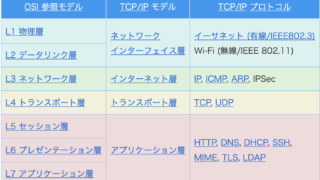
 OSI 参照モデル
OSI 参照モデル 【入門】OSI 参照モデル、TCP/IP モデルの説明と違いを解説
OSI 参照モデルの説明や、TCP/IP モデルとの違いを解説します。
OSI 参照モデル  OSI 参照モデル
OSI 参照モデル 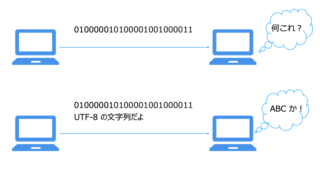 OSI 参照モデル
OSI 参照モデル 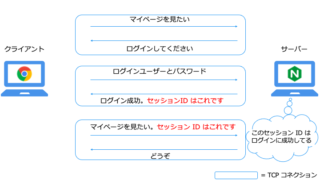 OSI 参照モデル
OSI 参照モデル  システム管理
システム管理