
クエリチューニングのために、「クエリを実行してから結果を取得するまで」の流れを紹介します。
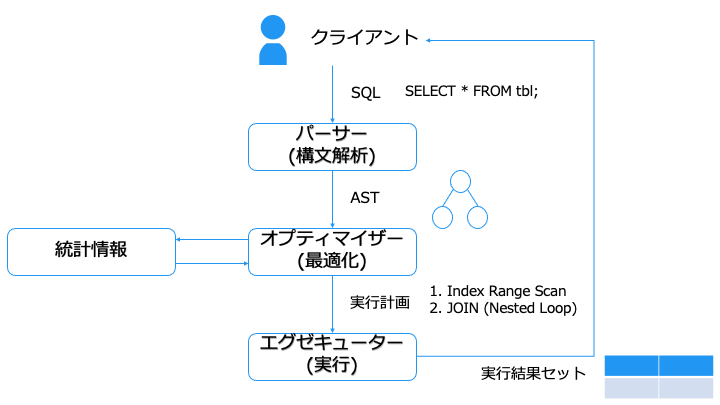
クエリチューニングの際には、実行計画を確認したり、統計情報を更新します。
| 関連記事:データベースの基礎知識編 | |||||
|---|---|---|---|---|---|



| 学習ロードマップ | |||||
|---|---|---|---|---|---|






パーサー(Parser)とは
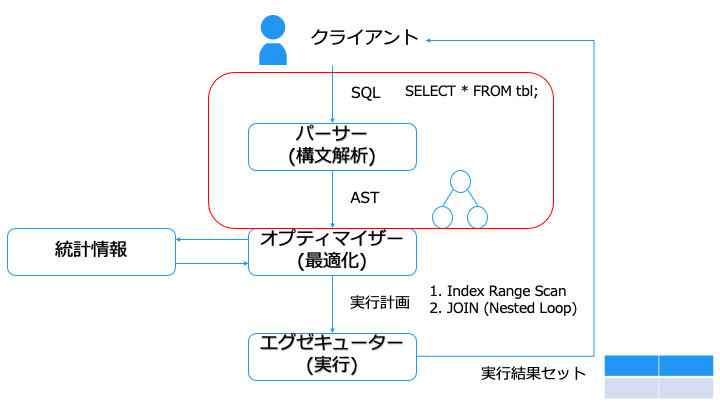
パーサーは、主に以下の役割を持ちます。
- 構文/テーブルやカラムの存在/アクセス権限のチェック
- SQL クエリからクエリツリーを生成
構文/テーブルの存在/アクセス権限のチェック
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'FRO tbl' at line 1
ERROR 1146 (42S02): Table 'db.tbl2' doesn't exist
ERROR 1142 (42000): SELECT command denied to user 'hogetech'@'localhost' for table 'tbl3'
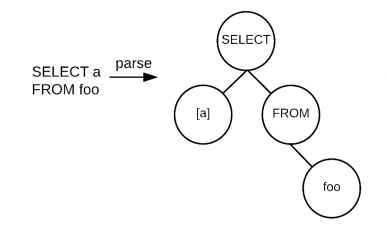
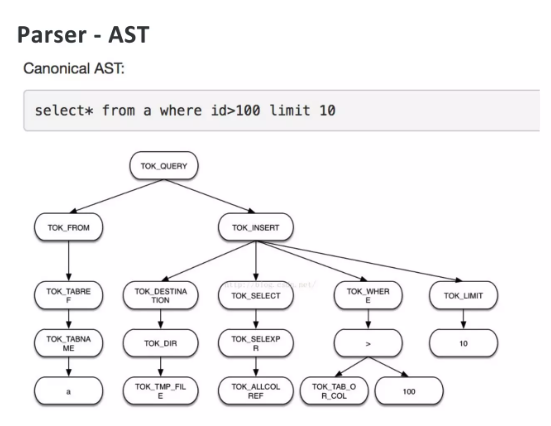
クエリツリーの生成
SQL 文を、データベースが処理しやすい AST (抽象構文木) に変換します。
実行計画とは
オプティマイザーの説明に入る前に、出力の実行計画を事前知識として説明します。
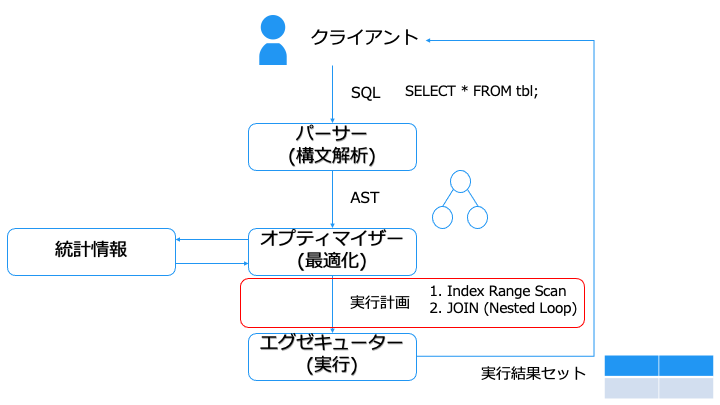
実行計画では、主に以下の 2 つの手順を決定します。
アクセスパス (Access Path)
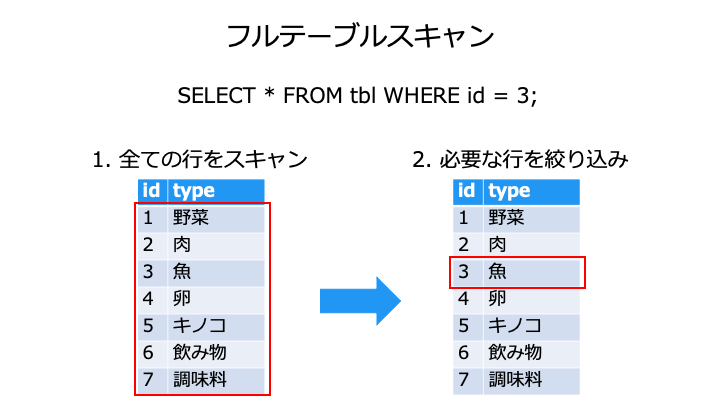
アクセスパス (Access Path) には、フルテーブルスキャンとインデックススキャンがあります。
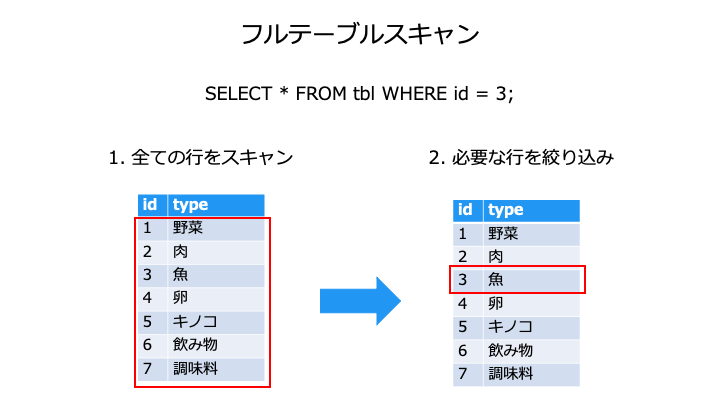
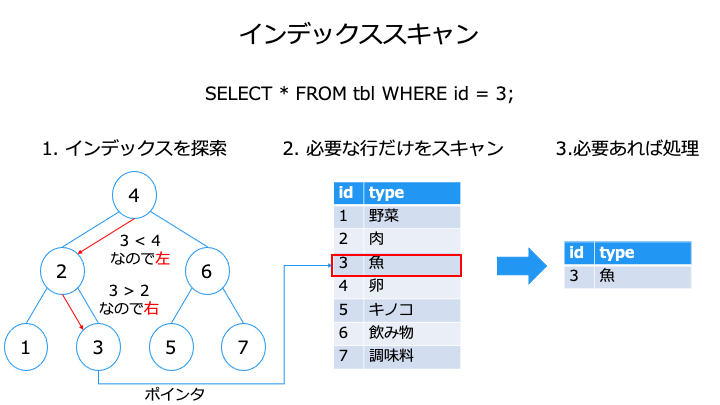
インデックスの詳細については、以下の記事をご覧ください。
フルテーブルスキャンとインデックスの比較
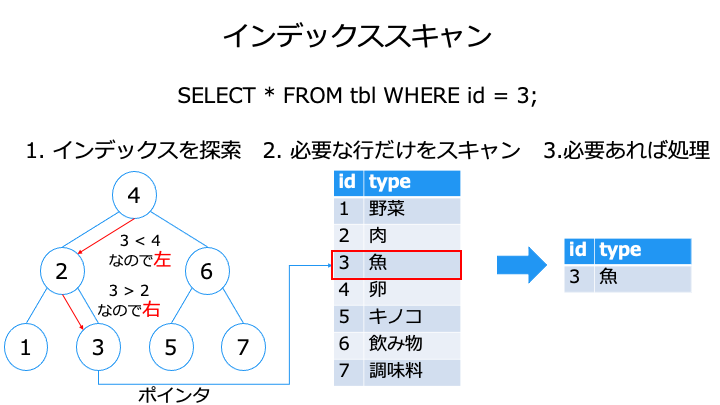
| フルテーブルスキャン | インデックススキャン | |
|---|---|---|
| 読み込み速度 | 低速 上記の例では 7 行をスキャン | 高速 ※1 上記の例では 3 回探索 + 1 行をスキャン |
| 書き込み速度 | 普通 | 低速 データと別に、インデックスも更新するため |
| ソート | スキップ不可 | スキップ可能 ※2 |
※2 インデックスはソートされているため。インデックス以外はソートする必要あり
結合方法 (JOIN Method)
結合方法には主に以下の3つのアルゴリズムが存在します。
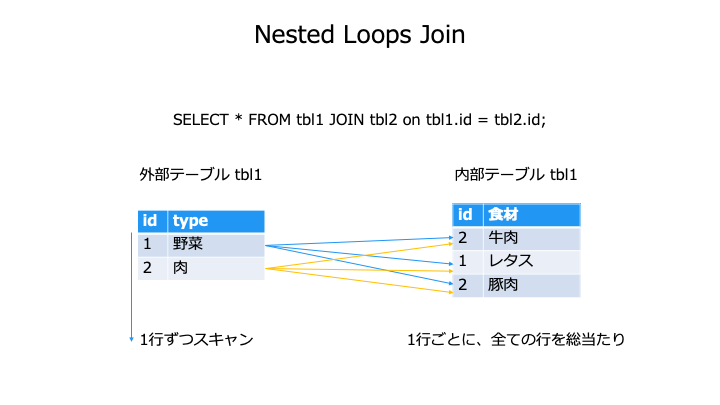
最悪計算量は O(M * N)、内部テーブルにインデックスを使った場合は O(M log(N))。(外部テーブル M 行、内部テーブル N 行)
パフォーマンスについて
ネステッドループ結合は、内部/外部テーブルの選択がパフォーマンスに影響します。
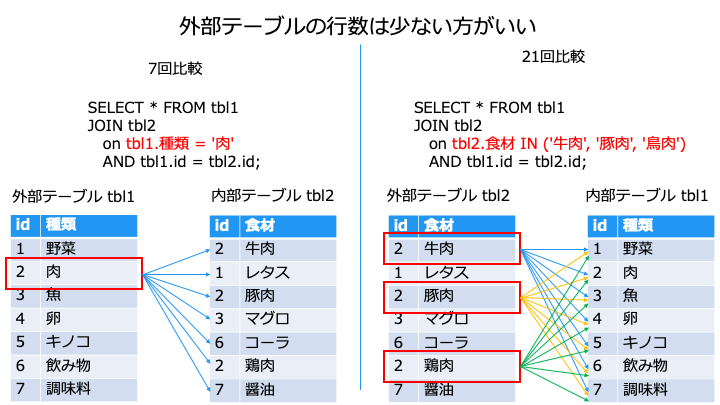
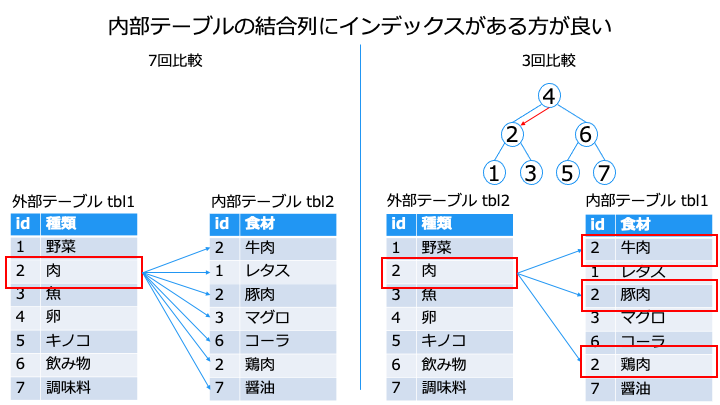
今のオプティマイザーは、どのテーブルを外部/内部テーブルにするか判断します。
(昔は FROM 句のテーブルが外部テーブルだったり、そうじゃなかったり)
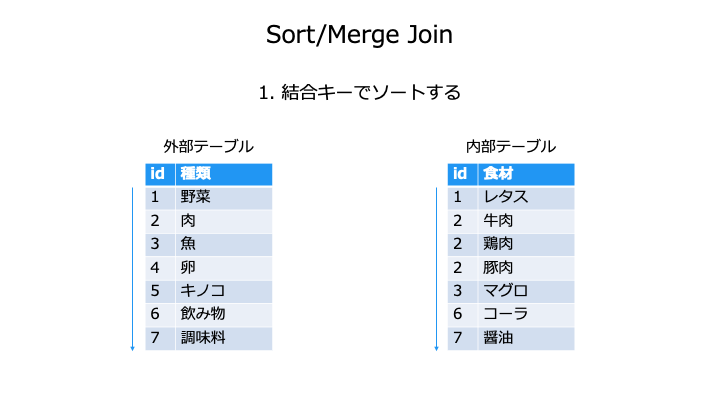
これを外部テーブルと内部テーブルで行うので、Sort/Merge の計算量は O(N log(N) + M log(M))
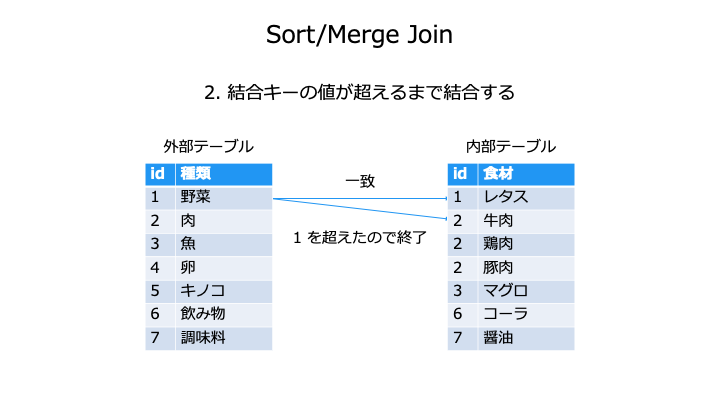
ソートしてない場合、ソート計算量が大半を占めるので O(N log(N) + M log(M)) となる。O(M + N) は無視できるサイズ
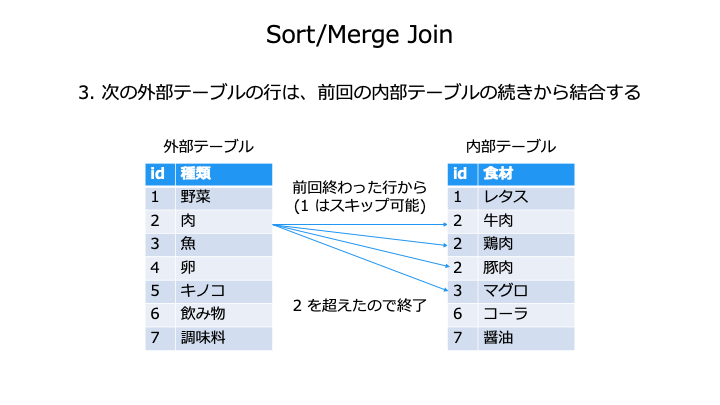
ソートにより、ネステッドループような全行チェックをスキップできます。
ソートマージの利用用途
ソート/マージ結合の利用用途は以下のとおりです。
| 利用シーン | 説明 |
|---|---|
| 大きい (行数の多い) テーブルを結合 | スキップできる行数が増えやすい 逆に行数が少ないと、ソートのオーバーヘッドが 処理の大部分を占める |
| ソート済みのデータに効率的 | ソートフェーズをスキップできるため |
| 結合条件が非等価結合(<, <=, >, >=) | ソートしているため、非常に高速 |
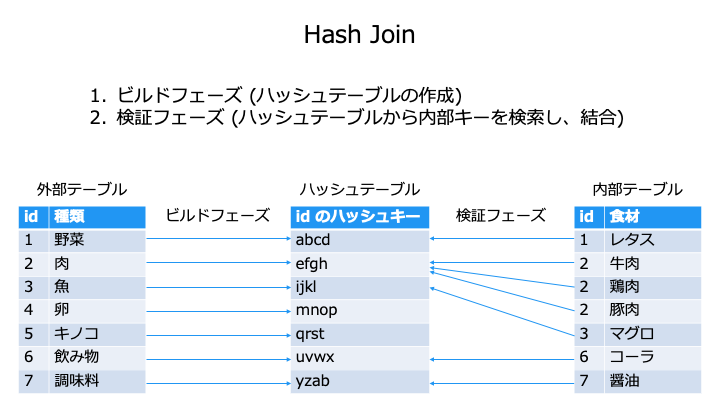
オプティマイザーは、小さいテーブルの方でハッシュテーブルを作ります。
(ハッシュテーブルを小さくするため)
ハッシュ結合の利用例
ハッシュ結合の利用シーンは以下のとおりです。
| 利用シーン | 説明 |
|---|---|
| インデックスが無い | 結合キーにインデックスが無くても、ハッシュテーブルで高速に結合 |
| 小さいテーブルと 大きいテーブルを結合 | 小さいテーブルを選んで小さいハッシュテーブルを作成できるため 両方のテーブルが大きい場合、ハッシュテーブルが大きくなる |
| メモリが潤沢 | ハッシュテーブルが大きい場合、スワップが発生して遅くなるため |
| 結合条件が等価結合 (=) | ハッシュ関数の都合上、同じ値しか比較できない |
実行計画の確認 (EXPLAIN)
EXPLAIN 文で、SQL クエリの実行計画を確認可能です。
+-------+------+---------------+------+------+------+----------+--------------------------------------------+ | table | type | possible_keys | key | ref | rows | filtered | Extra | +-------+------+---------------+------+------+------+----------+--------------------------------------------+ | tbl2 | ALL | NULL | NULL | NULL | 3 | 100.00 | NULL | | tbl1 | ALL | NULL | NULL | NULL | 5 | 20.00 | Using where; Using join buffer (hash join) | +-------+------+---------------+------+------+------+----------+--------------------------------------------+
| 実行計画の手順 | 対応する EXPLAIN の表示 |
|---|---|
| アクセスパス (Access Path) | type: ・ALL はフルテーブルスキャン、 ・range や index はインデックススキャン インデックスで利用した列は key で確認 |
| 結合方法 (JOIN Method) | Extra: ・Using join buffer (hash join) はハッシュ結合 |
MySQL の EXPLAIN の詳細な見方は、以下のドキュメントをご覧ください。

オプティマイザー (Optimizer) とは
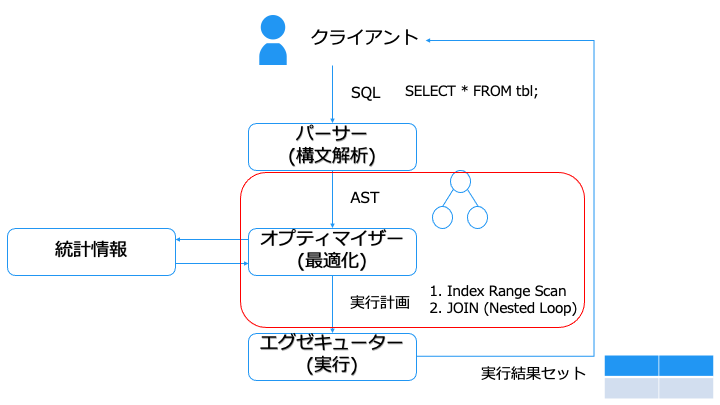
オプティマイザーは、実行計画の候補を複数生成し、実行コストの低い実行計画を選択します。
オプティマイザーは以下の3つの要素で構成されます。
- クエリトランスフォーマー (リライターとも。オプティマイザーと独立している場合もある)
- プランジェネレーター
- エスティメーター
例えば、結合処理を減らすために、絞り込みを先に行うように書き換えます。
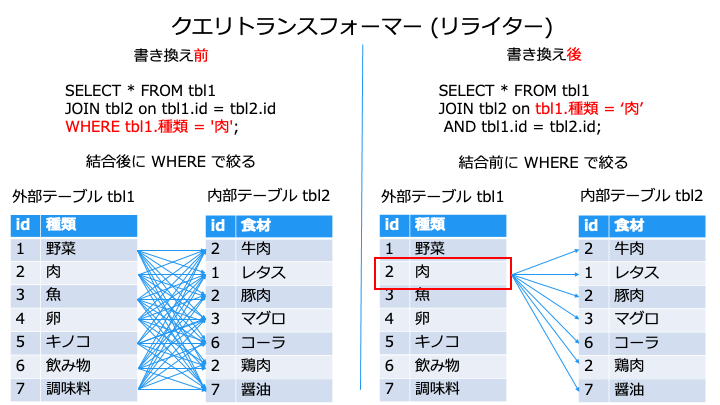
JOIN 句 --> WHERE の順で実行されるので、JOIN 句で絞り込むように書き換える
https://ryuichi1208.hateblo.jp/entry/2022/11/13/103003
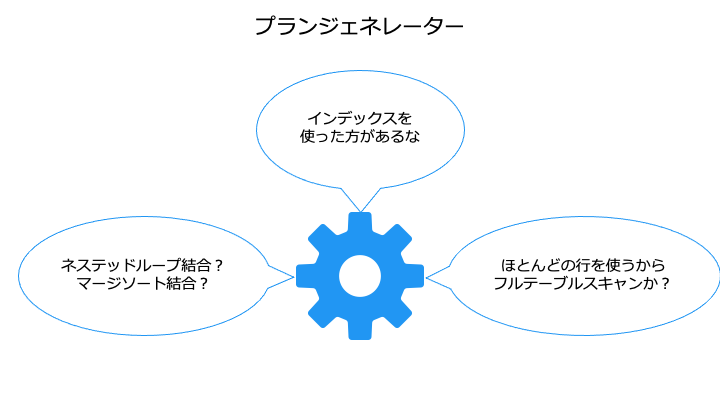
ようするに、以下のように一番速い実行方法を算出するものです。
- プランジェネレーターで生成した実行計画の候補の中で、どれが一番速いか?
- クエリトランスフォーマーで「書き換えた後と「書き換える前」でどっちが速いか?
エスティメーターは、リソース (CPU, メモリ, I/O) や統計情報などで実行コストを推定します。
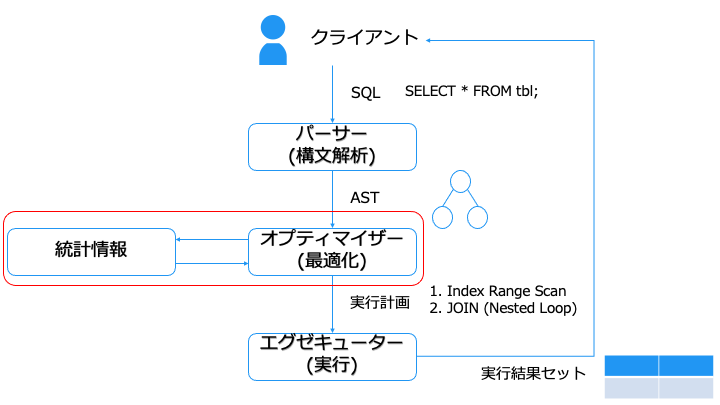
統計情報は mysql.innodb_table_stats(MySQL) や pg_stat_user_tables(PostgreSQL) などで確認できます。
永続統計は、
mysql.innodb_table_statsテーブルおよびmysql.innodb_index_statsテーブルに格納されます。[1]非永続オプティマイザ統計は、次の場合に更新されます:
[1] https://dev.mysql.com/doc/refman/8.0/ja/innodb-persistent-stats.htmlSHOW TABLE STATUS、SHOW INDEXを実行するか、...(省略)[2]
[2] https://dev.mysql.com/doc/refman/8.0/ja/innodb-statistics-estimation.html
+---------------+------------+---------------------+--------+----------------------+--------------------------+ | database_name | table_name | last_update | n_rows | clustered_index_size | sum_of_other_index_sizes | +---------------+------------+---------------------+--------+----------------------+--------------------------+ | db | tbl1 | 2024-09-29 09:59:27 | 5 | 1 | 0 | +---------------+------------+---------------------+--------+----------------------+--------------------------+
統計情報には、主に以下のような情報が含まれまれていることが確認できます。
他にも、SHOW TABLE STATUS で行の長さを、SHOW INDEX でカーディナリティを見れます。
また、統計情報は以下のコマンドで更新できます。
なお、統計情報はテーブル内の全てのページを確認しているわけではありません。
(フルテーブルスキャンをすると、データベースが重くなるため)
適当にいくつかのページをサンプリングして、全てのページの統計情報を推測しています。
エグゼキューター
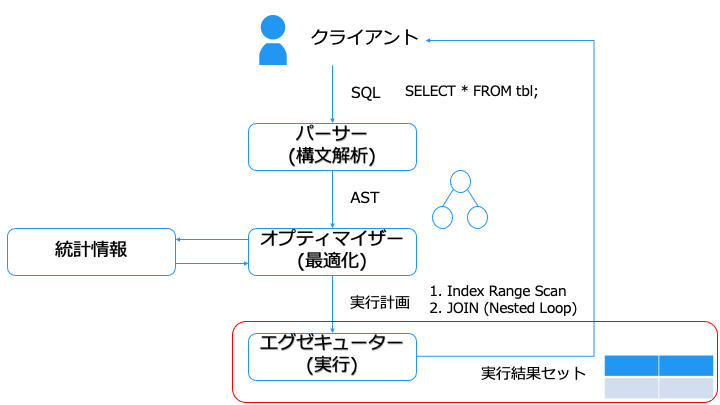
エスティメーターを元に実行計画を 1 つに絞ったら、エグゼキューターで実行します。
実行計画に従ってストレージにアクセスしたり、JOIN することで生成した結果セットをクライアントに返せば、SQL の実行は完了となります。
関連記事
| 学習ロードマップ | |||||
|---|---|---|---|---|---|
| 関連記事:データベース設計 | |||||
|---|---|---|---|---|---|
| 関連記事:データベースの基礎知識編 | |||||
|---|---|---|---|---|---|
参考資料





