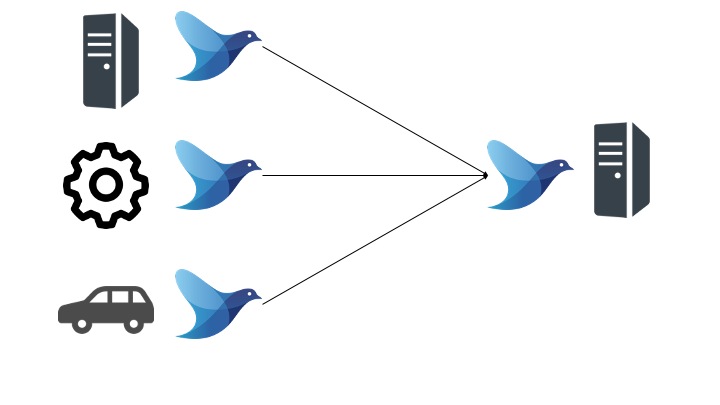
アプリケーションや各 IoT 機器のログを1箇所に集約するために利用します。
初めに
本記事は、以下のビッグデータ分析基盤シリーズの fluentd 編です。
- 【ビッグデータ入門1】ビッグデータ分析基盤
- 【ビッグデータ入門2】ストリーム処理
- 【ビッグデータ入門3】fluentd
- 【ビッグデータ入門4】Elasticsearch
- 【ビッグデータ入門5】Apache Kafka
- 【ビッグデータ入門6】Apache Hadoop
- 【ビッグデータ入門7】Apache Spark
- 【ビッグデータ入門8】Apache Hive
td-agent と fluentd の違い
td-agent は fluentd の安定版です。
Fluentd は Ruby で作成されており、Ruby に起因するインストールやオペレーションの問題が発生する場合がありますが、td-agent では Ruby に起因する問題を回避します。
Fluentd is written in Ruby for flexibility, with performance-sensitive parts in C. However, some users may have difficulty installing and operating a Ruby daemon.
https://docs.fluentd.org/installation/install-by-rpm
That is why Treasure Data, Inc provides the stable distribution of Fluentd, called td-agent. The differences between Fluentd and td-agent can be found here.
Apache Kafka と Fluentd の違い
似たようなソフトウェアに Apache Kafka が存在します。
Apache Kafka の詳細について知りたい方は以下の記事をどうぞ

Apache Kafka と fluentd の違い
Apache Kafka と fluentd の違いは以下のとおりです。
| 一貫性 | 冗長性 | キューイング機能 | |
|---|---|---|---|
| fluentd | At Least Once | なし | なし |
| Apache Kafka | Exactly Once | あり 複数ノードでレプリカを持つ |
あり |
冗長性
消えては困るデータを利用する場合には、Kafka を利用します。
分析用途の場合は、一部のデータが欠落しても大きな問題とはなりにくいため、実装がかんたんな fluentd を利用します。
キューイング機能
以下の状況では、キューイング機能を持った Apache Kafka を利用します。
fluentd(td-agent)のインストール
以下の手順で td-agent をインストールします。
- fluentd(td-agent)をインストール
- インストールした td-agent を起動
fluentd (td-agent) をインストール
Amazon Linux2 の場合
RHEL / CentOS の場合
その他の OS の場合
以下の公式ドキュメントが詳しいので、そちらをご覧ください。
fluentd (td-agent)を起動
fluentd(td-agent)の使い方
ログの送信
デフォルトの設定では、HTTP を利用して以下のようにログを送信することが可能です。
なお、URL のパスで td-agent のタグを指定可能です。
ログの確認
2021-01-08 14:34:02.350601661 +0000 debug.test: {"json":"message"}
[時間・タグ・ログ] の順で格納されていることがわかります。
fluentd(td-agent)の設定
fluentd(td-agent)の設定ファイルのパスは以下です。
fluentd(td-agent)の設定ファイルでは、以下のディレクティブで構成されます。
sourceログの入力方法を決めるディレクティブmatchログの出力方法を決めるディレクティブfilterイベントプロセッシング(ログを加工する)ディレクティブsystemシステムにまたがって設定をするディレクティブlabelmatch と filter の内部ルーティングを決めるディレクティブ@include他のファイルを include するディレクティブ
各ディレクティブの使い方は公式ドキュメントが最もわかりやすいです。
本記事では、よく利用する source, match, filter, include について日本語で記載します。
source: ログの入力方法
source ディレクティブでは、@type で Input Plugin 等を指定することでログの入力方法を設定します。
Input Plugin 一覧
source ディレクティブで利用可能な Input Plugin の一覧は以下のとおりです。
in_tailin_forwardin_udpin_tcpin_unixin_httpin_syslogin_execin_samplein_windows_eventlog- Fluentd plugins(その他)
source ディレクティブの設定例
in_http プラグインを利用して HTTP エンドポイント + ポート 9888 でリッスンする場合の設定例を示します。
動作検証
2021-03-06 04:52:10.295233061 +0000 debug.test: {"port":"9888"}
match: ログの出力方法
match ディレクティブでは、@type で Output Plugin 等を指定することでログの出力方法を設定します。
Output Plugin 一覧
match ディレクティブで利用可能な Output Plugin の一覧は以下のとおりです。
out_copyout_nullout_roundrobinout_stdoutout_exec_filterout_forwardout_mongo/out_mongo_replsetout_execout_fileout_s3out_webhdfs
match ディレクティブの設定例
out_file プラグインを利用して myapp.access タグのメッセージを /var/log/td-agent/access にファイルとして出力する設定例を示します。
<match myapp.access> @type file path /var/log/td-agent/access </match>
動作検証
2021-03-06T05:19:58+00:00 myapp.access {"port":"9888"}
myapp.access タグを指定してメッセージを送信した場合、/var/log/td-agent/access ディレクトリにファイルが生成されることが確認できます。
filter: イベントプロセッシング(ログを加工)
filter ディレクティブでは、@type で Filter Plugin 等を指定することでログの加工方法を設定します。
Filter Plugins
Filter ディレクティブの設定例
record_transformer プラグインを利用して debug.* タグのメッセージを変更します。
<filter debug.**>
@type record_transformer
<record>
add_tag "addTagTest!!!!"
</record>
</filter>
動作検証
2021-03-08 08:27:00.014104156 +0000 debug.test: {"json":"message","add_tag":"addTagTest!!!!"}
入力レコード {"json":"message"} に、record_transformer の record ディレクティブで指定した "add_tag":"addTagTest!!!!" が追加されていることが確認できます。
@include: 他の設定ファイルをインクルード
@include ディレクティブでは、他の設定ファイルをインクルード可能です。
@include ディレクティブの設定例
/etc/td-agent/config.d 配下に存在する *.conf ファイルをすべて include するような設定は以下のとおりです。
@include config.d/*.conf
<match extra.**> @type stdout </match>
動作検証
2021-03-08 09:11:14.797642791 +0000 extra.test: {"extra":"test"}
extra.test タグを持つレコードが /var/log/td-agent/td-agent.log に出力されているため、インクルードした extra.conf の設定が反映されていることが確認できます。
関連記事
ビッグデータ分析基盤入門シリーズの続きは以下です。
- 【ビッグデータ入門1】ビッグデータ分析基盤
- 【ビッグデータ入門2】ストリーム処理
- 【ビッグデータ入門3】fluentd
- 【ビッグデータ入門4】Elasticsearch
- 【ビッグデータ入門5】Apache Kafka
- 【ビッグデータ入門6】Apache Hadoop
- 【ビッグデータ入門7】Apache Spark
- 【ビッグデータ入門8】Apache Hive
参考資料
公式ドキュメント