Data Streams
例:分散ストリーム処理
主に以下のソフトウェアやサービスが分散ストリーム処理を提供します。
- Kafka Streams(Apache Kafka の Streams API)
- Kinesis Data Analytics
- Apache Flink
- Apache Spark Streaming
- Apache Storm
- Apache Samza
分散ストリーム処理については、以下の記事にまとめました。
Apache Kafka の用語と構成
ここでは Apache Kafka の用語と構成について説明します。
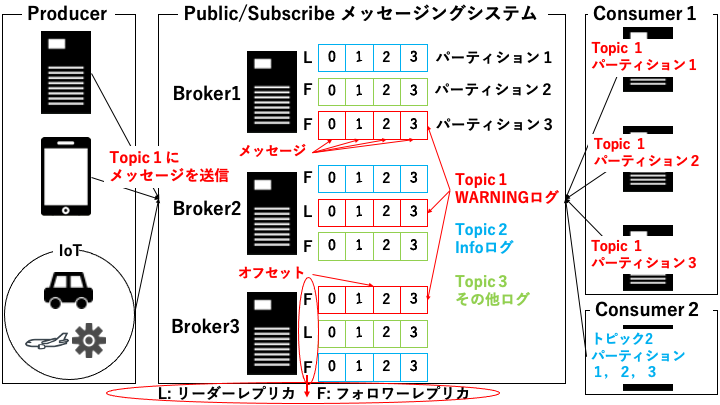
メッセージ
Publish/Subscribe メッセージングシステムで利用するメッセージはバイト列です。アプリケーションログなどをメッセージとして Publish/Subscribe メッセージングシステムに送信したり、消費したりします。
シリアライズ
送信するログなどをバイト列に変換することです。上述のとおり、メッセージはバイト列である必要があります。
デシリアライズ
消費するバイト列を元のデータに変換することです。上述のとおり、消費するメッセージはバイト列なので必要に応じて元のデータに戻します。
Broker
Broker は Publish/Subscribe メッセージングシステムが稼働する 1 台のサーバーです。Publish/Subscribe メッセージングシステムは複数の Broker から構成されるクラスターです。
パーティション
パーティションは Broker 内に存在するメッセージを書き込む場所です。メッセージはパーティションの先頭から書き込まれ、パーティション内の順序が保証されます。パーティションは別々の Broker に配置することも可能です。
リーダーレプリカ
パーティションの種類の1つです。Producer と Consumer のリクエストはリーダーレプリカを使用します。リーダーレプリカは各パーティションに1つだけ存在します。
フォロワーレプリカ
パーティションの種類の1つです。メッセージを複製し、バックアップを取ることを目的としているパーティションで、Producer と Consumer のリクエストに応答しません。フォロワーレプリカは各パーティションで複数作成することが可能です。
Topic:
パーティションの集合です。つまり Topic を使用して、複数のコンピュータに処理を分散させたり、データをレプリケーションします。
Producer
メッセージを送信する側のクライアントです。Producer は Topic を指定してメッセージを送信します。Topic は、パーティションキーのハッシュ値を元にメッセージを保存するパーティションを決定します。
Consumer
メッセージを消費する側のクライアントです。Consumer は Topic とパーティションを指定することでメッセージを消費します。
オフセット
Consumer がパーティションをどこまで消費したのか記録した値です。Consumer が死んだ時、新しく割り当てられた Consumer は前回の続きからデータを読むことができます。
Apache Kafka を Docker で起動
初めに、そもそも Docker って何?という方は以下の記事をご覧ください。

本章では、以下の Dockerfile を利用して、Apache Kafka を起動します。
Docker でインストール
以下の手順で、Docker を利用して Apache Kafka をインストールします。
Docker コンテナを起動
以下の手順で Apache Kafka の Docker コンテナを起動します。
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
61b3be864cc0 kafkadocker_kafka "start-kafka.sh" About a minute ago Up About a minute 0.0.0.0:32768->9092/tcp kafkadocker_kafka_1 e9f856980452 wurstmeister/zookeeper "/bin/sh -c '/usr/sb…" 30 hours ago Up About a minute 22/tcp, 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp kafkadocker_zookeeper_1
docker_kafka_1 が起動しない場合
メモリが不足している可能性があります。
docker-compose のログに以下のログが残っている場合はメモリ不足です。
kafka_1 | # There is insufficient memory for the Java Runtime Environment to continue.
Apache Kafka の使い方
次の2つの方法で Apache Kafka を実際に操作してみます。
なお、紹介する操作は以下の3つです。
- Topic を作成(Python ではライブラリが自動生成するため省略)
- Producer でメッセージを送信
- Consumer でメッセージを消費
Apache Kafka を CLI で操作
ここでは、CLI を利用した Apache Kafka の操作方法を紹介します。
Topic を作成・確認
以下の Topic を作成します。
- パーティションを3つ (Broker の数に依存しない。1つの Broker に複数作成可能)
- レプリカを3つ (Broker の数までしか作成できない)
- リーダーレプリカ1つ
- フォロワーレプリカ2つ
kafka に認証が必要な場合 (--command-config)
「--command-config <認証用のプロパティのパス>」オプションを使います。
security.protocol=SASL_SSL sasl.mechanism=AWS_MSK_IAM sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required; sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
$BOOTSTRAP_SERVER はブートストラップサーバーのエンドポイントです。
topicCLI
Topic: topicCLI PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824 Topic: topicCLI Partition: 0 Leader: 1002 Replicas: 1002,1001,1003 Isr: 1002,1001,1003 Topic: topicCLI Partition: 1 Leader: 1001 Replicas: 1001,1003,1002 Isr: 1001,1003,1002 Topic: topicCLI Partition: 2 Leader: 1003 Replicas: 1003,1002,1001 Isr: 1003,1002,1001
以下の情報が確認できます。
- パーティションが3つ (PartitionCount: 3)
- レプリカが3つ (ReplicationFactor: 3)
- うち1つはリーダーレプリカ (Leader: 1001 等)
Producer で Topic にメッセージを生成 (送信)
kafka に認証が必要な場合 (--producer.config)
「--producer.config <認証用のプロパティのパス>」オプションを使います。
security.protocol=SASL_SSL sasl.mechanism=AWS_MSK_IAM sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required; sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
$BOOTSTRAP_SERVER はブートストラップサーバーのエンドポイントです。
この状態で何か文字を入力し、Enter ボタンを押すと Kafka の TopicCLI Topic にメッセージが生成 (送信) されます。
>aaa >bbb
Consumer で Topic からメッセージを消費 (受信)
別の端末で Consumer を起動します。
aaa bbb
kafka に認証が必要な場合 (--consumer.config)
「--consumer.config <認証用のプロパティのパス>」オプションを使います。
security.protocol=SASL_SSL sasl.mechanism=AWS_MSK_IAM sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required; sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
$BOOTSTRAP_SERVER はブートストラップサーバーのエンドポイントです。
先程 TopicCLI Topic に生成 (送信) したメッセージが消費 (受信)できることが確認できました。
Topic の削除
Topic 削除したい場合は以下の方法で可能です。
Apache Kafka を Python で操作
Python 用の Kafka ライブラリ(kafka-python)をインストール
kafka-python API の使い方は以下のドキュメントに記載されています。

Broker のポートを確認
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES aea5c79aa493 kafkadocker_kafka "start-kafka.sh" 26 hours ago Up 26 hours 0.0.0.0:32774->9092/tcp kafkadocker_kafka_3 2fa6f42900b3 kafkadocker_kafka "start-kafka.sh" 26 hours ago Up 26 hours 0.0.0.0:32773->9092/tcp kafkadocker_kafka_2 e9f856980452 wurstmeister/zookeeper "/bin/sh -c '/usr/sb…" 27 hours ago Up 27 hours 22/tcp, 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp kafkadocker_zookeeper_1 f8651c16205c kafkadocker_kafka "start-kafka.sh" 27 hours ago Up 27 hours 0.0.0.0:32772->9092/tcp kafkadocker_kafka_1
今回の場合、Broker のポートが 32772, 32773, 32774 であることがわかります。
Producer で Topic にメッセージを送信
Python で Producer を作成します。なお、赤線箇所は Broker のポート番号に修正してください。(複数の Broker を起動している場合はどれか1つを選択してください)
from time import sleep
from json import dumps
from kafka import KafkaProducer
#producer の設定
producer = KafkaProducer(
bootstrap_servers=['localhost:32772'],#Kafka Broker ホスト
value_serializer=lambda x: dumps(x).encode('utf-8') #シリアライズ
)
#トピックにメッセージを送信
for j in range(1000):
message = {'testProduceData': j}
producer.send('topicPython', value=message)#トピック名と送信メッセージを指定
print(message)
sleep(0.5)
producer.send を利用してトピックにメッセージを送信します。もし、Topic が存在していない場合は、自動生成されるようです。
Consumer で Topic からメッセージを消費
Python で Consumer を作成します。なお、赤線箇所は Broker のポート番号に修正してください。
from kafka import KafkaConsumer
from json import loads
from time import sleep
#consumer の設定
consumer = KafkaConsumer(
'topicPython',#トピック名
bootstrap_servers=['localhost:32772'],#Kafka Broker ホスト
auto_offset_reset='earliest',#オフセットを一番最初から
value_deserializer=lambda x: loads(x.decode('utf-8'))#デシリアライズ
)
#消費したメッセージを画面に表示
for event in consumer:
event_message = event.value
print(event_message)
sleep(0.5)
Producer と Consumer を実行
2つの端末で Producer と Consumer をそれぞれ実行します。
1つ目の端末で Producer を実行します。
{'testProduceData': 0}
{'testProduceData': 1}
{'testProduceData': 2}
{'testProduceData': 3}
2つ目の端末で Consumer を実行します。
{'testProduceData': 0}
{'testProduceData': 1}
{'testProduceData': 2}
{'testProduceData': 3}
Producer 側で Topic に送信したメッセージが Consumer 側で消費できていることがわかります。
関連記事
ビッグデータ分析基盤入門シリーズの続きは以下です。
- 【ビッグデータ入門1】ビッグデータ分析基盤
- 【ビッグデータ入門2】ストリーム処理
- 【ビッグデータ入門3】fluentd
- 【ビッグデータ入門4】Elasticsearch
- 【ビッグデータ入門5】Apache Kafka
- 【ビッグデータ入門6】Apache Hadoop
- 【ビッグデータ入門7】Apache Spark
- 【ビッグデータ入門8】Apache Hive
参考ドキュメント
公式ドキュメント
