
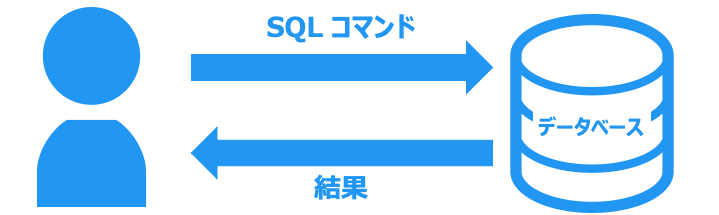
SQL コマンドは、プログラミングをせずにデータベースを操作できるため急速に広まりました。
SQL コマンドは、主に次の4種類が存在します。

本記事は、上からコピペすることで、よく利用する SQL コマンドを理解できる構成にしています。
SQL コマンドの実行環境が無い場合は、以下のいずれかの記事で構築してください。


| 関連記事:データベースの基礎知識編 | |||||
|---|---|---|---|---|---|


| 学習ロードマップ | |||||
|---|---|---|---|---|---|






DDL (Data Definition Language/データ定義言語)
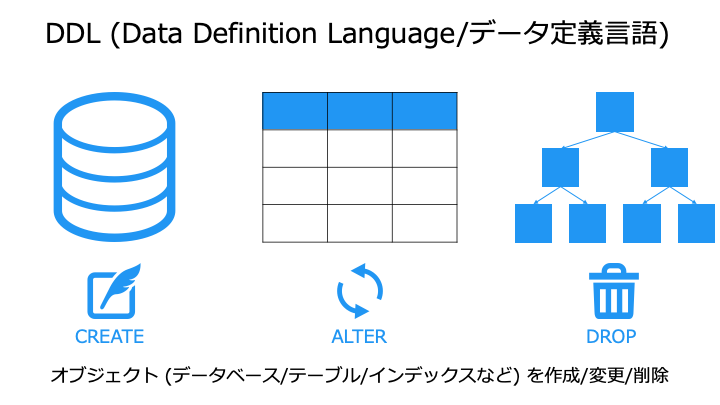
DDL には、主に以下の 3 種類の SQL コマンドが存在します。
CREATE 文 (作成)
CREATE DATABASE データベース名;
+--------------------+ | Database | +--------------------+ | db | | information_schema | | mysql | | performance_schema | | sys | +--------------------+
PostgreSQL でデータベースを確認する場合
List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+-------------+-------------+----------------------- db | postgres | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 | postgres | postgres | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 |
データベース (db) が作成できていることが確認できます。
以降、データベース (db) を使用するために、MySQL では次のコマンドを実行します。
CREATE TABLE テーブル名(列名1 データ型1, 列名2 データ型2...)
+--------------+ | Tables_in_db | +--------------+ | tbl | +--------------+
tbl という名前のテーブルが作成できています。
+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | int | YES | | NULL | | | str | varchar(10) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+
PostgreSQL でテーブルの存在と構造を確認
List of relations Schema | Name | Type | Owner --------+------+-------+---------- public | tbl | table | postgres
tbl という名前のテーブルが作成できています。
Table "public.tbl" Column | Type | Modifiers --------+-----------------------+----------- id | integer | str | character varying(10) |
なお、テーブル・データベース設計は、以下の記事をご覧ください。
| 関連記事:データベース設計 | |||||
|---|---|---|---|---|---|
CREATE USER 'ユーザー名'@'ホスト名' IDENTIFIED BY 'パスワード'
Postgres でユーザーを作成する場合
List of roles
Role name | Attributes | Member of
-----------+------------------------------------------------+-----------
hogetech | | {}
postgres | Superuser, Create role, Create DB, Replication | {}
+----------+-----------+ | user | host | +----------+-----------+ | hogetech | localhost | | mysql.sys| localhost | +----------+-----------+
ユーザーが作成されていることを確認できます。
ALTER 文 (変更)
ALTER TABLE テーブル名 ADD COLUMN 列名;
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| str | varchar(10) | YES | | NULL | |
| add_column | char(5) | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
PostgreSQL でテーブルの構造を確認
Table "public.tbl"
Column | Type | Modifiers
------------+-----------------------+-----------
id | integer |
str | character varying(10) |
add_column | character(5) |
テーブル (tbl) に、列 (add_column) を追加したことが確認できます。
ALTER TABLE テーブル名 RENAME COLUMN 変更前の列名 TO 変更後の列名;
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| str | varchar(10) | YES | | NULL | |
| rename_column | char(5) | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
PostgreSQL でテーブルの構造を確認
Table "public.tbl"
Column | Type | Modifiers
------------+-----------------------+-----------
id | integer |
str | character varying(10) |
rename_column | character(5) |
テーブルの add_column 列を rename_column 列に変更したことが確認できます。
ALTER TABLE テーブル名 DROP COLUMN 列名;
+------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+-------------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | str | varchar(10) | YES | | NULL | | +------------+-------------+------+-----+---------+-------+
PostgreSQL でテーブルの構造を確認
Table "public.tbl" Column | Type | Modifiers ------------+-----------------------+----------- id | integer | str | character varying(10) |
テーブルから rename_column が削除されたことを確認できます。
DROP 文 (削除)
DROP TABLE テーブル名;
Empty set (0.00 sec)
PostgreSQL でテーブルの構造を確認
No relations found.
テーブル(tbl) が削除されたことを確認できます。
DROP DATABASE データベース名;
+--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+
PostgreSQL でテーブルの構造を確認
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 |
template0 | postgres | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
データベース (db) が削除されたことを確認できます。
DROP USER 'ユーザー名'@'ホスト名';
PostgreSQL でユーザーを削除する場合
Role name | (中略)
-----------+-------
postgres | (中略)
hogetech | (中略)
Role name | (中略) -----------+------- postgres | (中略)
DML (Data Manipulation Language/データ操作言語)
DML は、主に CRUD 操作を行う言語です。

DML には、主に以下の 4 種類の SQL コマンドが存在します。
以降に利用するデータベースとテーブル
※ USE db は MySQL のみ。PostgreSQL では不要
INSERT 文 (挿入/作成)
INSERT INTO テーブル名 VALUES(列の値1, 列の値2...)
挿入した結果は、次に紹介する SELECT 文で確認できます。
SELECT 文 (取得/読取)
SELECT 列名 FROM テーブル名
全ての列を取得する場合は * を使います。
+------+------+ | id | str | +------+------+ | 1 | hoge | +------+------+
SELECT 列名 FROM テーブル名 WHERE 条件
+------+------+
| id | str |
+------+------+
| 1 | hoge |
+------+------+
+------+------+ | id | str | +------+------+ | 1 | hoge | | 2 | foo | +------+------+
WHERE 句で、id = 1 の行のみを取得できました。
SELECT DISTINCT 列名 FROM テーブル名
+------+------+
| id | str |
+------+------+
| 1 | hoge |
| 2 | foo |
+------+------+
+------+------+ | id | str | +------+------+ | 1 | hoge | | 2 | foo | | 2 | foo | +------+------+
重複している行が削除されていいます。
SELECT 列名 FROM テーブル名 GROUP BY 集約条件
+------+------+
| id | str |
+------+------+
| 1 | hoge |
| 2 | foo |
+------+------+
+------+------+ | id | str | +------+------+ | 1 | hoge | | 2 | foo | | 2 | foo | +------+------+
重複する行を集約していることが確認できます。
DISTINCT と GROUP BY の違い
DISTINCT と GROUP BY の違いは以下のとおりです。
| DISTINCT | GROUP BY | |
|---|---|---|
| 説明 | 取得した行から、重複を削除 | 取得した行を、グループ化して集計 |
| 重複削除 | ◯ | △ (できるが、全ての列を書く必要があり面倒) |
| 集計関数 | × | ◯ |
今回は、合計を求める集計関数 SUM() を例に説明します。(集計関数の一覧はこちら)
+------+---------+
| str | SUM(id) |
+------+---------+
| foo | 4 |
| hoge | 1 |
+------+---------+
+------+------+ | id | str | +------+------+ | 1 | hoge | | 2 | foo | | 2 | foo | +------+------+
同じ str を持つ id の合計が表示されます。
SELECT 列名 FROM テーブル名 GROUP BY 集約条件 HAVING 表示条件
+------+------+
| id | str |
+------+------+
| 2 | foo |
+------+------+
+------+------+
| id | str |
+------+------+
| 1 | hoge |
| 2 | foo |
+------+------+
HAVING で指定した id = 2 のみを取得できます。
HAVING と WHERE の違い
HAVING と WHERE は式の評価順が異なります。
句の式の評価順は以下のとおりです。
- WHERE
- GROUP BY (集計関数)
- HAVING
そのため、GROUP BY を使う場合は HAVING、それ以外は WHEREを使います。
SELECT Window 関数() OVER() FROM テーブル名
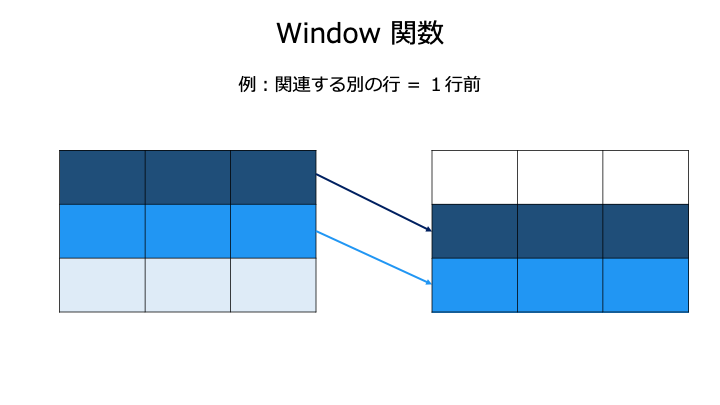
今回は、前の行を取得する LAG() を例に説明します。(Window 関数の一覧はこちら)
+------+----------------+ | id | LAG(id) OVER() | +------+----------------+ | 1 | NULL | | 2 | 1 | | 2 | 2 | +------+----------------+
LAG(id) は、id の1行前の値を表示していることがわかります。
集計関数と Window 関数
集計関数に OVER() をつけると、Window 関数になります。
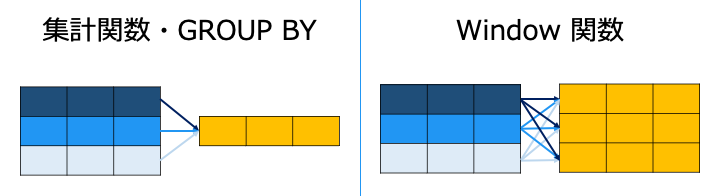
集計関数は行を集約しますが、Window 関数は行を集約しません。
+-----------+ | COUNT(id) | +-----------+ | 3 | +-----------+
+------------------+ | COUNT(id) OVER() | +------------------+ | 3 | | 3 | | 3 | +------------------+
※ COUNT() は行数を数えます。Window 関数は行ごとに COUNT の結果を表示します。
SELECT Window 関数 OVER() FROM テーブル名 WINDOW Window名 AS (OVER の条件)
WINDOW は、同じ OVER の条件を使い回す場合に使います。
id,
LAG(id) OVER (ORDER BY id),
LAG(str) OVER (ORDER BY id)
FROM tbl;
id,
LAG(id) OVER w,
LAG(str) OVER w
FROM tbl
WINDOW w AS (ORDER BY id);
どちらも同じ結果となります。
+------+----------------------------+-----------------------------+ | id | LAG(id) OVER (ORDER BY id) | LAG(str) OVER (ORDER BY id) | +------+----------------------------+-----------------------------+ | 1 | NULL | NULL | | 2 | 1 | hoge | | 2 | 2 | foo | +------+----------------------------+-----------------------------+
SELECT 列名 FROM テーブル名 ORDER BY 条件
+------+------+ | id | str | +------+------+ | 1 | hoge | | 2 | foo | | 2 | foo | +------+------+
+------+------+ | id | str | +------+------+ | 2 | foo | | 2 | foo | | 1 | hoge | +------+------+
SELECT 列名 FROM テーブル名 LIMIT 行数
+------+------+ | id | str | +------+------+ | 1 | hoge | | 2 | foo | +------+------+
+------+------+ | id | str | +------+------+ | 1 | hoge | | 2 | foo | | 2 | foo | +------+------+
2行しか表示されなくなりました。
INSERT INTO 挿入先テーブル名 SELECT 列名 FROM ソーステーブル名
+------+------+ | id | str | +------+------+ | 1 | hoge | | 2 | foo | | 2 | foo | +------+------+
SELECT 列名 FROM テーブル名1 JOIN テーブル名2
JOIN には次の 5 種類が存在し、SELECT, UPDATE, DELETE 文で利用できます。
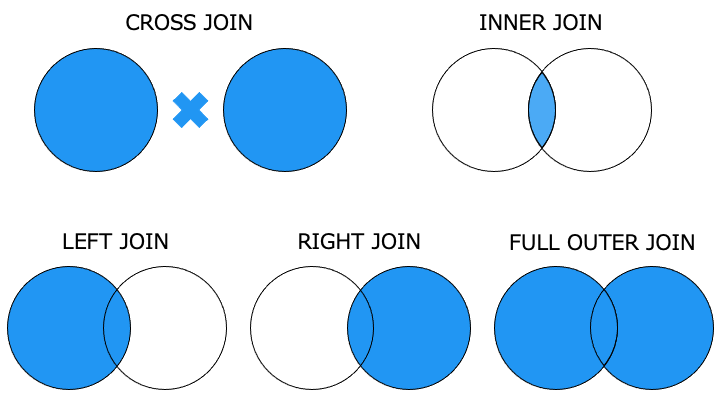
以降の JOIN の説明では、以下のテーブルを使います。
+------+------+------+----------+ | id | str | id | str | +------+------+------+----------+ | 1 | hoge | 1 | 1another | | 2 | foo | 1 | 1another | | 2 | foo | 1 | 1another | | 1 | hoge | 2 | 2another | | 2 | foo | 2 | 2another | | 2 | foo | 2 | 2another | | 1 | hoge | 3 | 3another | | 2 | foo | 3 | 3another | | 2 | foo | 3 | 3another | +------+------+------+----------+
+------+------+
| id | str |
+------+------+
| 1 | hoge |
| 2 | foo |
| 2 | foo |
+------+------+
+------+----------+
| id | str |
+------+----------+
| 1 | 1another |
| 2 | 2another |
| 3 | 3another |
+------+----------+
+------+------+------+----------+ | id | str |id | str | +------+------+------+----------+ | 1 | hoge | 1 | 1another | | 2 | foo | 2 | 2another | | 2 | foo | 2 | 2another | +------+------+------+----------+
+------+------+
| id | str |
+------+------+
| 1 | hoge |
| 2 | foo |
| 2 | foo |
+------+------+
+------+----------+
| id | str |
+------+----------+
| 1 | 1another |
| 2 | 2another |
| 3 | 3another |
+------+----------+
+------+------+------+----------+ | id | str | id | str | +------+------+------+----------+ | 1 | hoge | 1 | 1another | | 2 | foo | 2 | 2another | | 2 | foo | 2 | 2another | +------+------+------+----------+
+------+------+
| id | str |
+------+------+
| 1 | hoge |
| 2 | foo |
| 2 | foo |
+------+------+
+------+----------+
| id | str |
+------+----------+
| 1 | 1another |
| 2 | 2another |
| 3 | 3another |
+------+----------+
+------+------+------+----------+ | id | str | id | str | +------+------+------+----------+ | 1 | hoge | 1 | 1another | | 2 | foo | 2 | 2another | | 2 | foo | 2 | 2another | | NULL | NULL | 3 | 3another | +------+------+------+----------+
+------+------+
| id | str |
+------+------+
| 1 | hoge |
| 2 | foo |
| 2 | foo |
+------+------+
+------+----------+
| id | str |
+------+----------+
| 1 | 1another |
| 2 | 2another |
| 3 | 3another |
+------+----------+
※MySQL では、現時点で FULL OUTER JOIN がサポートされていません。
id | str | id | str
----+------+----+----------
1 | hoge | 1 | 1another
2 | foo | 2 | 2another
2 | foo | 2 | 2another
| | 3 | 3another
+------+------+
| id | str |
+------+------+
| 1 | hoge |
| 2 | foo |
| 2 | foo |
+------+------+
+------+----------+
| id | str |
+------+----------+
| 1 | 1another |
| 2 | 2another |
| 3 | 3another |
+------+----------+
SELECT 列名1 FROM テーブル名1 UNION SELECT 列名2 FROM テーブル名2
+------+----------+ | id | str | +------+----------+ | 1 | hoge | | 2 | foo | | 1 | 1another | | 2 | 2another | | 3 | 3another | +------+----------+
+------+------+
| id | str |
+------+------+
| 1 | hoge |
| 2 | foo |
| 2 | foo |
+------+------+
+------+----------+
| id | str |
+------+----------+
| 1 | 1another |
| 2 | 2another |
| 3 | 3another |
+------+----------+
UNION は重複が排除されます。重複を含む場合は、UNION ALL を利用します。
+------+----------+ | id | str | +------+----------+ | 1 | hoge | | 2 | foo | | 2 | foo | | 1 | 1another | | 2 | 2another | | 3 | 3another | +------+----------+
SELECT 列名1 FROM テーブル名1 WHERE 列名1 = (SELECT 列名2 FROM テーブル名2);
A query is a synonym for a SELECT statement.
https://stackoverflow.com/questions/4735856/difference-between-a-statement-and-a-query-in-sql
A statement is any SQL command such as SELECT, INSERT, UPDATE, DELETE.
Queries, which retrieve data based on specific criteria.
Statements, which may have a persistent effect on schemas and data, or which may control transactions, program flow, connections, sessions, or diagnostics.
クエリー
SQL で、1 つ以上のテーブルから情報を読み取る操作。歴史的な理由から、ステートメントの内部処理のディスカッションでは、DDL ステートメントや DML ステートメントなどの他のタイプの MySQL ステートメントを含む、より広範な意味で 「query」 が使用される場合があります。
https://dev.mysql.com/doc/refman/8.0/ja/glossary.html#glos_query
+------+------+
| id | str |
+------+------+
| 1 | hoge |
+------+------+
+------+------+
| id | str |
+------+------+
| 1 | hoge |
| 2 | foo |
| 2 | foo |
+------+------+
+------+----------+
| id | str |
+------+----------+
| 1 | 1another |
| 2 | 2another |
| 3 | 3another |
+------+----------+
UPDATE テーブル名 SET 列名=値 WHERE 条件
+------+------+
| id | str |
+------+------+
| 1 | hoge |
| 2 | foo |
| 2 | foo |
+------+------+
+------+--------+
| id | str |
+------+--------+
| 1 | update |
| 2 | foo |
| 2 | foo |
+------+--------+
DELETE FROM テーブル名 WHERE 行の条件
+------+--------+ | id | str | +------+--------+ | 1 | update | | 2 | foo | | 2 | foo | +------+--------+
+------+--------+ | id | str | +------+--------+ | 1 | update | +------+--------+
DCL (Data Control Language/データ制御言語)
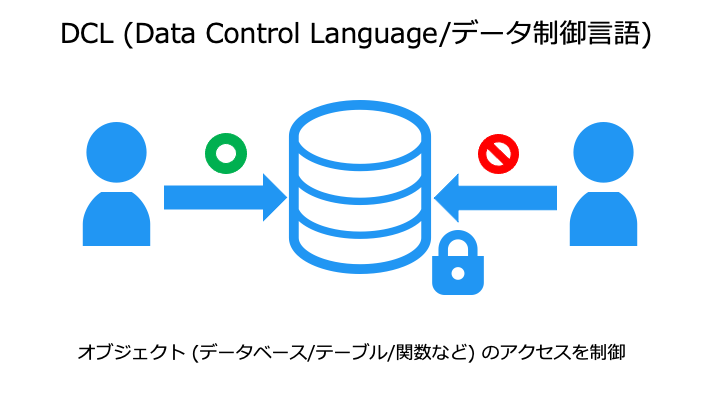
DCL には、主に以下の 2 種類の SQL コマンドが存在します。
- GRANT (ユーザーに権限を与える)
- REVOKE (ユーザーから権限を取り消す)
GRANT 権限 ON 権限レベル TO 'ユーザー'@'ホスト'
Postgres で権限を割り当てる場合
ERROR: ロール"hogetech"は存在しません が発生した場合
ユーザーが存在しない可能性があります。ユーザーを作成してください。
postgres=# \dp
Access privileges
Schema | Name | Type | Access privileges | Column access privileges
--------+---------+-------+---------------------------+--------------------------
public | another | table | |
public | tbl | table | postgres=arwdDxt/postgres+|
| | | hogetech=r/postgres |
public | tbl2 | table | |
別の端末から作成したユーザーでログインし、GRANT の動作確認をしてみます。
ERROR: リレーション tbl への権限がありません
+------+--------+ | id | str | +------+--------+ | 1 | update | +------+--------+
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements が発生した場合
ユーザーが存在しない可能性があります。ユーザーを作成してください。
+------------------------------------------------------+ | Grants for hogetech@localhost | +------------------------------------------------------+ | GRANT USAGE ON *.* TO `hogetech`@`localhost` | | GRANT SELECT ON `db`.`tbl` TO `hogetech`@`localhost` | +------------------------------------------------------+
別の端末から作成したユーザーでログインし、GRANT の動作確認をしてみます。
ERROR 1142 (42000): SELECT command denied to user 'hogetech'@'localhost' for table 'tbl'
+------+--------+ | id | str | +------+--------+ | 1 | update | +------+--------+
権限を付与していないテーブルに対する操作は、DENIED となることを確認できました。
REVOKE 権限 ON 権限レベル FROM 'ユーザー'@'ホスト'
Postgres から権限を取り消す場合
[ RECORD 2 ]------------+--------------------------
Schema | public
Name | tbl
Type | table
Access privileges| postgres=arwdDxt/postgres
| hogetech=r/postgres[ RECORD 2 ]------------+-------------------------- Schema | public Name | tbl Type | table Access privileges| postgres=arwdDxt/postgres
+------------------------------------------------------+ | Grants for hogetech@localhost | +------------------------------------------------------+ | GRANT USAGE ON *.* TO `hogetech`@`localhost` | | GRANT SELECT ON `db`.`tbl` TO `hogetech`@`localhost` | +------------------------------------------------------+
TCL(TransactionControlLanguage/トランザクション制御言語)

トランザクションの詳細については、以下の記事をご覧ください。
TCL には、主に以下の 4 種類の SQL コマンドが存在します。
BEGIN;
ここからは、トランザクションがどのような効果をもたらすのか、見ていきます。
+------+--------+ | id | str | +------+--------+ | 1 | update | +------+--------+
この状態で、トランザクション中の端末1と、別の端末2でテーブルを確認してみます。
+------+--------+
| id | str |
+------+--------+
| 1 | update |
| 2 | foo |
+------+--------+
+------+--------+ | id | str | +------+--------+ | 1 | update | +------+--------+
端末1のトランザクション中に実行した INSERT の結果が、端末2ではまだ反映されていません。
ROLLBACK
+------+--------+
| id | str |
+------+--------+
| 1 | update |
| 2 | foo |
+------+--------+
+------+--------+ | id | str | +------+--------+ | 1 | update | +------+--------+
先ほどの BEGIN (トランザクション) を始める前のテーブルに戻りました。
COMMIT
+------+--------+
| id | str |
+------+--------+
| 1 | update |
| 2 | foo |
+------+--------+
+------+--------+
| id | str |
+------+--------+
| 1 | update |
| 2 | foo |
+------+--------+
トランザクションの結果が確定し、別の端末2からでも INSERT の結果が反映されています。
なお、COMMIT した結果を ROLLBACK することはできません。
+------+--------+ | id | str | +------+--------+ | 1 | update | | 2 | foo | +------+--------+
SAVEPOINT <セーブポイント名>
トランザクションでテーブルを更新し、セーブポイントを設定してみます。
+------+--------+ | id | str | +------+--------+ | 1 | update | | 2 | foo | +------+--------+
+------+--------+
| id | str |
+------+--------+
| 1 | update |
| 2 | foo |
| 3 | before |
+------+--------+
ここで、セーブポイント save1 を設定します。
セーブポイント後に、さらにテーブルを更新します。
セーブポイント save1 までロールバックします。
+------+--------+ | id | str | +------+--------+ | 1 | update | | 2 | foo | | 3 | before | | 4 | after | +------+--------+
+------+--------+
| id | str |
+------+--------+
| 1 | update |
| 2 | foo |
| 3 | before |
+------+--------+
トランザクション開始時点ではなく、セーブポイントまでロールバックしています。
なお、通常のロールバックを行うと、トランザクション開始前のテーブルに戻ります。
+------+--------+ | id | str | +------+--------+ | 1 | update | | 2 | foo | +------+--------+
関連記事
| 学習ロードマップ | |||||
|---|---|---|---|---|---|
| 関連記事:データベースの基礎知識編 | |||||
|---|---|---|---|---|---|
| 関連記事:データベース設計 | |||||
|---|---|---|---|---|---|
参考記事
