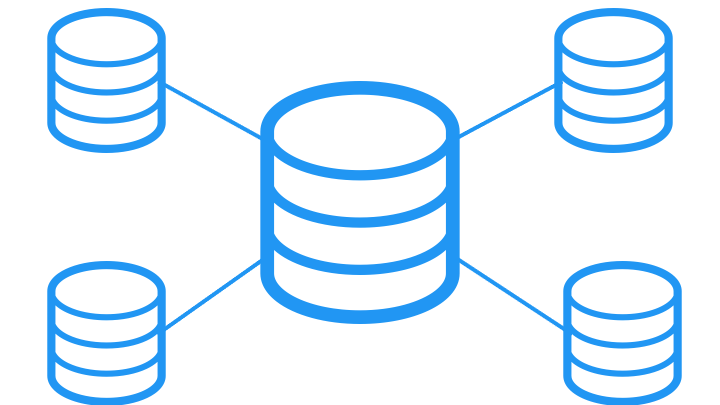
クラスターを構築することで障害に強くしたり、パフォーマンスを向上できます。
シャードの解説から先に読みたい方はこちらをどうぞ。
| 関連記事:データベースの基礎知識編 | |||||
|---|---|---|---|---|---|



| 関連記事:データベース設計 | |||||
|---|---|---|---|---|---|
| 学習ロードマップ | |||||
|---|---|---|---|---|---|




















クラスターの種類
クラスターは目的に応じて、次の 2 種類が存在します。
| クラスターの種類 | クラスターの目的 |
|---|---|
| HPC (High Performance Computing) クラスター | パフォーマンス向上 |
| HA (High Availability) クラスター | 可用性 (システムの継続稼働) の向上 |
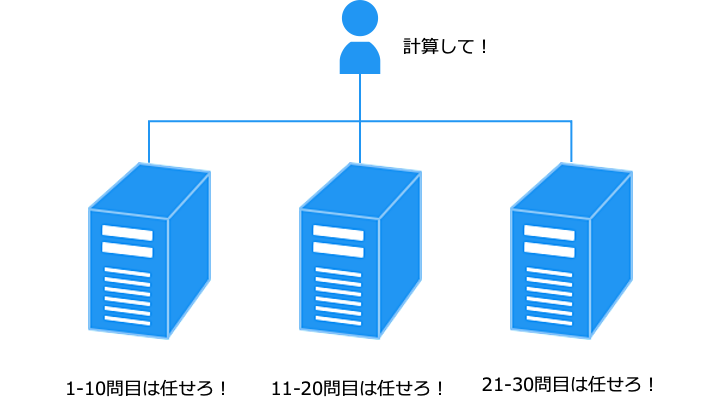
複数のノード (コンピュータ) に処理を分散できるため、早く処理が終わります。

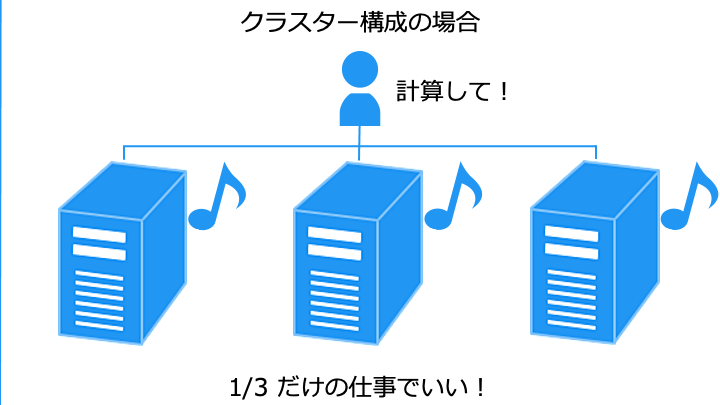
1台が故障しても他のノード (コンピュータ) で処理を継続できます。

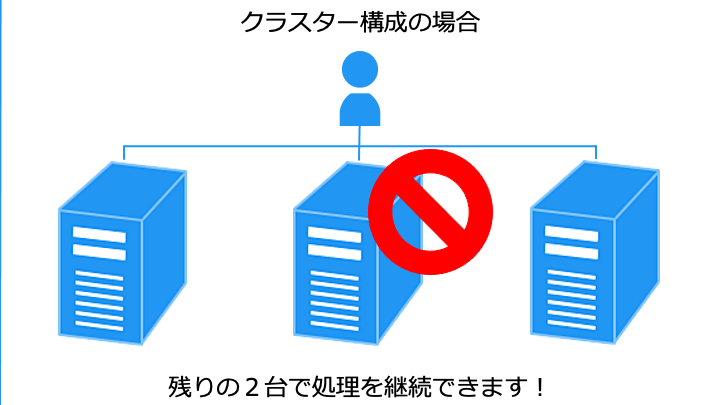
高可用性 (HA) クラスターは、次の2種類の構成が存在します。
※HPC は全ノードで処理を分散するので、アクティブ/アクティブ構成と言えます。
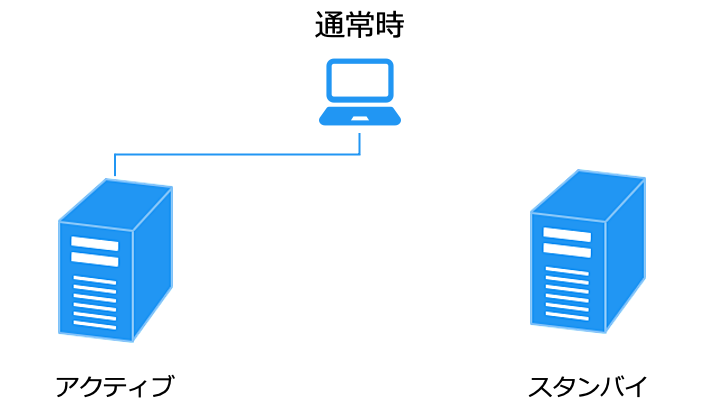
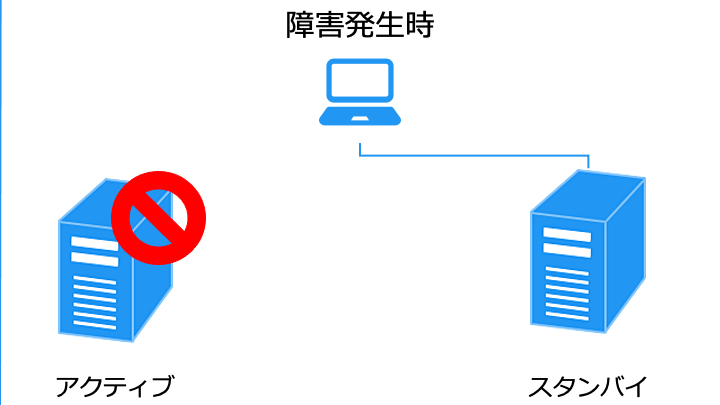
アクティブ/スタンバイ構成は、スタンバイ (待機) 側の状態によって次の 2 種類があります。
コールドスタンバイにする理由は、待機中のデータベースライセンス費をカットできることです。
その代わり、障害が発生してからデータベースを起動するため、切り替えが遅くなります。
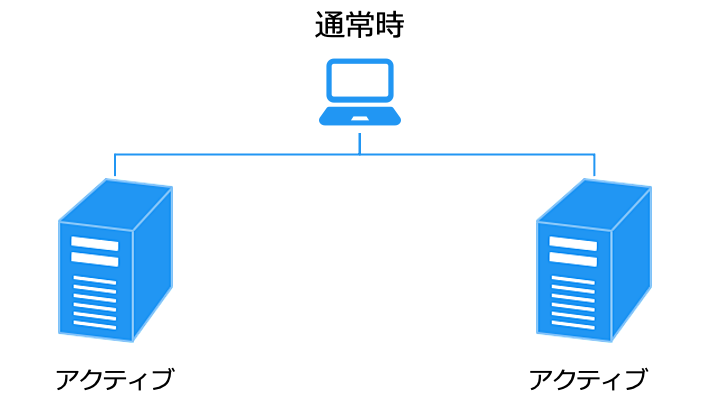
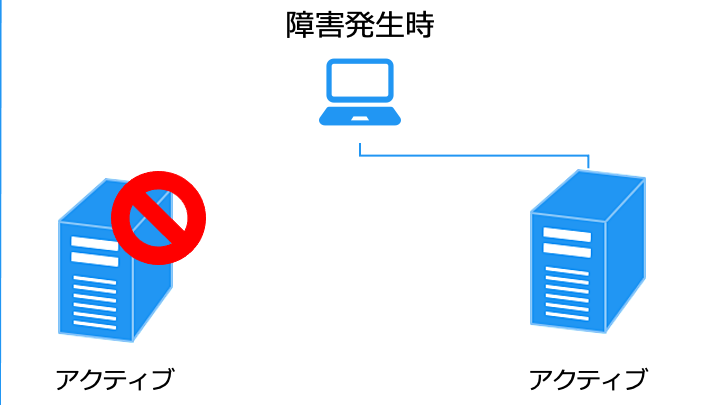
アクティブ/アクティブ構成は、HA クラスターと HPC クラスターの両方の性質を持ちます。
アクティブ/アクティブ構成の実現方法には、次の2種類があります。
| アクティブ/アクティブの種類 | 説明 |
|---|---|
| シェアードエブリシング | ノード間でリソースを共有するクラスター 主にディスクを共有し、シェアードディスクとも呼ぶ |
| シェアードナッシング | ノード間でリソースを共有しないクラスター |
なお、障害発生時は、残ったノードに負荷が集中する点に注意が必要です。
























クラスターを実現する技術
上述のとおり、アクティブ/アクティブクラスターを実現する方法は次の2つです。
- シェアードエブリシング (シェアードディスク/共有ディスク)
- シェアードナッシング
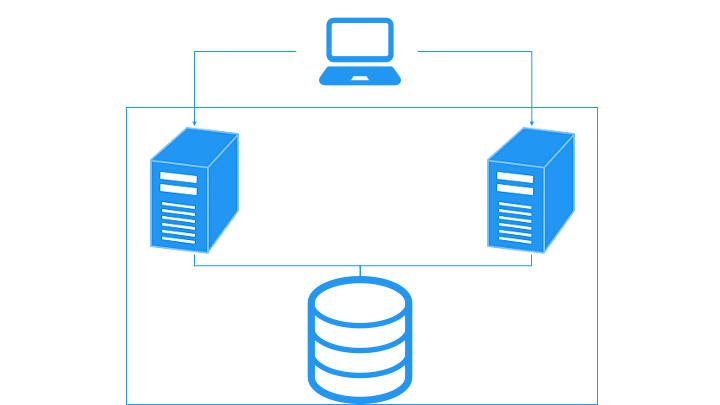
- ✅ ノードを追加することで、CPU やメモリを追加可能
- ✅ ストレージが1箇所なので、データの整合性を気にしなくて良い
- ❌ ストレージが追加できないため、ストレージがボトルネック・単一障害点となる
- ❌ 更新したノードと別のノードは、ストレージとキャッシュの整合性が一時的に無くなる
- ❌ アクティブ/アクティブ構成で同じレコードを更新する場合、ロックが必要
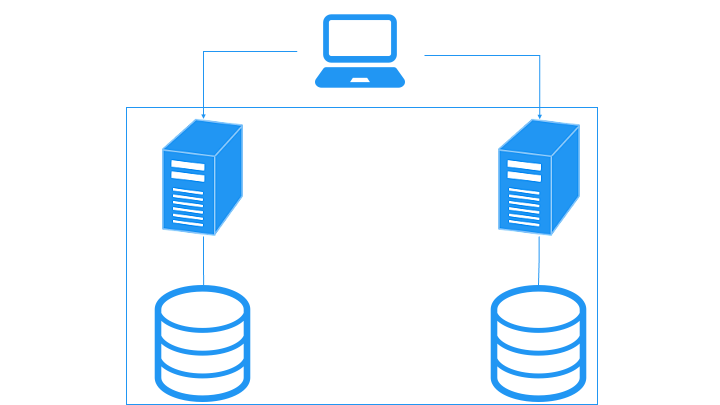
- ✅ ストレージも追加可能なので、ストレージがボトルネック・単一障害点にならない
- ✅ ノード間に影響がほとんどないため、ストレージとキャッシュの整合性がある
- ✅ 別々のストレージを持つため、他のノードからのロックの影響を受けない
- ❌ ストレージが複数あるので、データの整合性を気にする必要がある
- ❌ 別のストレージにあるデータを JOIN する場合、時間がかかる
































シャード
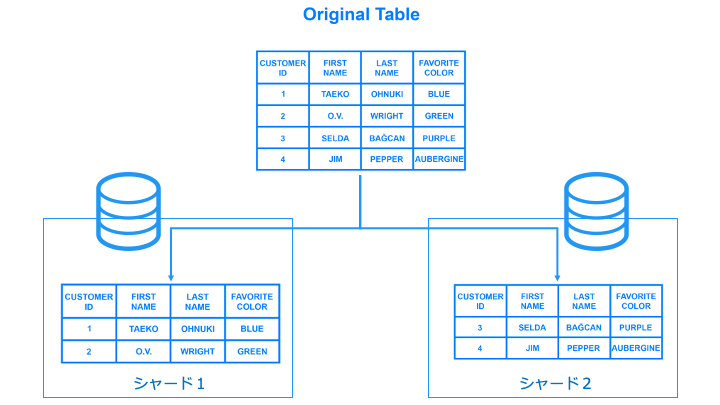
シェアードナッシングでは、データを各ストレージに分散配置するためにシャードを使います。
シャードの種類
シャードの種類には、次の 2 つが存在します。
- プライマリーシャード
- レプリカシャード
レプリカシャードは、プライマリーシャードと別のノードに配置します。
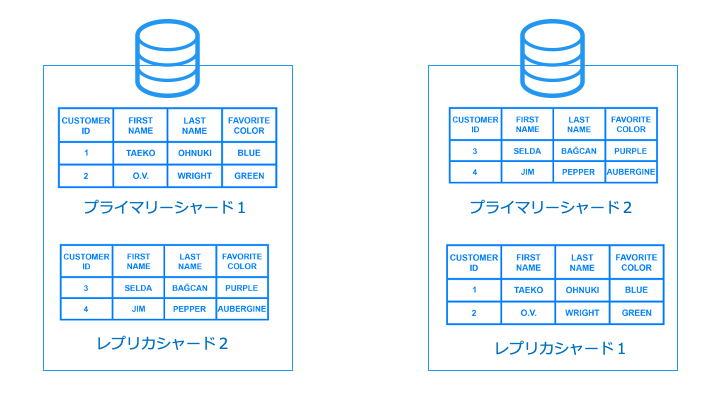
これにより、ストレージ障害に耐性がつき、可用性が向上します。
(つまり、プライマリーシャード = HPC クラスター、レプリカシャード = HA クラスターも実現)
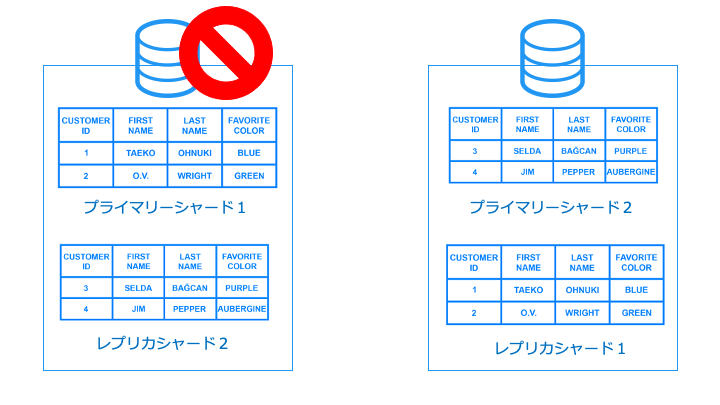
上記では、左のストレージが故障しても、シャード1、2のデータが残っています。
シャーディングの種類
シャーディングには、主に次の3種類が存在します。
- Key Based Sharding
- Range Based Sharding
- Directory Based Sharding
以下の例では、COLUMN1 のハッシュ値に応じて、行を 2 つのシャードに割り当てます。
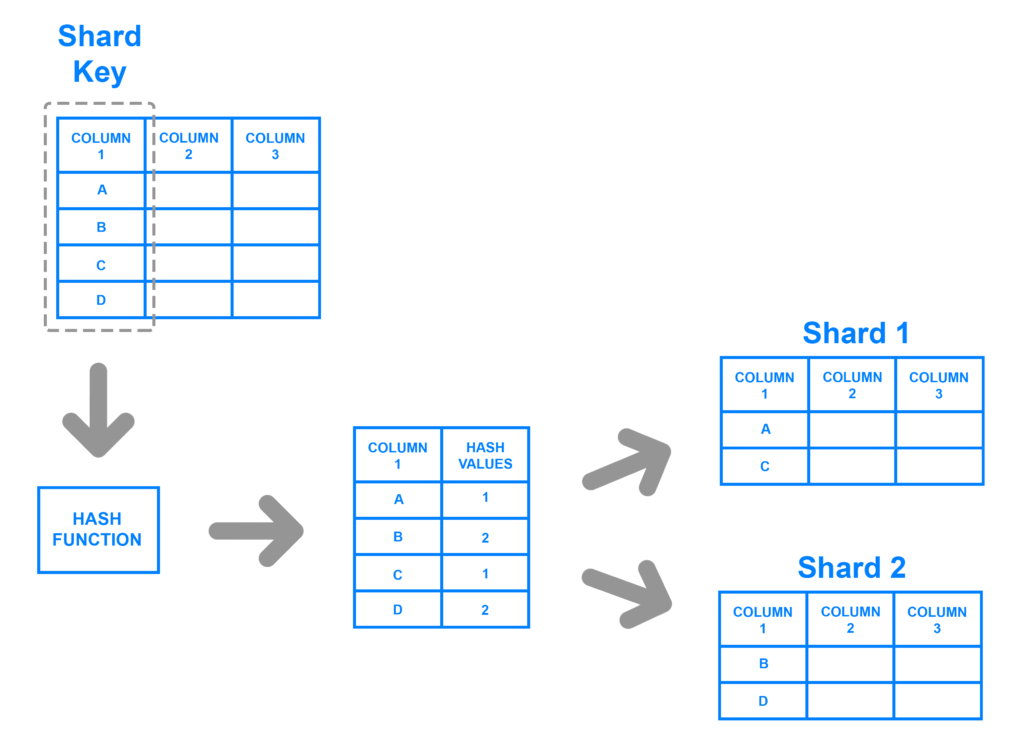
なお、シャードの割り当てに使うカラムは、シャードキーといいます。
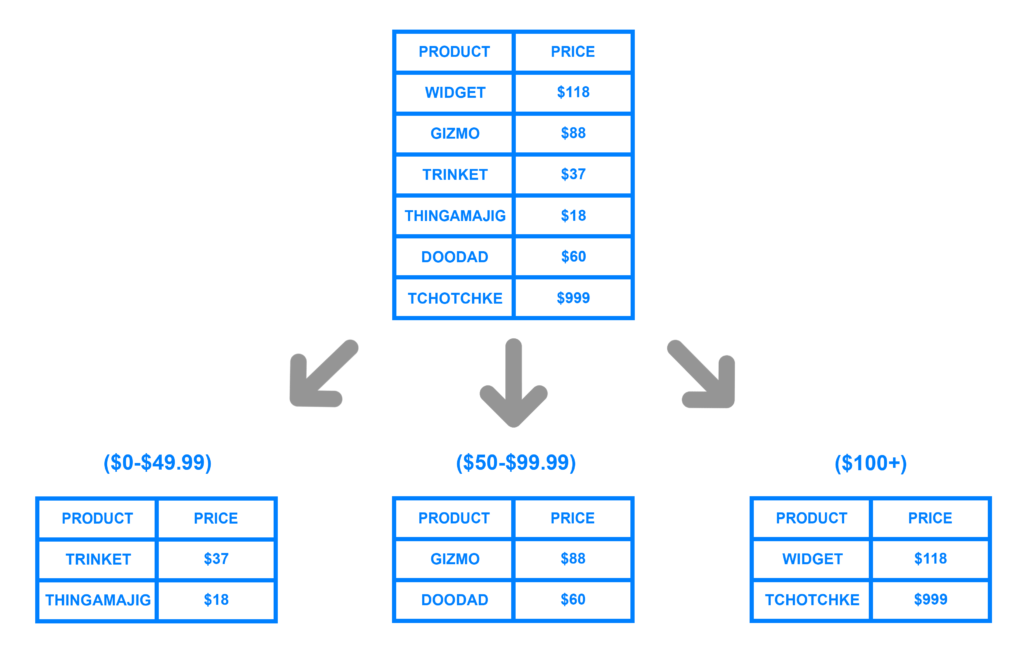
以下の例では、PRICE カラムの値の範囲に応じて、行を 3 つのシャードに割り当てます。
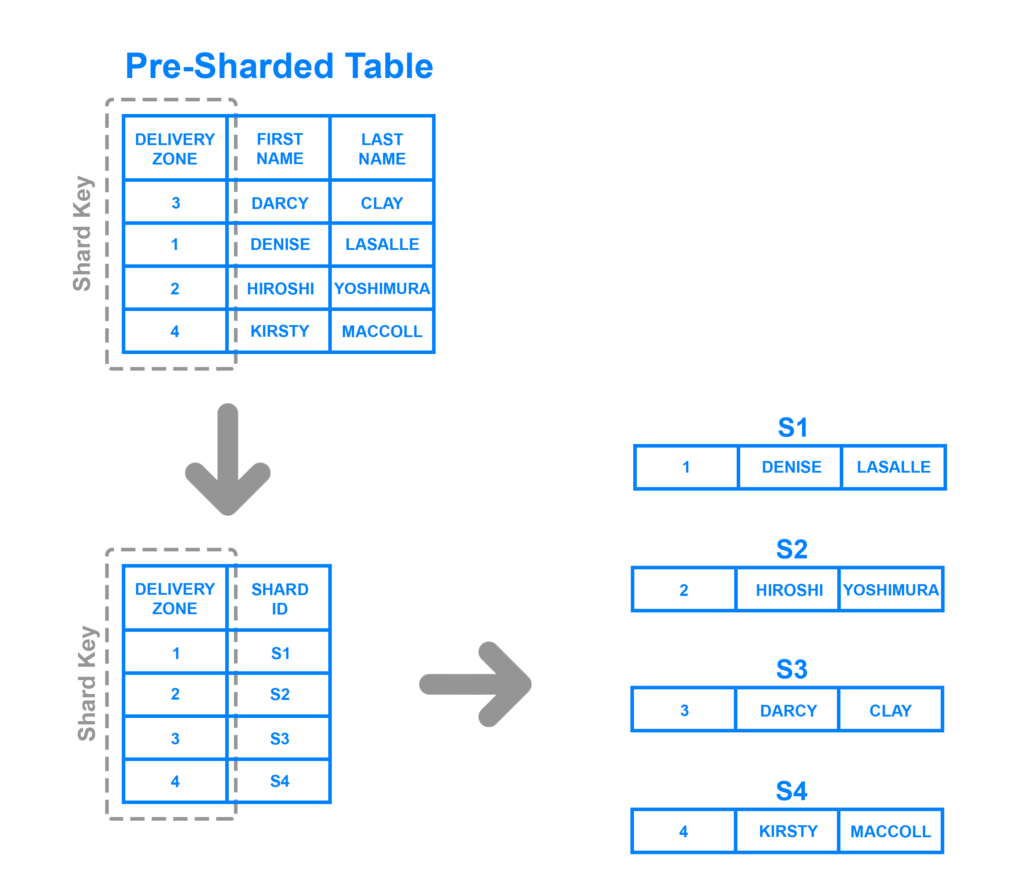
以下の例では、DELIVERY ZONE カラムで、割り当てるシャードを指定しています。
関連記事
| 学習ロードマップ | |||||
|---|---|---|---|---|---|
| 関連記事:データベースの基礎知識編 | |||||
|---|---|---|---|---|---|
| 関連記事:データベース設計 | |||||
|---|---|---|---|---|---|








参考記事
