
| Linux カーネルの機能 | |||
|---|---|---|---|





![[試して理解]Linuxのしくみ ―実験と図解で学ぶOS、仮想マシン、コンテナの基礎知識【増補改訂版】](https://m.media-amazon.com/images/I/51CKe00bsfL._SL160_.jpg)












































ファイルの基本
ファイルの種類と確認方法
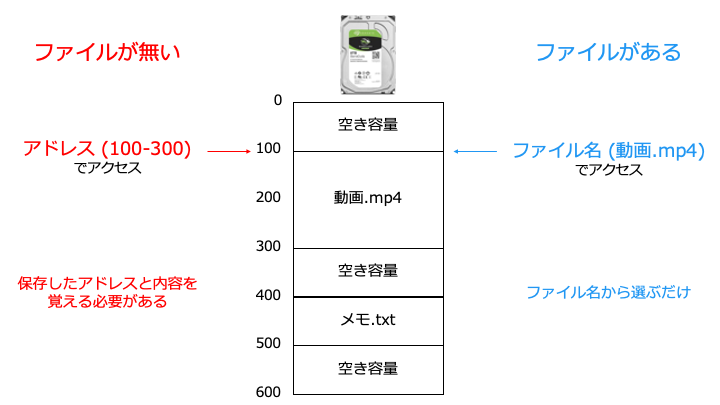
Linux では、ディレクトリやデバイス (ストレージ/マウス等) もファイルとして扱います。
ファイルの種類は以下のとおりです。
| シンボル | ファイルの種類 | 説明 | 用途 |
|---|---|---|---|
| - | レギュラーファイル | データを読み書き可能な普通のファイル | いわゆるファイル |
| d | ディレクトリ | ファイルのリストを持つファイル | ディレクトリ |
| l | シンボリックリンク | このファイルへの読み書きは、参照先のファイルに反映 | 別名ファイル、ショートカット |
| c | キャラクタデバイス | このファイルへの読み書きは、対応するデバイスと1バイト単位でデータをやりとり(つまりストリーム処理) | マウスやキーボード等への読み書き |
| b | ブロックデバイス | このファイルへの読み書きは、対応するデバイスとブロック単位でデータをやりとり(つまりバッファにバイトを貯める) | SSD 等への読み書き |
| p | 名前付きパイプ (FIFOスペシャル) | このファイルへ書き込まれたデータは同じ OS の他のプロセスで読み出すことが可能 | プロセス間通信 |
| s | ソケット | このファイルは別の OS のプロセスから読み書き可能 | 別のOSのプロセスと通信 |
ファイルの種類の確認には ls -l コマンドを使用します。各行の最初の1文字目がシンボルです。
total 80 -rw-r--r-- 1 hoge staff 149 3 20 13:27 Test.java drwxr-xr-x 5 hoge staff 160 1 15 23:17 test
Test.java はレギュラーファイル、test はディレクトリであることがわかります。
ファイルを作成する手順
ストレージにファイルを作成する手順は以下のとおりです。(各用語は後述します)
- ストレージにパーティションを作成 (fdisk コマンド)
- パーティションにファイルシステムを作成 (mkfs コマンド)
- ファイルシステムをマウント (mount コマンド)
- ファイルシステムにファイルを作成
以降では、「パーティション・ファイルシステム・マウント」についてそれぞれ解説します




パーティションとは
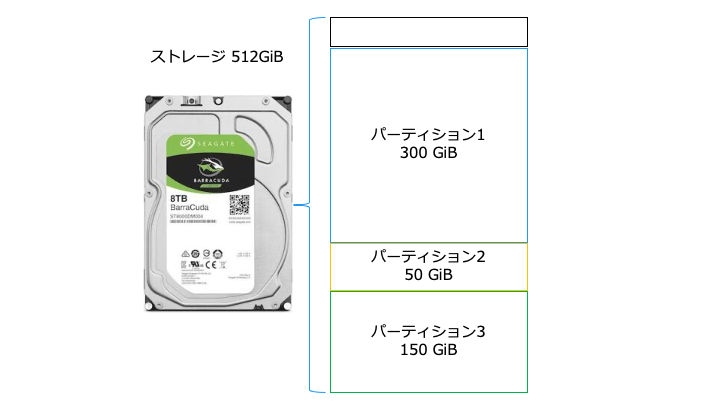
ストレージをパーティションで分割する利点は、主に以下の2つです。
| 利点 | 例 |
|---|---|
| 障害の局所化 (別のパーティションに影響を与えない) | OS のパーティションに再インストールする場合、 アプリケーションのパーティションに影響を与えない |
| 空き容量不足の局所化 (パーティションごとに空き容量を確保) | ログファイルのパーティションが肥大化しても、 OS のパーティションを消費しない |
パーティションテーブルの形式
パーティションテーブルには、次の2種類の形式があります。
| MBR | GPT | |
|---|---|---|
| 対応するストレージ容量 | 2TiB | 8ZiB |
| プライマリーパーティションの数 | 4 | 128 |
| 拡張パーティション | あり | なし |
| 故障耐性 | なし | あり |
| 不正書き込み防止(チェックサム) | なし | あり |
| ストレージアクセス方式 | CHS | CHS, LBA |
| ブートセクタ | MBR | GPTヘッダー |
| ブートセクタ呼び出し元ファームウェア | BIOS | UEFI |
近年では、ストレージ容量が 2TiB を超えるものが出てきたため、MBR を置き換える目的で GPT が導入されました。
MBR 形式における、ストレージの構造は以下のとおりです。
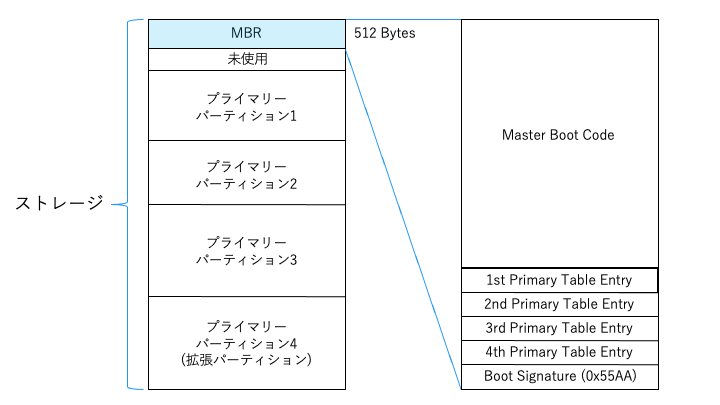
MBR 形式のパーティション構造は、以下の3種類の領域が存在します。
- MBR 領域
- プライマーパーティション領域
- 拡張パーティション領域
Master Boot Code の内容
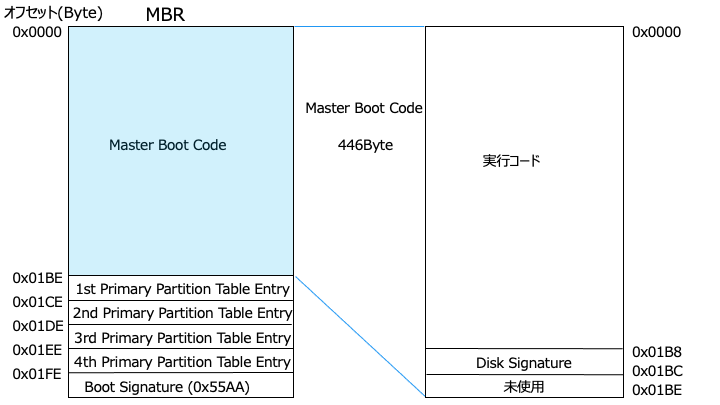
テーブルエントリーの内容
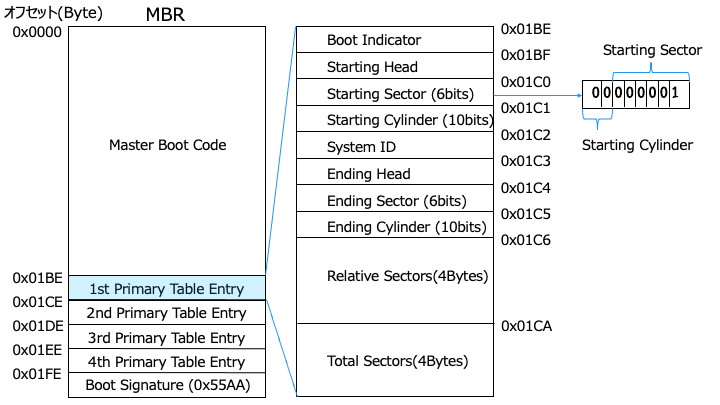
パーティションの内容
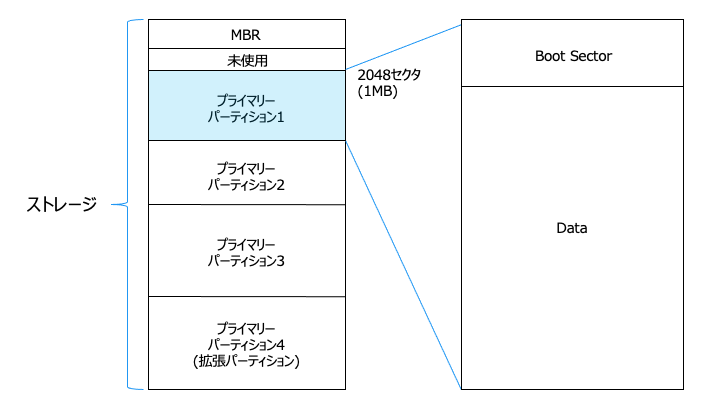
プライマリーパーティション領域の詳細は以下のとおりです。
拡張パーティション領域の詳細は以下のとおりです。
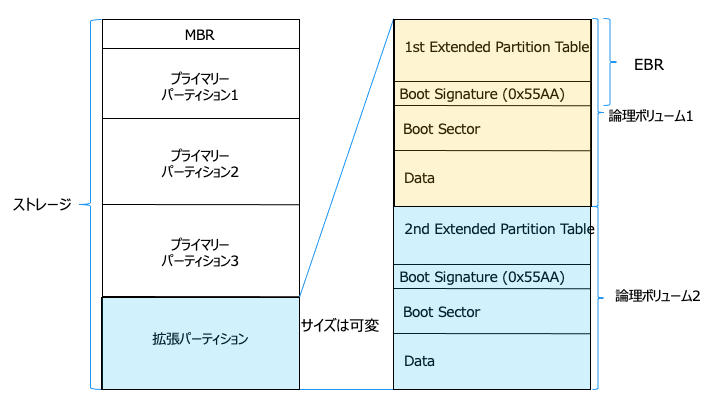
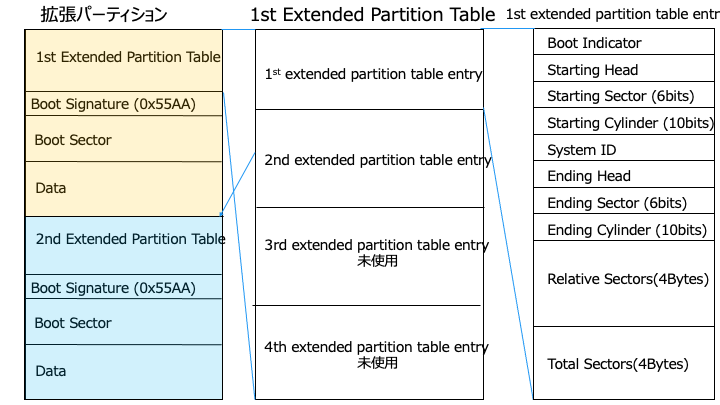
拡張パーティション領域は、上記のように複数の論理パーティションに分けられます。
GPT 形式における、ストレージの構造は以下のとおりです。
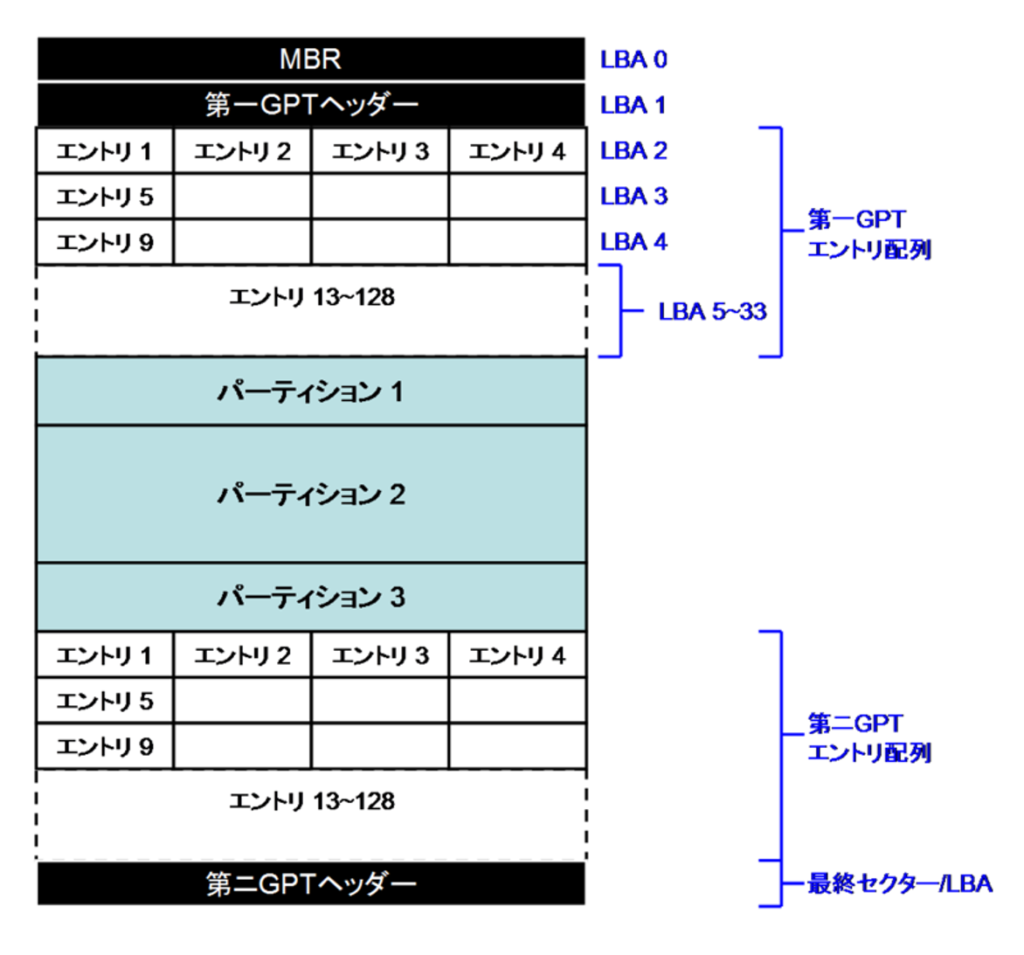
- MBR 形式と互換性を保つために、先頭に MBR が存在
- 冗長化のために、GPT ヘッダーとエントリが2箇所に存在
GPT ヘッダーの内容

エントリーの内容

パーティションテーブルの作成方法 gdisk
ストレージにパーティションテーブルを作成するには、fdisk コマンド (MBR) もしくは gdisk (GPT) を使います。
fdisk を利用する場合
$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 8G 0 disk └─xvda1 202:1 0 8G 0 part / xvdf 202:80 0 10G 0 disk # ブロックデバイスファイル(ファイルとして表現されたストレージ)の一覧を表示 # xvdf ストレージのパーティションを分けることにします。 $ ls /dev/xvd* /dev/xvda /dev/xvda1 /dev/xvdf /dev/xvdf1 # デバイスファイルは "/dev/" 配下に存在します。 $ sudo fdisk /dev/xvdf #/dev/xvdf ブロックデバイスファイル(ファイルとして表現されたストレージ)のパーティションを操作 コマンド (m でヘルプ): n # n はnew パーティションを作成という意味です。 パーティションタイプ p 基本パーティション (0 プライマリ, 0 拡張, 4 空き) e 拡張領域 (論理パーティションが入ります) 選択 (既定値 p): p #基本(プライマリー)パーティションと拡張領域があります。基本パーティション選択 #基本パーティションはOSを起動できるパーティションで4つまで作成できます。論理パーティションは5つ目以降のパーティションを作成する際に基本パーティションの番号(1-4)のどれか1つを拡張パーティションとして定義し、その中に論理パーティションを作成します。 パーティション番号 (1-4, 既定値 1): 1 #4つまで作れます。今回は1つ目なので 1 最初のセクタ (2048-20971519, 既定値 2048): 2048 #管理情報に2048セクタ使用されているので、それ以降を指定します。 最終セクタ, +セクタ番号 または +サイズ{K,M,G,T,P}(2048-20971519, 既定値 20971519):+4G #4G分の領域を確保します。
以下に gdisk を利用した方法を紹介します。
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS xvda 202:0 0 8G 0 disk ├─xvda1 202:1 0 8G 0 part / ├─xvda127 259:0 0 1M 0 part └─xvda128 259:1 0 10M 0 part xvdb 202:16 0 8G 0 disk
/dev/xvda /dev/xvda1 /dev/xvda127 /dev/xvda128 /dev/xvdb
First セクターが 34 から指定可能な理由は、GPT では 33 までがパーティションエントリのため
パーティションタイプの一覧はこちら
| パーティションタイプ | マウントポイント | gdisk の コード | パーティションタイプ GUID |
|---|---|---|---|
| Linux ファイルシステム | 任意 | 8300 | 0FC63DAF-8483-4772-8E79-3D69D8477DE4 |
| EFI システムパーティション | 任意1 | ef00 | C12A7328-F81F-11D2-BA4B-00A0C93EC93B |
| BIOS ブートパーティション | なし | ef02 | 21686148-6449-6E6F-744E-656564454649 |
| Linux x86-64 root (/) | / | 8304 | 4F68BCE3-E8CD-4DB1-96E7-FBCAF984B709 |
| Linux swap | [SWAP] | 8200 | 0657FD6D-A4AB-43C4-84E5-0933C84B4F4F |
| Linux /home | /home | 8302 | 933AC7E1-2EB4-4F13-B844-0E14E2AEF915 |
| Linux /srv | /srv | 8306 | 3B8F8425-20E0-4F3B-907F-1A25A76F98E8 |
| Linux /var | /var1 | 8310 | 4D21B016-B534-45C2-A9FB-5C16E091FD2D |
| Linux /var/tmp | /var/tmp1 | 8311 | 7EC6F557-3BC5-4ACA-B293-16EF5DF639D1 |
| Linux LVM | 任意 | 8e00 | E6D6D379-F507-44C2-A23C-238F2A3DF928 |
| Linux RAID | 任意 | fd00 | A19D880F-05FC-4D3B-A006-743F0F84911E |
| Linux LUKS | 任意 | 8309 | CA7D7CCB-63ED-4C53-861C-1742536059CC |
| Linux dm-crypt | 任意 | 8308 | 7FFEC5C9-2D00-49B7-8941-3EA10A5586B7 |
Disk /dev/xvdb: 16777216 sectors, 8.0 GiB Number Start (sector) End (sector) Size Code Name 1 2048 8388608 4.0 GiB 8300 Linux filesystem
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
xvda 202:0 0 8G 0 disk
├─xvda1 202:1 0 8G 0 part /
├─xvda127 259:0 0 1M 0 part
└─xvda128 259:1 0 10M 0 part
xvdb 202:16 0 8G 0 disk
└─xvdb1 202:17 0 4G 0 part




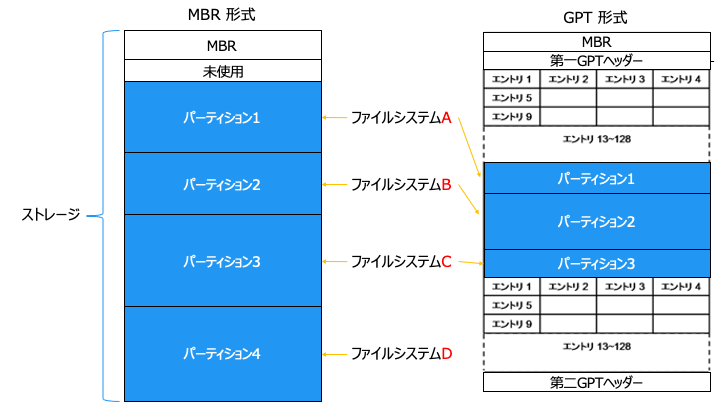
ファイルシステムとは
なお、ファイルシステムはパーティションごとに設定します。
ファイルシステムの詳細な機能は、以下の記事で紹介します。

ファイルシステムの一覧
Linux の主なファイルシステムは、以下のとおりです。
ファイルにアクセスする基本的な機能は同じですが、特定のファイルシステムにしか無い機能も存在します。
| ファイルシステムの種類 | 説明 |
|---|---|
| ext4 | RHEL6/CentOS6 のデフォルト。安定してる |
| XFS | RHEL7,8/CentOS7,8 のデフォルト。断片化に対する影響がない |
| NFS | 同じネットワーク間でファイル共有に使用 |
| SMB | Windows とのファイル共有に使用 |
ファイルシステムの作成・確認コマンド
今回は /dev/xvdb1 パーティションに、xfs ファイルシステムを作成してみます。
/dev/xvdb1: data
"data" はファイルシステムが無いことを表します。
/dev/xvdb1: SGI XFS filesystem data (blksz 4096, inosz 512, v2 dirs)
ファイルシステムの構造
ファイルシステムは、主に以下の4種類のブロックから構成されます。(参考資料)
なお、XFS ファイルシステムにはブートブロックが存在しません。
XFSはファイルシステムの先頭ブロックをスーパーブロックとして使っておりブートローダーを先頭ブロックにインストールすることはできない
https://ja.wikipedia.org/wiki/XFS
https://ja.wikipedia.org/wiki/%E3%83%96%E3%83%BC%E3%83%88%E3%82%BB%E3%82%AF%E3%82%BF
スーパーブロックの確認方法は、ファイルシステムが XFS の場合は以下のとおりです。
(全ての内容を確認する場合は、xfs_db を使用。参考1、参考2、参考3)
meta-data=/dev/xvdb1 isize=512 agcount=4, agsize=524223 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1 bigtime=1 inobtcount=1
ファイルシステムが ext4 の場合のスーパーブロックの確認方法
Filesystem UUID: ????????-????-????-*** ##ファイルシステムのUUID Filesystem magic number: 0xEF53 Inode count: 524288 ##inodeの数 Block count: 2096635 ##ブロックの数 Block size: 4096 ##ブロックのサイズ(Byte) Fragment size: 4096 Group descriptor size: 64 Reserved GDT blocks: 1023 Blocks per group: 32768 Fragments per group: 32768 Inodes per group: 8192 Inode blocks per group: 512 Filesystem created: Sat Oct 5 09:13:12 2019 ##ファイルシステム作成日 Last mount time: Sat Oct 5 09:14:29 2019 ##マウントした日 Last write time: Sat Oct 5 09:14:29 2019 ##最終書き込みを行った日 Inode size: 256 (中略)
POSIX 標準で規定されている inode のメタデータの一覧は、以下の通りです。
- ファイルサイズ
- ファイルタイプ
- inode 番号(ファイルシステム内でユニークな ID 。ファイルを識別)
- 当該 inode を指すハードリンクの数
- デバイス ID(ファイルを格納しているデバイスを識別)
- ファイルパーミッション
- ファイル所有者のユーザー ID
- ファイルのグループ ID
- 最終 inode 更新時(ctime)、最終ファイル更新時(mtime)、最終参照時(atime) を示すタイムスタンプ群
ファイルの Inode の確認方法は、以下のとおりです。
File: `test.txt' Size: 3 Blocks: 8 IO Block: 4096 通常ファイル Device: ****h/*****d Inode: 4006 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 1000/ec2-user) Gid: ( 1000/ec2-user) Access: 2021-04-12 13:04:55.867584473 +0000 Modify: 2021-04-12 13:04:55.867584473 +0000 Change: 2021-04-12 13:04:55.867584473 +0000 Birth: -
aa


ファイルシステムのマウントとは
これにより、ファイルシステムを経由して、ディレクトリ名でストレージにアクセスできるようになります。
なお、紐付けたディレクトリをマウントポイントと言います。
手動マウント方法 mount
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
xvda 202:0 0 8G 0 disk
├─xvda1 202:1 0 8G 0 part /
├─xvda127 259:0 0 1M 0 part
└─xvda128 259:1 0 10M 0 part
xvdb 202:16 0 8G 0 disk
└─xvdb1 202:17 0 4G 0 part /mnt
自動マウント方法 /etc/fstab
mount コマンドだけでは、再起動するとマウントの設定が消えます。
再起動後もマウントの設定を反映させるためには、/etc/fstab ファイルを利用します。
/dev/xvdb1パーティションを /mnt にマウントする方法は以下のとおりです。
/dev/xvdb1: UUID="1234abcd-1234-as12-234s-123456789abc" BLOCK_SIZE="512" TYPE="xfs"
UUID=1234abcd-1234-as12-234s-123456789abc /test xfs defaults 1 1
UUID の値は、先ほど調べた値に置き換えます。
なお、/etc/fstab の各フィールドの意味は以下のとおりです。
| フィールド | 説明 |
|---|---|
| 第1フィールド | デバイス名(UUID もしくはデバイスファイルパス) |
| 第2フィールド | マウントポイント |
| 第3フィールド | ファイルシステムの種類 |
| 第4フィールド | オプション。defaults はブート時にマウント |
| 第5フィールド | 1でダンププログラムがファイルシステムをバックアップする |
| 第6フィールド | 2でOS起動後にfsckチェックを行う 0 - do not check 1 - check immediately during boot 2 - check after boot |
関連記事
| Linux カーネルの機能 | |||
|---|---|---|---|



