

| Elasticsearch & OpenSearch の使い方 | ||||
|---|---|---|---|---|





TF-IDF とは
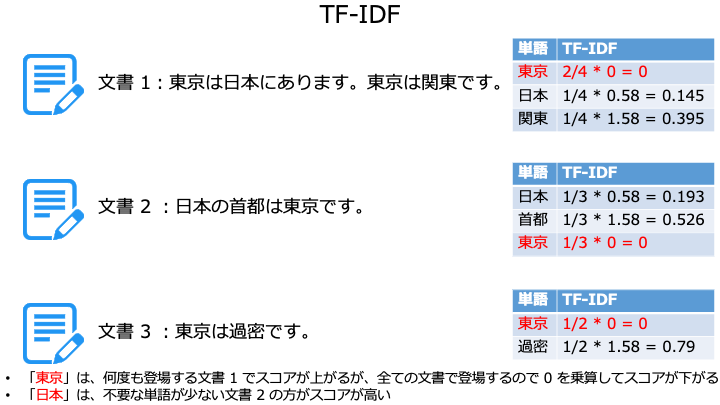
TF-IDF は、1つの文書に繰り返し登場する単語や、他の文書に無い単語を高く評価します。
TF-IDF は、「TF」と「IDF」と呼ばれる要素で構成されます。
つまり、同じ文書で何回も登場する単語が重要ということです。

TF の計算には色々な種類がありますが、今回はよく使う次の 2 つを紹介します。
- raw count
- 標準的な TF
TF 計算式 (raw count)
$$ tf(単語, 文書) = f(単語, 文書) $$
つまり、TF の raw count は、単語の数をそのまま数えます。

TF 計算式 (標準的な TF)
$$ tf(単語, 文書) = \frac{f(単語, 文書)}{文書に含まれる単語数} $$
つまり、標準的な TF は文書中に含まれる単語の割合を表します。

TF-IDF では、標準的な TF を利用します。
他の文書に含まれない単語が、その文書の特徴 (価値) となります。

IDF の計算には色々な種類がありますが、今回はよく使う次の 2 つを紹介します。
- 標準的な IDF
- 確率論的 IDF
IDF 計算式 (標準的な IDF)
$$ idf(単語) = log\frac{文書総数}{単語が含まれる文書数} $$

TF-IDF では、標準的な IDF を利用します。
IDF 計算式 (確率論的 IDF)
$$ idf(単語) = log\frac{文書総数 - 単語が含まれる文書数}{単語が含まれる文書数} $$

TF-IDF の計算式
$$ TF\text{-}IDF(単語, 文書) = tf(単語, 文書) * idf(単語) $$

TF-IDF は文書の単語数に強く影響を受けるため、単語の少ない文書ほどスコアが高くなります。
この問題を解決するために TF-IDF に変更を加えた Okapi BM25 が存在します。
Okapi BM25 とは
Okapi BM25 は Elasticsearch (OpenSearch) の検索アルゴリズムとしても利用されています。
Okapi BM25 は、TF と IDF を利用して文書にある単語の重要度を次の式で数値化します。
$$ \sum_{i}^{n}IDF(検索単語_i) * TF (検索単語_i, 文書)$$
TF を展開した計算式はこちら (一般的に BM25 と言えばこの式)
$$ \sum_{i}^{n}IDF(検索単語_i) \frac{f(文書にある検索単語_i数)*(k_1 +1)}{f(文書にある検索単語数_i) + k_1*(1-b+b*\frac{文書にある単語数}{全文書にある平均単語数})}$$
\(k_1, b\) の意味は後述します。
例えば、「東京 観光」と検索する場合は、i=1 が「東京」、i=2 が「観光」になります。
ただし、Olapi BM25 は、TF-IDF と IDF, TF の計算式が異なります。
Okapi BM25 の TF の計算式
Okapi BM25 の TF は、標準的な TF にハイパーパラメータを追加したものを利用します。
$$ tf(検索単語_i, 文書) = \frac{f(検索単語_i数, 文書)*(k_1 +1)}{f(検索単語_i数, 文書) + k_1*(1-b+b*\frac{単語数, 文書}{平均単語数, 全文書})}$$
Okapi BM25 では、「全文書にある単語数の平均」を使って、クエリと関係ない単語が文書に多くなるほどスコアが低くする特徴を残しつつ、TF-IDF の弱点であった「単語が少ない文書ほどスコアが高くなりすぎる」という問題を緩和します。
(k_1) により、BM25 では同じ単語が頻出すると TF が大きくなりすぎることを防ぎます。
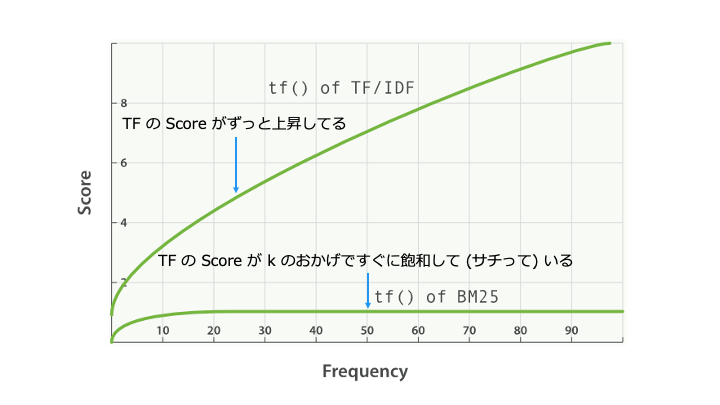
\(k_1\) を増やすと、TF-IDF の線形に近づく
\(k_1\) を小さくするほど、TF (単語の出現頻度) がすぐに飽和します。
\(k_1\) を 0 にすると TF = 1 で飽和するので、Okapi BM25 は IDF の値のみを参照します。
\(b\) を小さくするほど、「文書にある単語数」の影響を受けなくなります。
つまり、\(b\) を 0 にすると、\( tf(検索単語_i, 文書) = \frac{f(検索単語_i数, 文書)*(k_1 +1)}{f(検索単語_i数, 文書) + k_1}\)
となるので、単語の出現回数のみが TF の値に影響を与えます。
Okapi BM25 の TF の計算例
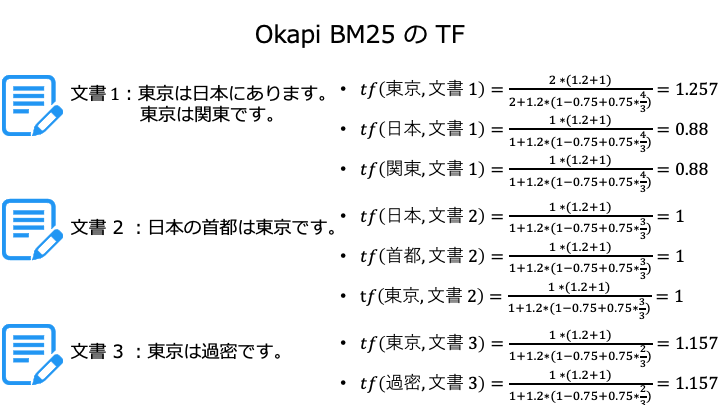
登場回数が同じ単語は、文書に占める単語の割合が大きいもの (単語の少ない文書) を評価
OpenSearch の Okapi BM25 ベース
Okapi BM25 をベースに、以下のように少し数式を変更しています。
$$ tf(単語_i, 文書) = \frac{freq(文書にある検索単語_i数)}{freq(文書にある検索単語_i数) + k_1*(1-b+b*\frac{文書にある単語数}{全文書にある単語数の平均})}$$
- \(k_1\) の OpenSearch のデフォルトは 1.2
- 0 ~ 3 の間で設定すると良いが、これより高くても良い
- 0.5 ~ 2.0 で最適となることが多い
- \(b\) の OpenSearch のデフォルトは 0.75
- 0~1の間で設定を推奨
- 0.3 ~ 0.9 が最適となることが多い

OpenSearch で実際に TF のスコアを確認
PUT bm
{
"settings": {
"number_of_shards": 1
},
"mappings": {
"properties": {
"text":{
"type": "text",
"analyzer": "kuromoji"
}
}
}
}
POST bm/_bulk
{ "index": { "_id": "1" } }
{ "text": "東京は日本にあります。東京は関東です。" }
{ "index": { "_id": "2" } }
{ "text": "日本の首都は東京です。" }
{ "index": { "_id": "3" } }
{ "text": "東京は過密です。" }
GET bm/_search
{
"explain": true,
"query": {
"match": {
"text": "東京"
}
}
}
"_source": {
"text": "東京は日本にあります。東京は関東です。"
{
"value": 0.5714286,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"_source": {
"text": "東京は過密です。"
{
"value": 0.5263158,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"_source": {
"text": "日本の首都は東京です。"
{
"value": 0.45454544,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:"Okapi BM25 の IDF の計算式
Okapi BM25 の IDF は確率論的 IDF を使います。
$$ idf(単語) = ln(1+\frac{文書総数 - 単語が含まれる文書数+0.5}{単語が含まれる文書数+0.5}) $$
なお、マイナスを防ぐために 1 を加算し、0 で除算しないように分母分子に +0.5 します。

OpenSearch で実際に IDF のスコアを確認
GET bm/_search
{
"explain": true,
"query": {
"match": {
"text": "東京"
}
}
}
"description": "weight(text:東京 in 2) [PerFieldSimilarity], result of:",
{
"value": 0.13353139,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
OpenSearch の Okapi BM25 ベースの計算結果
Okapi BM25 は IDF と TF を掛け合わせたものです。
$$ Okapi\ BM25=\sum_{i}^{n}IDF(検索単語_i) * TF (検索単語_i, 文書)$$
$$ OpenSearch版(Okapi\ BM25 ベース)=\sum_{i}^{n}IDF(検索単語_i) * TF (検索単語_i, 文書)*boost$$
今回は OpenSearch で利用している、Okapi BM25 ベースで計算してみます。

OpenSearch で実際にスコアを確認
GET bm/_search
{
"explain": true,
"query": {
"match": {
"text": "東京"
}
}
}
"_score": 0.16786805,
"_source": {
"text": "東京は日本にあります。東京は関東です。"
},
"_score": 0.1546153,
"_source": {
"text": "東京は過密です。"
},
"_score": 0.13353139,
"_source": {
"text": "日本の首都は東京です。"
},
最後に
| Elasticsearch & OpenSearch の使い方 | ||||
|---|---|---|---|---|
