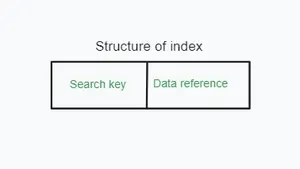
インデックスは、更新速度とストレージの容量を犠牲に※、テーブルの検索速度を向上させます。
※データとは別に、インデックスの更新や保存が必要なため
| 関連記事:データベース設計 | |||||
|---|---|---|---|---|---|
| 学習ロードマップ | |||||
|---|---|---|---|---|---|




















インデックスの種類
ここでは、様々な観点からインデックスの種類を説明します。
DBMS におけるインデックス
DBMS に設定するインデックスの種類は次の2つです。
通常、主キーを設定すると自動的にプライマリーインデックスが作成されます。
これは、主キーを設定する目的に、レコードを一意に特定することが挙げられるためです。
(主キーは重複や NULL が無いので、必ず1つのレコードが見つかる)
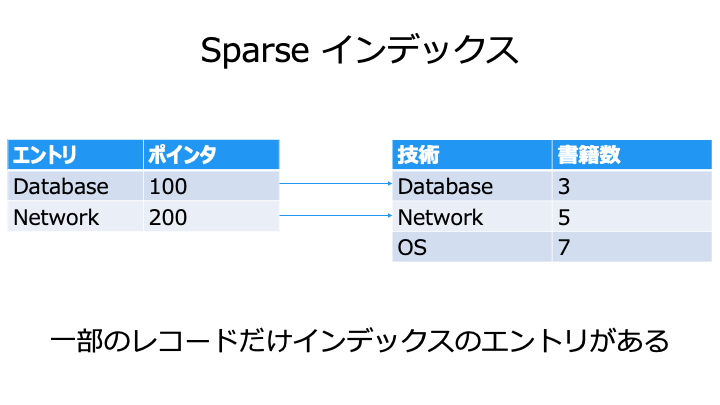
インデックスの密度
インデックスは、密度によって Dense インデックスと Sparse インデックスに分類します。
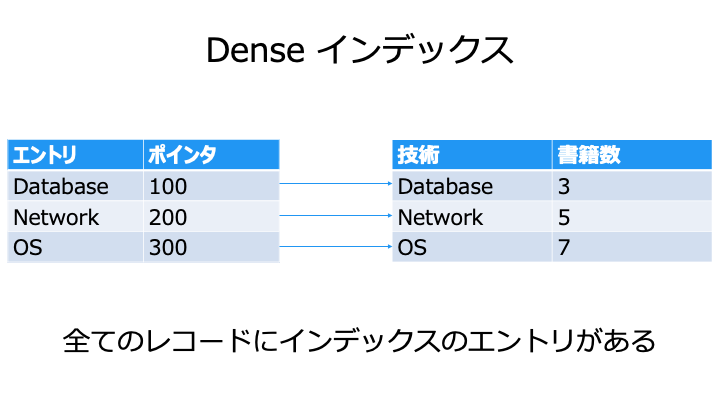
基本的に全てのレコードにインデックスをつけたいので Dense インデックス利用します。
一方で、ベクトルデータベースなどでは、あまりにもインデックスが大きくなりすぎるので、Sparse インデックスを使ってストレージ容量や計算コストを削減します。
アルゴリズムの種類
インデックスのアルゴリズムには、次のような種類が存在します。
| インデックスの種類 | 利用用途 |
|---|---|
| B-Tree インデックス | DBMS のインデックスと言えば、ほぼこれ |
| ビットマップインデックス | OR 検索に対して利用可能 |
| ハッシュインデックス | 等値検索 (=) が非常に高速 |
| 転置インデックス | 全文検索のインデックスと言えばこれ |
























B-Tree インデックス
ここでは、ほとんどの DBMS のデフォルトで利用する B-Tree インデックスを解説します。
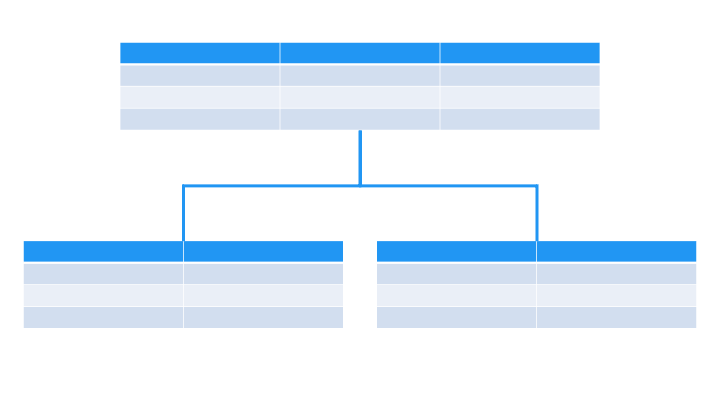
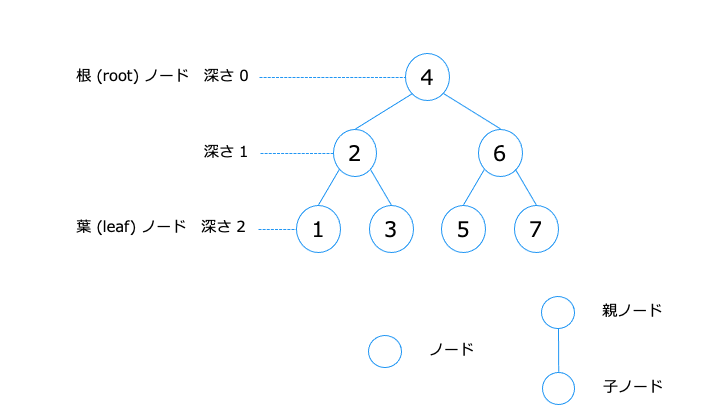
B-Tree インデックスの構造
ID = 1〜7 の B-Tree インデックスの構造は、以下のとおりです。
B-Tree を使って、ID = 3 を検索する場合は以下のとおりです。
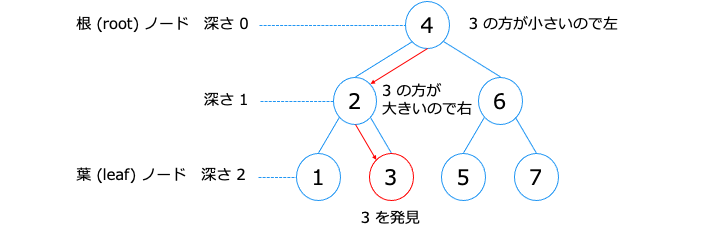
よって、インデックスを使用すると、最悪計算量は 3 [= \( O(log_{2} N)\)] です。
インデックスを使用しないと、7 個の ID を全て検索するので、最悪計算時間は 7 [= \( O(N)\)]です。
そのため、インデックスを使用すると、検索が高速になります。
B-Tree インデックスの使い方
インデックスを作った列を、SQL の WHERE や JOIN で指定すれば使えます。
SQL がインデックスを使っているかどうかは、explain で確認できます。
+----+-------------+-------+------------+-------+---------------+---------+ | id | select_type | table | partitions | type | possible_keys | key | +----+-------------+-------+------------+-------+---------------+---------+ | 1 | SIMPLE | test | NULL | const | PRIMARY | PRIMARY | +----+-------------+-------+------------+-------+---------------+---------+
- type が ALL 以外なら、インデックスを使ってます。 (type の意味はこちら)
- インデックスに使う列は、key で確認できます。(PRIMARY は主キーの列)
B-Tree インデックスが使えない例
以下の SQL はインデックスが利用できません。
インデックスには col_1 の値が保持されてますが、col_1 * 1.1 という値は無いため NG です。
NG1 と同じ理由で、インデックスに保持している値が MOD(col_1, 2) では無いためです。
NOT は B-Tree の右も左もノードを探索する必要があるのでインデックスの意味がないです。
インデックスの無いカラムが含まれる場合は、インデックスを使いません。
インデックスは前方一致で作成します。(本の索引で、a で終わる単語が検索出来ないのと同じ)
文字列カラムと数字との比較では、MySQL はカラム上のインデックスを使用して、値をすばやく検索できません。
str_colがインデックスの付いた文字列カラムである場合は、次のステートメントで検索を実行するときに、そのインデックスを使用できません。SELECT * FROM tbl_name WHERE str_col=1;その理由は、
https://dev.mysql.com/doc/refman/8.0/ja/type-conversion.html'1'、' 1'、'1a'のように、値1に変換できるさまざまな文字列があるためです。
※逆に数字カラムと文字列の比較は、インデックスが効いた (MySQL 8.0.37)
インデックスを作成する基準
| インデックスを作成する基準 | 説明 |
|---|---|
| サイズの大きなテーブル | インデックスを探索するオーバーヘッドがあるため。 小さなテーブルだと直接テーブルをスキャンした方が速い |
| 主キーに不要 | 主キーは自動的にインデックスが作成される。 そのため、自分で作成する必要なし |
| WHERE や JOIN に使用する列 | インデックスを使わないと意味がない。 むしろ、インデックスの作成で更新が遅くなるので悪影響 |
| カーディナリティの高い列 (異なる値が多い列) | カーディナリティが低い (同じ値が多い) と、 同じ値を持つ全ての行をスキャンする必要があるため (つまり、行をあまり絞り込めない) |
































関連記事
| 学習ロードマップ | |||||
|---|---|---|---|---|---|
| 関連記事:データベース設計 | |||||
|---|---|---|---|---|---|
| 関連記事:データベースの基礎知識編 | |||||
|---|---|---|---|---|---|











参考記事