まずは、結論としてよく利用するコマンドを書いておきます。
PUT demo_analyzer
{
"mappings": {
"properties": {
"text":{
"type": "text",
"analyzer": "kuromoji",
"search_analyzer": "kuromoji"
}
}
}
}
GET _analyze
{
"analyzer": "kuromoji",
"text": "東京都は日本の首都です。"
}
GET /_analyze
{
"tokenizer" : {
"type": "ngram",
"min_gram":2
},
"text" : "quick"
}
| Elasticsearch & OpenSearch の使い方 | ||||
|---|---|---|---|---|





| 学習ロードマップ | |||||
|---|---|---|---|---|---|






Analyzer の構成要素と一覧
Analyzer は、以下の3つの要素によって構成されます。
| Analyzer の要素 | 説明 |
|---|---|
| Character Filter | ドキュメントの内容をフィルタリング、置換 |
| Tokenizer | ドキュメントの内容をトークン(単語)に分割 |
| Token filter | トークン (単語) のフィルタリング ・ストップワード ・シノニム ・ステミング |
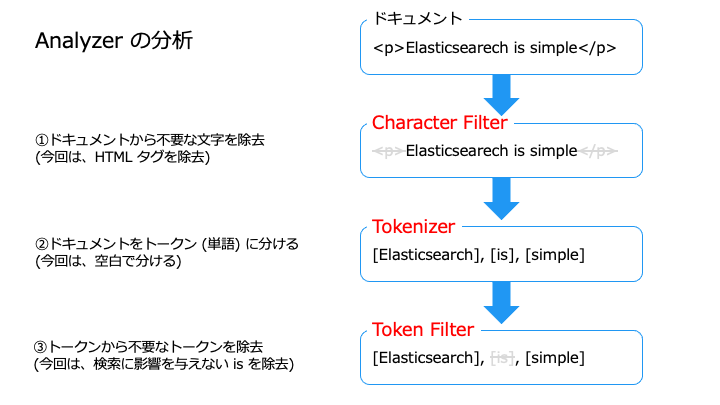
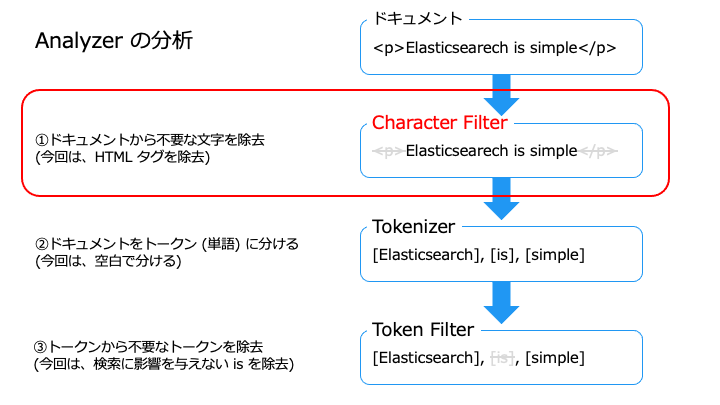
Character Filter には、次の種類があります。
| Character Filter の種類 | 説明 | 例 |
|---|---|---|
| HTML strip | HTML タグを除去 | <p>タグを除去 <p>Elasticsearch</p> → Elasticsearch |
| Mapping | マッピングを作成 | アラビア数字をラテン数字にマッピング [٠١٢٣٤٥٦٧٨٩] → [0123456789] |
| Pattern replace | 正規表現で置換 | ハイフンをアンダースコアに置換 [123-456-789] → [123_456_789] |
Character Filter の使い方
HTML strip character filter で、HTML タグをフィルタリングしてみます。
GET /_analyze
{
"char_filter" : ["html_strip"],
"text" : "<p>Elasticsearch is simple</p>"
}
"token" : """Elasticsearch is simple""",
HTML strip character filter で、<p> タグが除去できました。
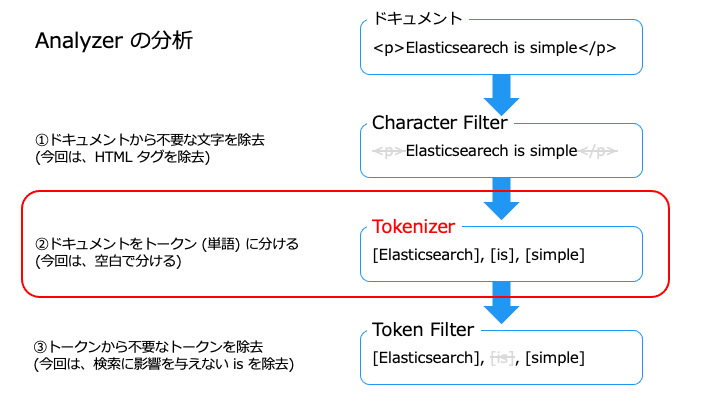
Tokenizer には、次の種類があります。
| Tokenizer の種類 | 説明 | 例 |
|---|---|---|
| ■単語指向分割 (形態素解析) kuromoji_tokenizer (日本語) Standard Tokenizer Letter Tokenizer Lowercase Tokenizer Whitespace Tokenizer UAX URL Email Tokenizer Classic Tokenizer Thai Tokenizer | 単語で分割 | Elasticsearch is simple → [Elasticsearch, is, simple] |
| ■N-gram 分割 (Partial Words) N-Gram Tokenizer Edge N-Gram Tokenizer | N 文字で分割 | N-Gram: quick → [qu, ui, ic, ck]. Edge N-Gram: quick → [q, qu, qui, quic, quick] |
| ■構造化テキスト分割 Keyword Tokenizer Pattern Tokenizer Simple Pattern Tokenizer Char Group Tokenizer Simple Pattern Split Tokenizer Path Tokenizer | 一定規則で分割 | /foo/bar/baz → [/foo, /foo/bar, /foo/bar/baz ] |
この中でよく利用する、単語指向分割 (形態素解析) と N-gram 分割について解説します。
形態素と単語の違い
形態素はそれ以上分割できないが、単語は分割できる場合もある
「お金」(単語)は、
「お」(拘束)形態素と、「金」(自由)形態素に分解できます。
「お」は単語じゃないですが、「金」は単語です。
形態素解析には、主に次の2種類があります。
- 空白で分割
- 辞書/ラティスで分割
空白で分割
空白でドキュメント (文章) をトークン (単語) に分割する方法です。
Elasticsearch is simple --> [Elasticsearch], [is], [simple]
英語では実用的な方法ですが、日本語は空白で文章が区切られないので使いにくいです。
Elasticsearchはシンプルです --> [Elasticsearchはシンプルです]
そこで日本語の場合は「辞書/ラティス」を利用します。
辞書/ラティスで分割
辞書にある単語を使って、自然な日本語 (コストの低い経路) にドキュメントを分割する方法です。
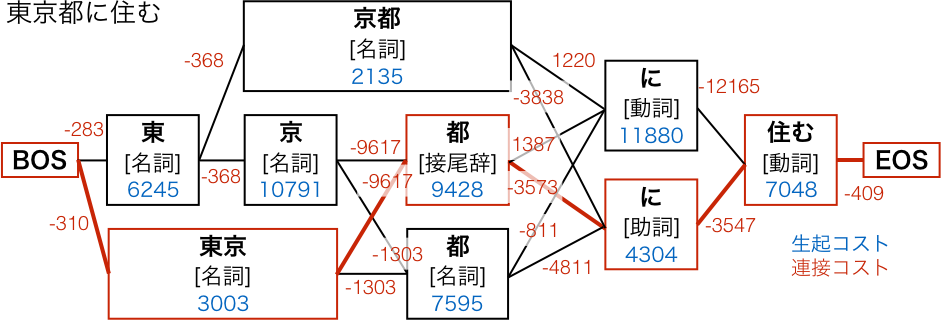
以下の2つのコストの合計が最も低い経路 (最も自然な日本語) を選択します。
- 生起コスト:単語の出現しやすさ (例: 「アベック」より「カップル」の方がよく言う)
- 連接コスト:2つの単語の繋がりやすさ (動詞の後は格助詞は NG [例: ドアを開ける"を"])
なお、辞書に載ってない単語の検索漏れが発生する欠点があります。
- 2-gram (bigram) の場合:quick → [qu, ui, ic, ck]
- 3-gram (trigram) の場合:quick → [qui, uic, ick]
N-gram は、辞書に載ってない単語でも検索できる一方で、検索ノイズが大きくなります。
(2-gram の場合、ice → [ic, ce] で quick → [qu, ui, ic, ck] がヒットするなど。)
Tokenizer の使い方
Whitespace tokenizer で、空白でトークン (単語) に分割してみます。
GET /_analyze
{
"tokenizer": "whitespace",
"text": "Elasticsearch is simple"
}
"tokens" : [
{
"token" : "Elasticsearch",
"start_offset" : 0,
"end_offset" : 13,
"type" : "word",
"position" : 0
},
{
"token" : "is",
"start_offset" : 14,
"end_offset" : 16,
"type" : "word",
"position" : 1
},
{
"token" : "simple",
"start_offset" : 17,
"end_offset" : 23,
"type" : "word",
"position" : 2
}
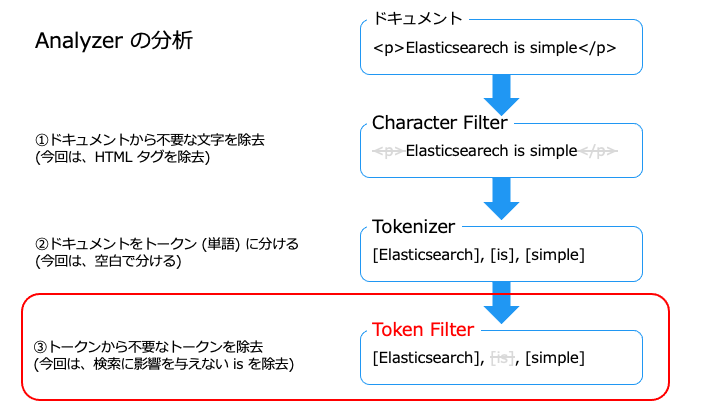
Token Filter には、次の種類があります。
| Token Filter の種類 | 説明 | 例 |
|---|---|---|
| Lower case Token Filter | トークンを小文字に変換 | [Elasticsearch] → [elasticsearch] |
| Stop Token Filter | ストップワードを設定 | [Elasticsearch is simple] → [Elasticsearch, simple] |
| Stemmer Token Filter | ステミングを設定 | [swims], [swimming], [swimmer] → [swim] |
| Synonym Token Filter | シノニムを設定 | [jump], [leap] → [jump] |
例:[Elasticsearch is simple] → [Elasticsearch, simple]
例:[swims], [swimming], [swimmer] → [swim]
例:[jump], [leap] → [jump]
Token filter の使い方
Stop token filter で、ストップワードの is をフィルタリングしてみます。
GET /_analyze
{
"tokenizer": "whitespace",
"filter": [ "stop" ],
"text": "Elasticsearch is simple"
}
"tokens" : [
{
"token" : "Elasticsearch",
"start_offset" : 0,
"end_offset" : 13,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "simple",
"start_offset" : 17,
"end_offset" : 23,
"type" : "<ALPHANUM>",
"position" : 2
}
ストップワードのデフォルトの設定に従って、"is" がフィルタリングされています。
When not customized, the filter removes the following English stop words by default:
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-stop-tokenfilter.html#analysis-stop-tokenfiltera,an,and,are,as,at,be,but,by,for,if,in,into,is,it,no,not,of,on,or,such,that,the,their,then,there,these,they,this,to,was,will,with
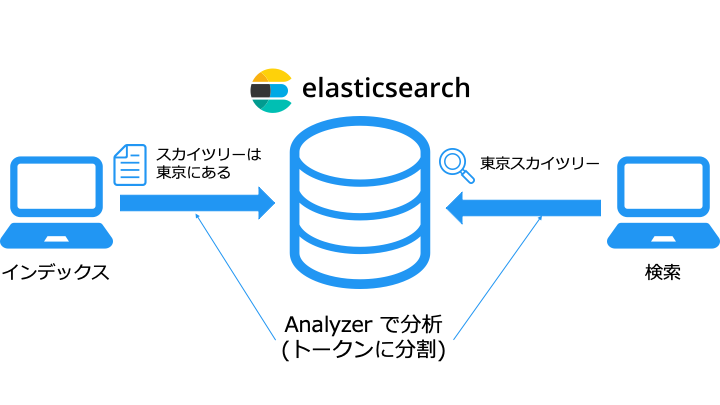
インデックスに Analyzer を設定
Analyzer は、構成要素を事前に定義されたものと、自分で定義するものの2種類があります。
| Analyzer の種類 | 説明 |
|---|---|
| Built-in analyzer | Character Filter, Tokenizer, Token Filter が事前に定義されている |
| Custom analyzer | Character Filter, Tokenizer, Token Filter を自分で定義する |
分析プラグインは事前に定義されているので built-in のように使えます。日本語検索の kuromoji analyzer は分析プラグインに相当
Analyzer はインデックス時と検索時で利用し、デフォルトは Standard Analyzer で分析します。
Standard Analyzer の構成は以下のとおりです。
| 構成要素 | Standard Analyzer の構成 |
|---|---|
| Character filter | なし |
| Tokenizer | Standard Tokenizer |
| Token filter | Lower Case Token Filter Stop Token Filter (disabled by default) |
Built-in analyzer の設定
インデックス (built-in) に、Built-in analyzer の Whitespace analyzer を設定してみます。
PUT built-in
{
"mappings": {
"properties": {
"str": {
"type": "text",
"analyzer": "whitespace",
"search_analyzer": "whitespace"
}
}
}
}
これで text フィールドのインデックス時と検索時に Built-in Analyzer が使用されます。
※analyzer = インデックス時, search_analyzer = 検索時
Built-in analyzer の分析結果
GET built-in/_analyze
{
"analyzer":"whitespace",
"text": "Elasticsearch is simple"
}
"tokens": [
{
"token": "elasticsearch",
"start_offset": 0,
"end_offset": 13,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "is",
"start_offset": 14,
"end_offset": 16,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "simple",
"start_offset": 17,
"end_offset": 23,
"type": "<ALPHANUM>",
"position": 2
}
Custom analyzer の設定
インデックスに次の Custom analyzer を設定してみます。
| Analyzer の要素 | 構成 | やりたいこと |
|---|---|---|
| Character Filter | HTML strip character filter | ドキュメントから <p> タグを除去 |
| Tokenizer | Whitespace tokenizer | ドキュメントを空白でトークン (単語) に分割 |
| Token filter | Stop token filter Lowercase token filter | トークンから "This", "is" を除去 大文字のトークンを小文字にする |
インデックス (custom) に、Custom Analyzer (my_custom_analyzer) を設定します。
PUT custom
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"char_filter": "html_strip",
"tokenizer": "whitespace",
"filter": ["lowercase","stop"]
}
}
}
},
"mappings": {
"properties": {
"str": {
"type": "text",
"analyzer": "my_custom_analyzer",
"search_analyzer": "my_custom_analyzer"
}
}
}
}
Custom analyzer の分析結果
GET custom/_analyze
{
"analyzer": "my_custom_analyzer",
"text": "<p>This is Elasticsearch</p>"
}
{
"tokens" : [
{
"token" : "elasticsearch",
"start_offset" : 11,
"end_offset" : 24,
"type" : "word",
"position" : 2
HTML タグは消え、"This", "is" は削除され、"Elasticsearch" トークンは小文字になっています。
kuromoji analyzer (日本語検索)
デフォルトの Standard Analyzer では、日本語をうまくトークンに分割できないため、日本語を適切に検索できません。
Standard Analyzer を使用して日本語を検索した場合
POST _analyze
{
"analyzer": "standard",
"text": "東京都に行く"
}
日本語には単語の間にスペースがないため、1文字ずつトークンナイズされます。
"tokens" : [
{
"token" : "東",
"start_offset" : 0,
"end_offset" : 1,
"type" : "",
"position" : 0
},
{
"token" : "京",
"start_offset" : 1,
"end_offset" : 2,
"type" : "",
"position" : 1
},
{
"token" : "都",
"start_offset" : 2,
"end_offset" : 3,
"type" : "",
"position" : 2
},
{
"token" : "に",
"start_offset" : 3,
"end_offset" : 4,
"type" : "",
"position" : 3
},
{
"token" : "行",
"start_offset" : 4,
"end_offset" : 5,
"type" : "",
"position" : 4
},
{
"token" : "く",
"start_offset" : 5,
"end_offset" : 6,
"type" : "",
"position" : 5
}
1文字ずつトークンに分割することの何が問題かというと、1文字でも同じ文字が含まれると検索にヒットします。
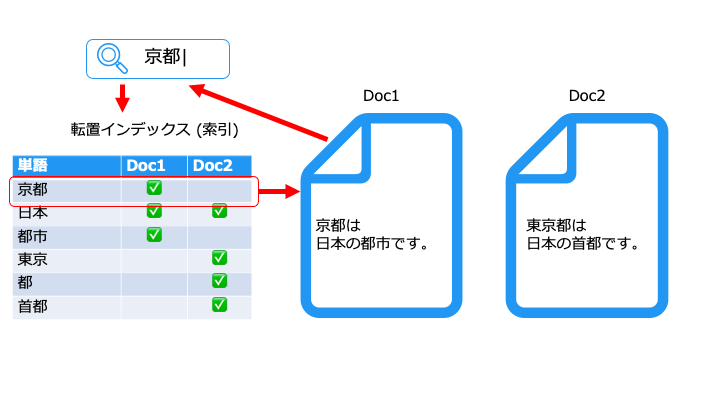
例えば、「か"に"」は、「東京"に"行く」というドキュメントにヒットします。
PUT standard/_doc/1
{
"text":"東京都に行く"
}
GET standard/_search
{
"query": {
"match": {
"text": "かに"
}
}
}
"hits" : [
{
"_index" : "standard",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.18232156,
"_source" : {
"analyzer" : "standard",
"text" : "東京都に行く"
そのため、日本語を検索する場合は、kuromoji Analyzer を使用します。
kuromoji Analyzer の構成
kuromoji Analyzer は以下の要素で構成されます。
| 構成要素 | kuromoji Analyzer の要素 |
|---|---|
| Character Filter | CJKWidthCharFilter (Apache Lucene) |
| Tokenizer | kuromoji_tokenizer |
| Token Filter | kuromoji_baseform token filter kuromoji_part_of_speech token filterja_stop token filterkuromoji_stemmer token filterlowercase token filter |
kuromoji Analysis Plugin をインストール
kuromoji Analyzer を利用するためには、Elasticsearch に kuromoji Analysis Plugin をインストールする必要があります。
docker を利用しない方法
FROM docker.elastic.co/elasticsearch/elasticsearch:7.12.1 RUN /usr/share/elasticsearch/bin/elasticsearch-plugin install analysis-kuromoji
version: '3' services: elasticsearch: build: context: . dockerfile: Dockerfile container_name: elasticsearch environment: - discovery.type=single-node ports: - 9200:9200 kibana: image: kibana:7.12.1 ports: - "5601:5601" environment: - ELASTICSEARCH_HOSTS=http://elasticsearch:9200
※既に Elasticsearch, kibana コンテナを起動してる場合は、docker-compose down を実行してください。
kuromoji Analyzer の使い方
まずは、インデックス (demo_analyzer) に kuromoji Analyzer を設定します。
PUT demo_analyzer
{
"mappings": {
"properties": {
"text":{
"type": "text",
"analyzer": "kuromoji",
"search_analyzer": "kuromoji"
}
}
}
}
kuromoji Analyzer の分析結果
POST _analyze
{
"analyzer": "kuromoji",
"text": "東京都に行く"
}
"tokens" : [
{
"token" : "東京",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "都",
"start_offset" : 2,
"end_offset" : 3,
"type" : "word",
"position" : 1
},
{
"token" : "行く",
"start_offset" : 4,
"end_offset" : 6,
"type" : "word",
"position" : 3
}
日本語らしいトークンに分割できていることがわかります。
(例えば、「京都」の検索ノイズとして「東京都」を回避できることがわかります。)
kuromoji Analyzer のインデックスと検索結果を確認
PUT demo_analyzer/_doc/1
{
"text":"東京都に行く"
}
GET demo_analyzer/_search
{
"query": {
"match": {
"text": "東京"
}
}
}
"hits" : [
{
"_index" : "demo_analyzer",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"text" : "東京都に行く"
}
}
東京では無事ヒットしました。
次に「京都」で「東京都」が検索ノイズにならないことを確認します。
GET demo_analyzer/_search
{
"query": {
"match": {
"text": "京都"
}
}
}
"hits": []
無事に「京都」で「東京都」がヒットせず、日本語らしい検索ができています。
関連記事
| Elasticsearch & OpenSearch の使い方 | ||||
|---|---|---|---|---|
| 学習ロードマップ | |||||
|---|---|---|---|---|---|