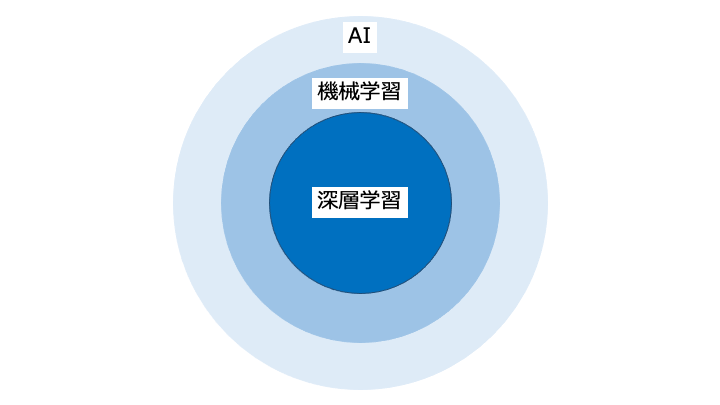
※生成 AI はテキスト/画像/音声などを生成、LLM は生成 AI の中でテキスト生成に特化したもの
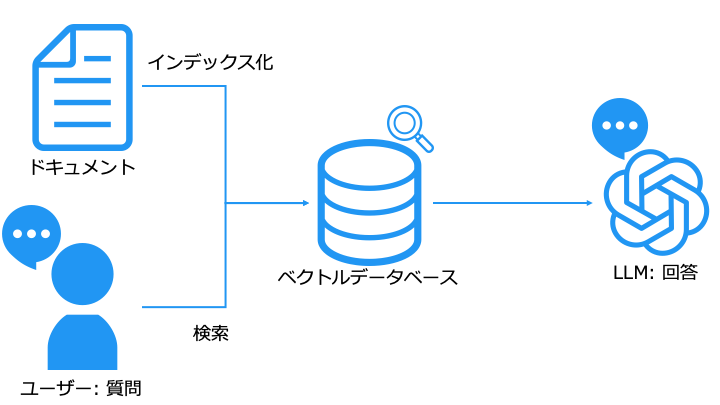
LLM に直接質問しない理由は、LLM が答えを知らなかったり、事実とは異なる嘘の情報を生成する (ハルシネーションと呼ぶ) 場合があるからです。

そこで、データベースから関連情報を取得し、この情報を元に回答を生成します。
| RAG (検索拡張生成) | |||
|---|---|---|---|

 KNN
KNN
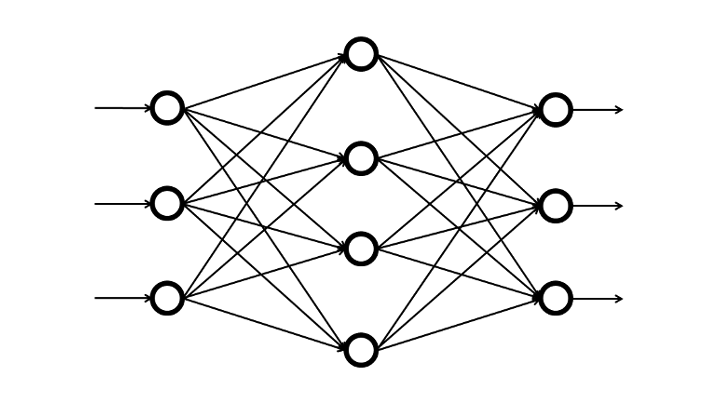
| ディープラーニング | ||||
|---|---|---|---|---|
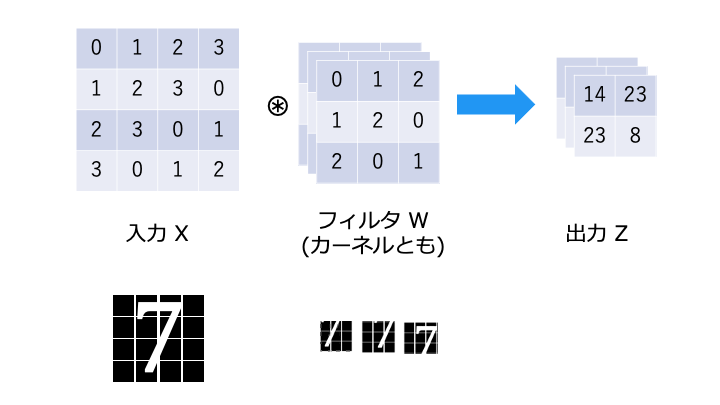














































































































RAG の構成
RAG は主に以下の2つから構成されます。
- データベース (セマンティック検索をするために、ベクトルデータベースを使うことが多い)
- LLM (大規模言語モデル)
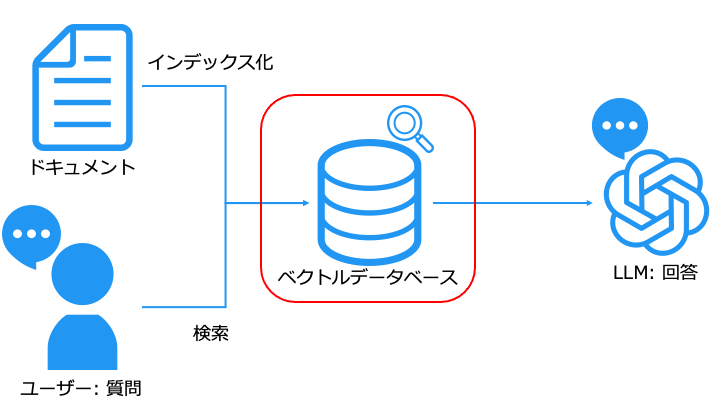
ベクトルデータベースは、関連性の高いデータを検索することが得意とします。
そのため、通常のキーワード検索ではヒットしないようなドキュメントを検索できます。
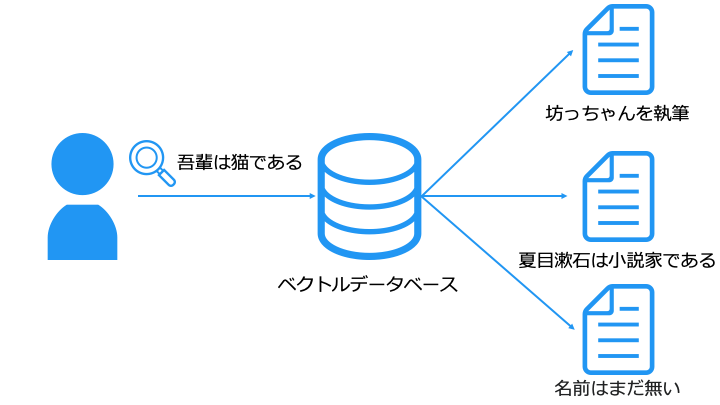
ベクトルデータベースの種類
ベクトルデータベースには、Elasticsearch, OpenSearch, Pinecone, redis, pgvector などが存在します。

一例として、OpenSearch でベクトルデータベースを構築する記事を執筆しています。

LLM (大規模言語モデル) とは
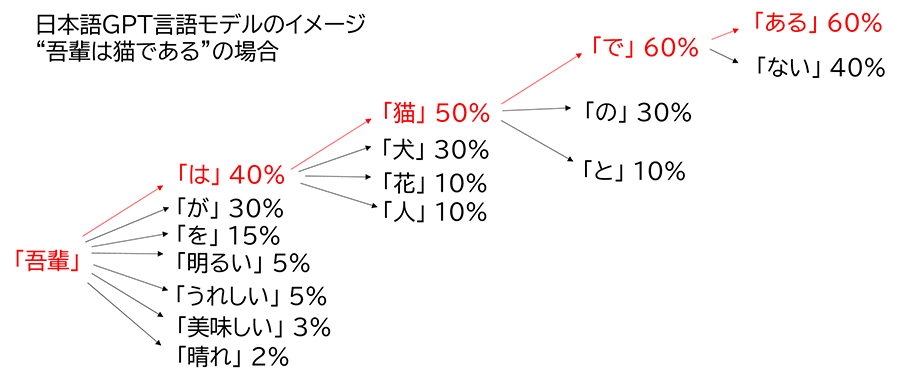
- 「吾輩」の後には、「助詞」が来る確立が高い。
- 「吾輩は」の後には「犬」よりも「猫」が来る確立が高い
このようにして、言語モデルを利用すると確率的に文章を生成できます。
※ LLM は自然言語処理に特化した生成 AI です。
※ LLM におけるパラメータとは、重みとバイアスのことです。詳しくは以下をご覧ください。
言語モデルは、パラメータ数や学習データセットを増やすことで性能が向上することがわかってきたため、大規模化しました。
LLM の種類
LLM には、GPT-4, Claude, Demini, Command R などが存在します。

RAG のメリットについて
RAG を利用することで、以下の2点が実現できます。
- LLM が知らない (学習していない) 情報を回答できる
- ハルシネーションを抑制できる
RAG を使わない場合
LLM が知らない情報を質問すると、求めている回答が得られません。

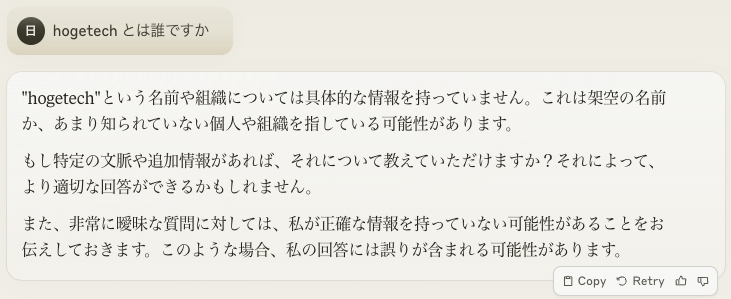
LLM は知らない情報を答えられていません。
RAG を使う場合
冒頭で説明したとおり、RAG を使うと以下の利点があります。
- LLM が知らない (学習していない) 情報を回答できる
- ハルシネーションを抑制できる
LLM が知らない情報を回答
LLM が知らない情報でも、データベースから検索した情報を元に、LLM が回答を生成します。
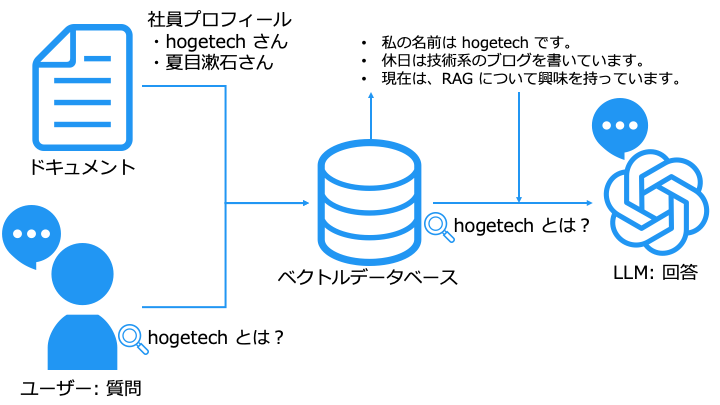
ユーザーの質問を以下のように書き換えて、LLM に渡します。
- <excerpts> に、ベクトルデータベースで検索したドキュメントの内容
- <question> に、LLM への質問
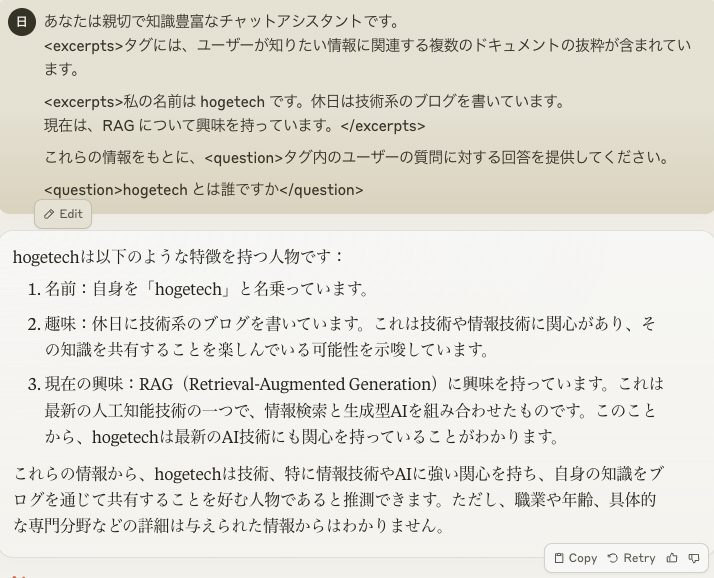
LLM が知らない情報でも、ベクトルデータベースで検索したドキュメントを元に、回答を生成できました。
ハルシネーションを抑制

知らないことは知らないと言えました。(嘘の文章を作成しません。)
RAG の種類
RAG の種類には、以下の2つがあります。
- Naive RAG
- Advanced RAG
今まで紹介してきたものは Naive RAG と呼ばれます。
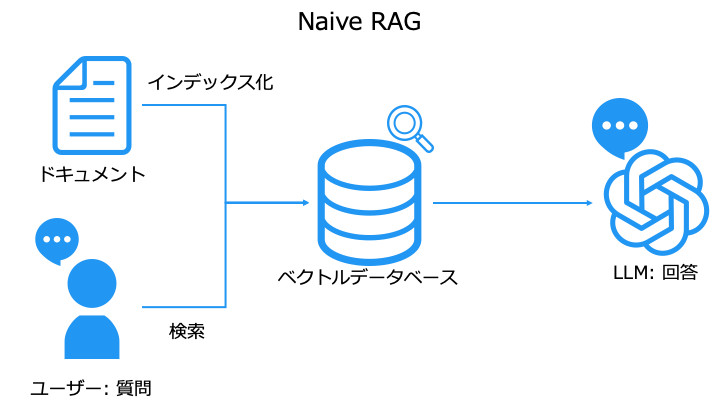
このままでは、期待する品質の回答を生成できない場合があります。
そこで、品質を改善するために Naive RAG に工夫を加えたものを Advanced RAG と呼びます。
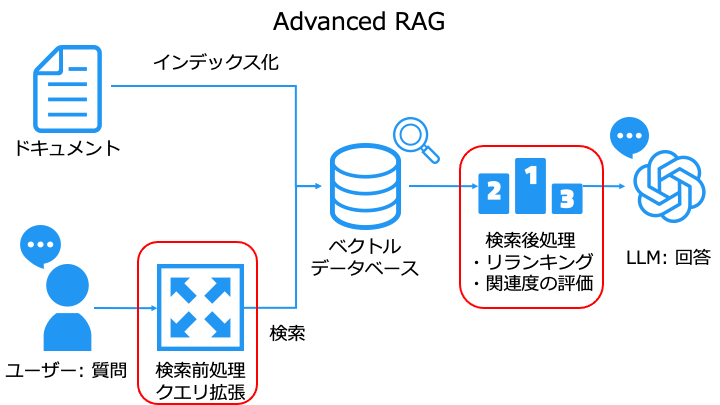
今回は検索の前処理と後処理に LLM を利用した方法を紹介します。
(前処理と後処理に LLM を使わず、ぼくの考えた最強のプログラムを使っても OK です。)
検索前処理:クエリ拡張
これにより、ベクトルデータベースから多様な検索結果を取得できます。
なお、クエリ拡張も LLM を利用して行います。
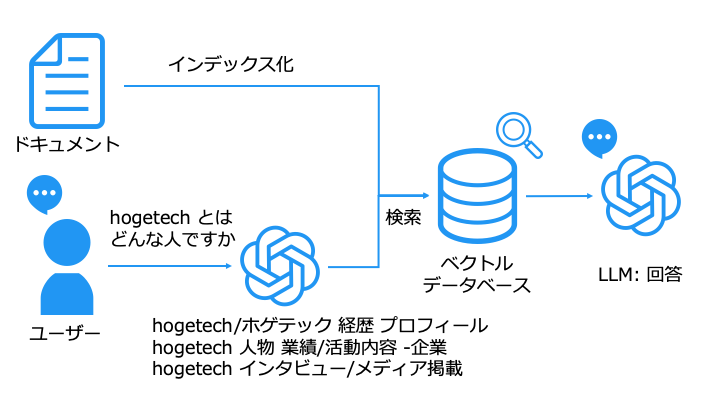
クエリ拡張の例は以下のとおりです。
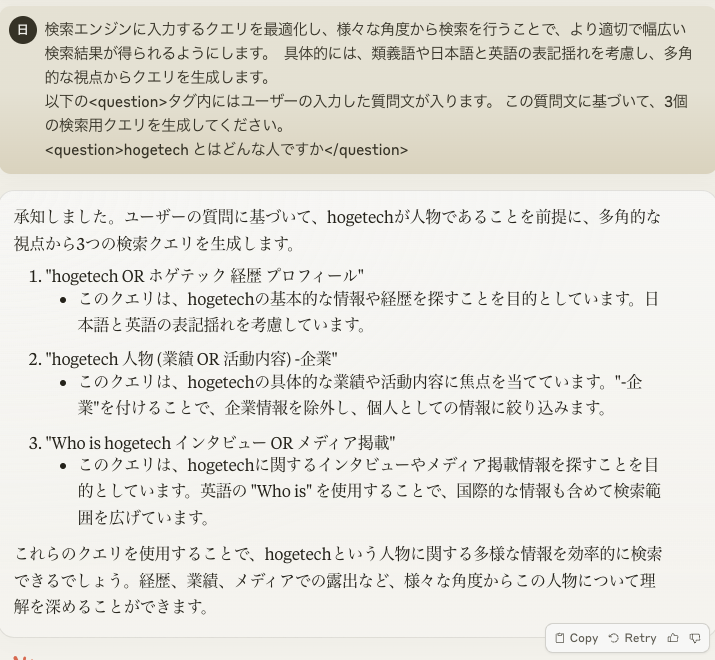
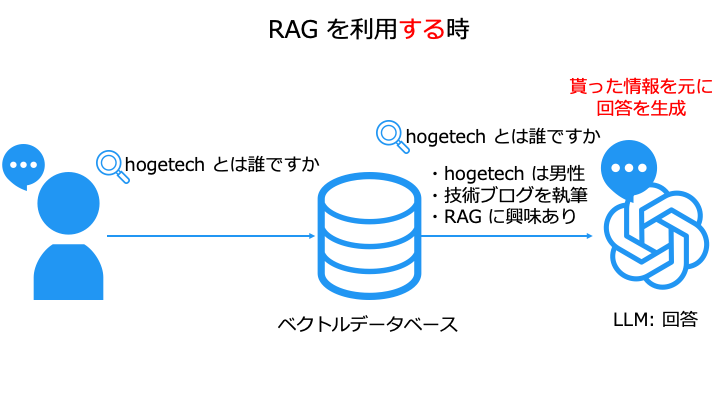
「hogetech とはどんな人ですか」というクエリから、以下のクエリを生成できました。
- hogetech/ホゲテック 経歴 プロフィール
- hogetech 人物 業績/活動内容 -企業
- hogetech インタビュー/メディア掲載
検索後処理:関連度の評価
ベクトルデータベースで検索したドキュメントと、ユーザーの質問の関連度を評価します。
これは、関連性の低いデータを、回答生成に使うと回答の品質が低下するからです。
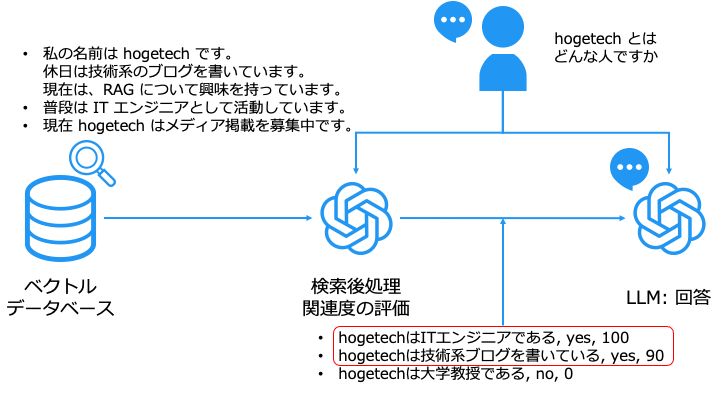
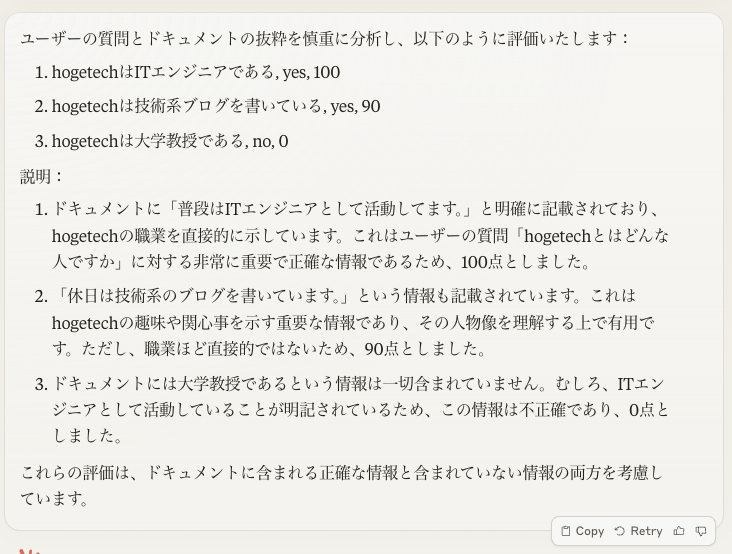
検索の後処理を LLM で行う一例は以下のとおりです。

最後に
関連記事
| RAG (検索拡張生成) | |||
|---|---|---|---|
| ディープラーニング | ||||
|---|---|---|---|---|