
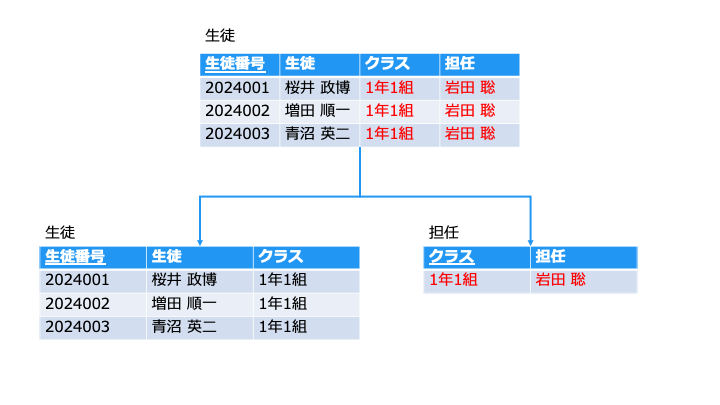
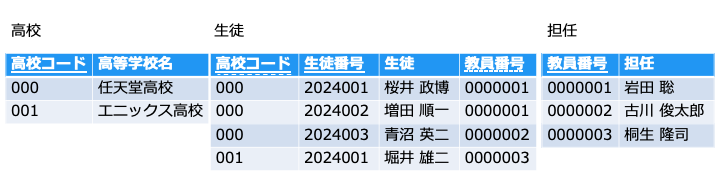
[担任] 情報は [生徒] テーブルと [担任] で JOIN すれば追えます
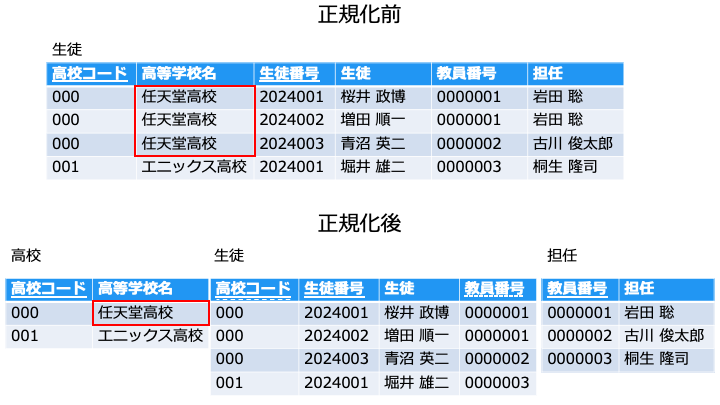
上記の [生徒] テーブルの [クラス] と [担任] は、同じ内容が重複しています。
(同じクラスなら、同じ担任になるので、各行で同じデータを持つ必要が無いです)
そこで、[生徒] と [担任] の2つのテーブルに分けています。
| 関連記事:データベース設計 | |||||
|---|---|---|---|---|---|
| 学習ロードマップ | |||||
|---|---|---|---|---|---|






列のキーの種類
まずは、正規化に登場する、列のキーについて説明します。
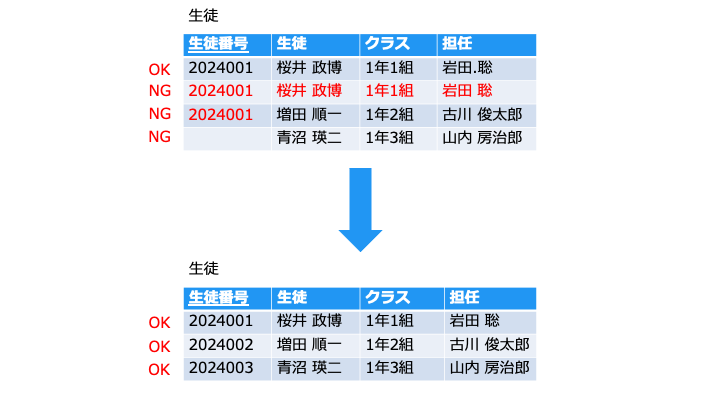
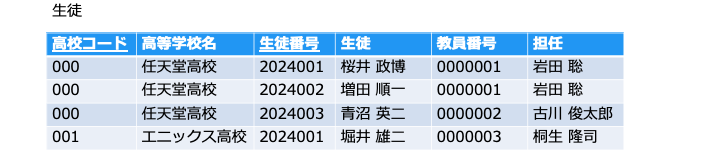
以下の例では、[生徒番号] が主キーです。(主キーは、列名に下線を引きます。)
主キーを設定する目的は次の 3 つです。
- データの重複を避ける (2行目:同じ行が登録されている)
- データの不整合を避ける (3行目:同じ [生徒番号] で違う [生徒] が登録されている)
- データの検索に使う(4行目:検索に使うため、NULL を禁止する)

上記の場合、[生徒番号] と [電話番号] が生徒を一意に特定できそうなので、候補キーとなります。
候補キーの中から、主キーを1つ選びます。(今回は値の変わらない [生徒番号] を主キーとします)

[教科担任] は、[教科] と [クラス] で一意に決まります。
そのため、[教科] と [クラス] が複合主キーとなります。

外部キーは破線で表し、子テーブル [生徒] の [クラス] が外部キーです。
これにより、存在しない [クラス] に [生徒] を割り当てることを防ぎます。
データベース設計の基本的な考え方
データベース設計の基本的な考え方は次の 3 つです。
- 行 (レコード) の重複を避ける
- 同じ集合は同じテーブルにする
- 異なる集合は別のテーブルにする
行 (レコード) の重複を避ける
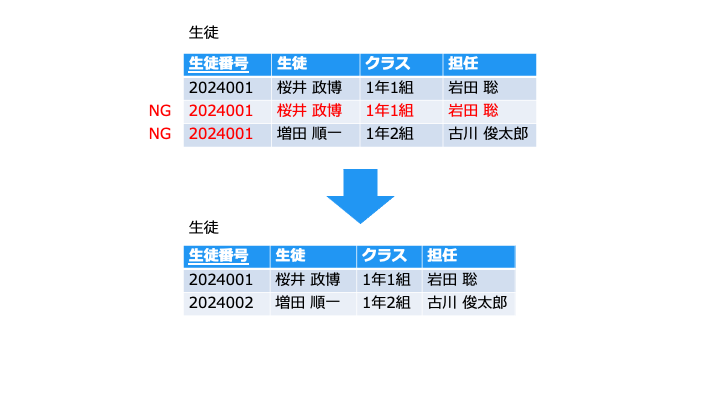
上のテーブルの問題点は次の 2 つです。
- 2 行目:1 行目と全く同じで、データが重複しています。
- 3 行目:同じ [生徒番号] で違う生徒がいるので、データの不整合が発生しています。
そのため、[生徒番号] に主キーを設定してこれを解決しています。
同じ集合は同じテーブルにする
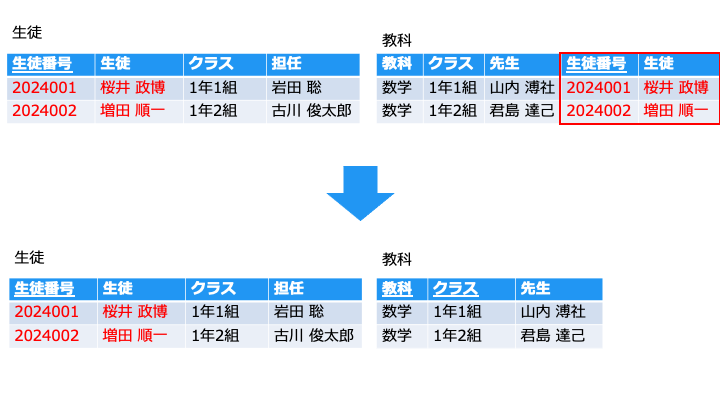
[教科] テーブルの [生徒番号] と [生徒] は、[生徒] テーブルに同じデータがあるので無駄です
- [教科] テーブルにある [生徒番号] と [生徒] 列は、[生徒] テーブルにまとめます。
- 同じ教科でもクラスで先生は変わるので、[教科] テーブルにある [クラス] は残します。
異なる集合は別のテーブルにする
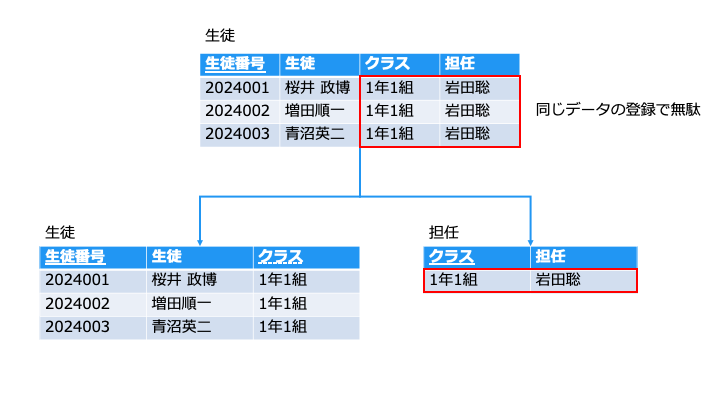
テーブルを分割すると、担任は1クラスに1行で済みます
[担任] 列が重複したデータを持つので無駄です。
- [担任] 列は、[担任] というテーブルで分けて管理します。
- [クラス] は、[生徒] も [担任] も持つ要素なので、それぞれのテーブルに残します。
- [生徒] テーブルの [クラス] は、[担任] テーブルの外部キーです。
データベース設計と正規化の手順
上記の「データベース設計の基本的な考え方」を元に、天才なら直感でテーブルを作れます。
では、我々凡人はどうすればいいのでしょうか。
我々凡人でも、正規化のルールに従うと、上述したテーブルを作成できます。
正規化には3つのルールをよく使います。
- 第一正規形 (1 Normal Form)
- 第二正規形 (2 Normal Form)
- 第三正規形 (3 Normal Form)
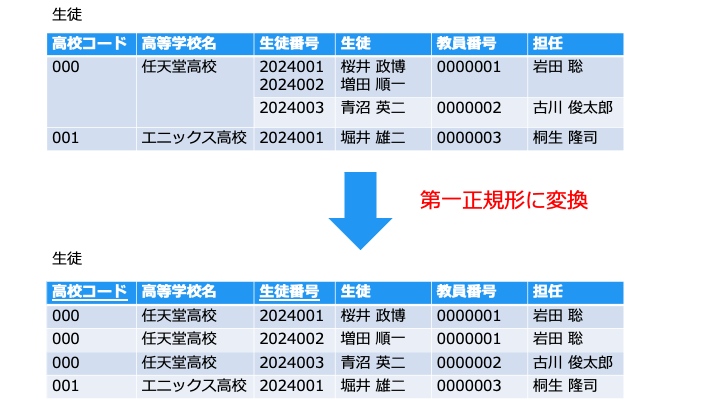
元のテーブルでは、主キーが設定できないため、第一正規形に変換する必要があります。
第一正規系のメリット
主キーで行を一意に特定できるようになります。
桜井 政博さんのデータが欲しい場合、第一正規形ではない場合、他の生徒のデータも読み取る必要があり、無駄が発生します。
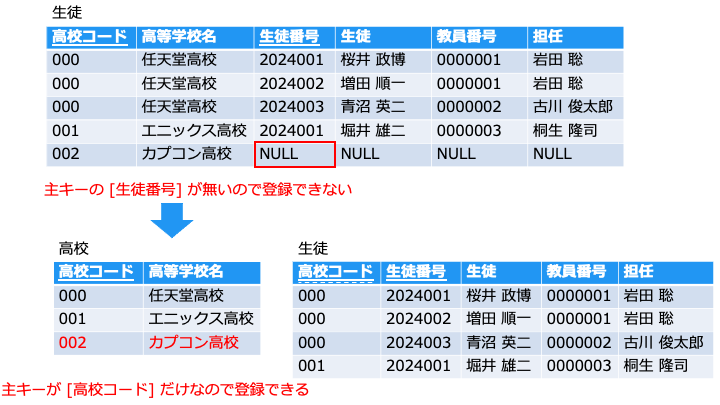
複合主キーの一部によって値が決定する (部分関数従属) 場合は、テーブルを分けます。
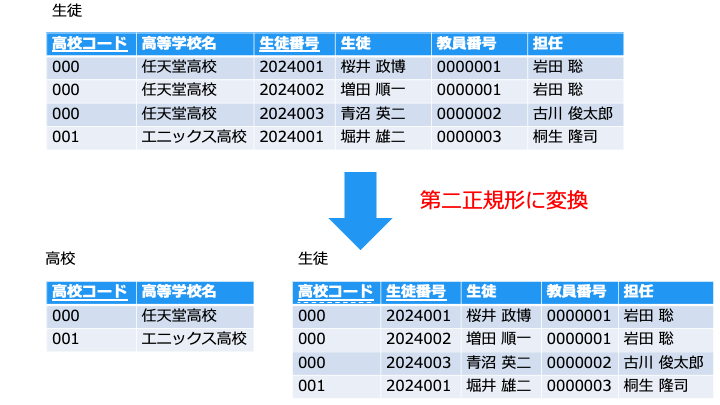
例えば、[高等学校名] は、主キーの [生徒番号] に一切関係なく、[高校コード] によって決まるのでテーブルを分けます。
第二正規系のメリット
これにより、まだ [生徒] の居ない新規の高校もテーブルに登録できます。
正規化は無損失分解なので、以下のように JOIN することで元のテーブルに戻せます。
高校.高等学校名,
生徒.生徒番号,
生徒.生徒,
生徒.教員番号,
生徒.担任
FROM 高校 INNER JOIN 生徒
ON 高校.高校コード = 生徒.高校コード;
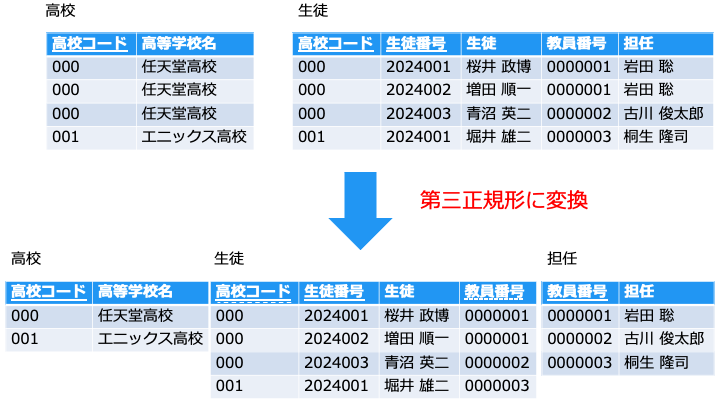
例えば、[担任] は主キー以外でも、[教員番号] で一意に特定できるので、テーブルを分けます。
第三正規形のメリット
担任が決まったが、まだ生徒が決まっていない場合でも担任を登録できます。
また、無損失分解なので、JOIN で元のテーブルに戻せます。
正規化の問題点
- SQL が複雑になる
- 検索パフォーマンスが劣化する
SQL が複雑になる
「任天堂高校の生徒数は何人ですか」に対する SQL は以下のとおりです。
正規化後
今回はテーブル 2 つの JOIN ですが、数十テーブルの JOIN になると見るだけでうんざりします。
正規化前
FROM 生徒
WHERE 高等学校名 = '任天堂高校';
テーブル名の指定や JOIN が要らないので、すっきりします。
検索パフォーマンスが劣化する
上述したとおり、正規化したテーブルでは検索に JOIN が必要となる場合があります。
JOIN は非常にコストの高い処理であるため、検索時のパフォーマンスが低下します。
では正規化は不要か?
正規化はすべきです。
今まで紹介したとおり、正規化では、データの重複や不整合を排除できます。
「非正規化」はあくまでも最後の手段であるという姿勢でのぞむ、というものだ。要するに、十分に正規化された設計をあきらめてもよいのは、パフォーマンスを向上させるためのその他すべての戦略が要件を満たさない場合だけである。
C.J.Date「データベース実践講義」(オライリー・ジャパン、2006) p.164
また、重複を排除するので、更新時のパフォーマンスは正規化した方が良くなります。
例えば、[高等学校名] を変更する場合、正規化後の方が更新する行数が少なくなります。
関連記事
| 学習ロードマップ | |||||
|---|---|---|---|---|---|
| 関連記事:データベースの基礎知識編 | |||||
|---|---|---|---|---|---|



| 関連記事:データベース設計 | |||||
|---|---|---|---|---|---|