
最初に
本記事は、以下のビッグデータ分析基盤シリーズの「ストリーム処理」編です。
- 【ビッグデータ入門1】ビッグデータ分析基盤
- 【ビッグデータ入門2】ストリーム処理
- 【ビッグデータ入門3】fluentd
- 【ビッグデータ入門4】Elasticsearch
- 【ビッグデータ入門5】Apache Kafka
- 【ビッグデータ入門6】Apache Hadoop
- 【ビッグデータ入門7】Apache Spark
- 【ビッグデータ入門8】Apache Hive
![[増補改訂]ビッグデータを支える技術 ——ラップトップ1台で学ぶデータ基盤のしくみ WEB+DB PRESS plus](https://m.media-amazon.com/images/I/51V-rBEb0PL._SL160_.jpg)



対象者
- Apache Hive で何ができるのか人
- Apache Hive のアーキテクチャの概要を知りたい人
- Apache Hive を動かしてみたい人
- Hadoop を触ったことある人
Apache Hive と Presto の違い
同じ SQL クエリエンジンの Presto と Hive の違いを比較します。
| Apache Hive | Presto | |
|---|---|---|
| 中間結果 | ストレージに書き出し | メモリに書き出し |
| 動作 | 遅い(ストレージに書き出すため) | 速い(メモリに書き出すため) |
| データ規模 | 大規模(メモリに乗り切らないデータも) | 小・中規模(メモリに乗り切るデータ) |
| 障害発生時 | ストレージに保存した中間データから再開 | 最初からやり直し |
Apache Hive を構成する4つのサービス
Apache Hive は主に次の 4 つのサービスから構成されています。
- MetaStore サービス
- HiveServer サービス
- HiveServer2 サービス
- WebHCat サービス
Apache Hive と クライアント、Hadoop、データベースの関連は以下のようになっています。
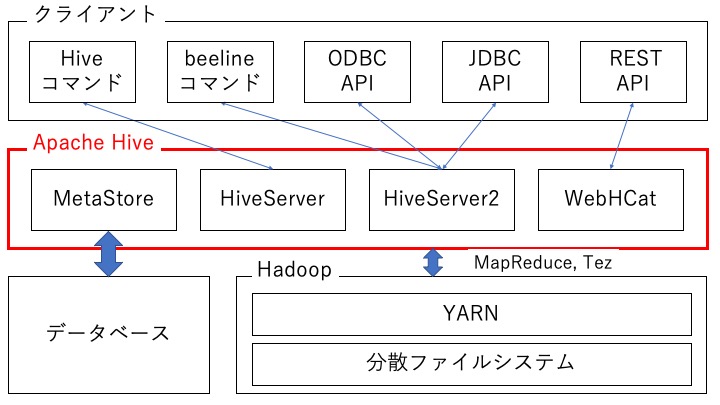
サービス1. MetaStore サービス
メタストアとは、メタデータを管理するデータベースのことです。
- メタデータ:Apache Hive のテーブルと Hadoop 上のファイルのデータとの対応情報
- データベース:Apache Derby, MySQL, MariaDB など
MetaStore サービスは Apache Hive がメタストアからメタデータをロードしたりストアしたりするためのサービスです。下記のファイルを例に、具体的なメタデータを例示します。
24957,Mr. Lemuel Schamberger MD,2014-01-17 06:50:01 25471,Cornelius Schinner,2014-01-04 10:56:48
- 1番目のフィールドは ID
- 2番目のフィールドは Name
- 3番目のフィールドは Date
- フィールドの区切り文字は ','
- 行の区切り文字は '¥n'
ID Name Date 24957 Mr. Lemuel Schamberger MD 2014-01-17 06:50:01 25471 Cornelius Schinner 2014-01-04 10:56:48
サービス2. HiveServer サービス
リモートクライアントからの受け取った SQL クエリを実行し結果を取得するサービスです。hive コマンドで Apache Hive にアクセスした場合は、このサービスが SQL クエリを実行します。
なお、Hive で利用可能な SQL 構文は、HiveQL と呼ばれ、CTAS (create table as select) が利用可能であったり、トランザクションが使えなかったりと若干の違いが見られる。
サービス3. HiveServer2 サービス
HiveServer の改良版であり、マルチクライアントの並列実行と認証をサポートします。
後述する beeline コマンドや ODBC, JDBC で Apache Hive にアクセスした場合は、HiveServer2 サービスが SQL クエリを実行します。
JDBC については以下の記事で説明しています。

HiveServer2 についてもっと知りたい方は公式ドキュメントをどうぞ。
The current implementation, based on Thrift RPC, is an improved version of HiveServer and supports multi-client concurrency and authentication. It is designed to provide better support for open API clients like JDBC and ODBC.
https://cwiki.apache.org/confluence/display/Hive/Setting+up+HiveServer2
サービス4. WebHCat
リモートクライアントからの受け取った Rest API を実行し結果を取得するサービスです。curl コマンドなどを利用して Apache Hive を操作することが可能です。
詳細を知りたい方は下記のドキュメントをご覧ください。

Apache Hive のインストール
ここからは Apache Hadoop と Apache Hive を実際にインストールして、Apache Hive を触ってみます。
Apache Hadoop をインストール
まずは、以下の記事を参考に Apache Hadoop をインストールします。
Apache Hive をインストール
次に Apache Hive をインストールします。まずは下記のサイトより、Apache Hive の最新バージョンを確認します。

Apache Hive を以下のコマンドでダウンロードします。(赤線箇所は上記サイトで確認したバージョンの URL を指定してください)
- tar zxfv apache-hive-3.1.2-bin.tar.gz
- echo "export PATH=$PATH:/home/`whoami`/apache-hive-3.1.2-bin/bin/" >> ~/.bash_profilesource ~/.bash_profile
Hive を初期化します。
メタストアとして MariaDB を利用する場合
sudo yum -y install mariadb-serversudo systemctl start mariadbexit<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost/metastore?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>test</value> </property> </configuration>schematool -dbType mysql -initSchema --verboseメタストアとして derby を利用する場合(手順が簡単)
schematool -dbType derby -initSchema --verbose
Apache Hive の使い方
データの事前準備
以降の Apache Hive の操作では、以下のテストデータを使用するものとします。
24957,Mr. Lemuel Schamberger MD,2014-01-17 06:50:01 25471,Cornelius Schinner,2014-01-04 10:56:48 29089,Dr. Buford Schmitt IV,2014-01-17 09:09:54 26653,Kaya Hartmann,2014-01-12 00:54:56 23678,Dr. Sheila Balistreri,2013-12-28 04:15:09 22632,Cyrus Hackett,2014-01-22 20:34:43 24794,Cielo Wolf,2014-01-10 01:00:27 27733,Kaycee Lindgren,2014-01-25 18:26:25 29774,Cathrine Harvey,2014-01-17 11:30:28 24616,Lola Marvin,2014-01-12 11:18:54 22805,Elisha Crooks,2014-01-26 08:52:18 21365,Cleve Pagac,2014-01-22 05:06:21 21744,Eldon Champlin DDS,2014-01-11 08:02:30 25471,Cornelius Schinner,2014-01-04 10:56:48 23680,Dr. Sheila Balistreri,2013-12-28 04:25:09 22632,Cyrus Hackett,2014-01-22 20:34:43
hive コマンドの使い方
hive コマンドを実行して SQL クエリで先程作成した test.csv ファイルを操作してみます。
- CREATE DATABASE test LOCATION '/tmp/hive/';show databases;
CREATE TABLE test.test_table( id int, name varchar(20), dates timestamp ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';ファイルをテーブルに変換するためのメタデータは次のように定義します。
- 1番目のフィールドは ID
- 2番目のフィールドは名前
- 3番目のフィールドは時間
- フィールドの区切り文字は ','
- 行の区切り文字は '¥n'
use test;show tables;test_table
- LOAD DATA LOCAL INPATH './test.csv' INTO TABLE test_table;
- select * from test_table;
24957 Mr. Lemuel Schamberg 2014-01-17 06:50:01 25471 Cornelius Schinner 2014-01-04 10:56:48 29089 Dr. Buford Schmitt I 2014-01-17 09:09:54 26653 Kaya Hartmann 2014-01-12 00:54:56 23678 Dr. Sheila Balistrer 2013-12-28 04:15:09 22632 Cyrus Hackett 2014-01-22 20:34:43 24794 Cielo Wolf 2014-01-10 01:00:27 27733 Kaycee Lindgren 2014-01-25 18:26:25 29774 Cathrine Harvey 2014-01-17 11:30:28 24616 Lola Marvin 2014-01-12 11:18:54 22805 Elisha Crooks 2014-01-26 08:52:18 21365 Cleve Pagac 2014-01-22 05:06:21 21744 Eldon Champlin DDS 2014-01-11 08:02:30 25471 Cornelius Schinner 2014-01-04 10:56:48 23680 Dr. Sheila Balistrer 2013-12-28 04:25:09 22632 Cyrus Hackett 2014-01-22 20:34:43
- exit;
上記により、hive コマンドで SQL クエリを利用して test.csv ファイルのデータを操作可能であることを確認できました。
beeline コマンドの使い方
beeline コマンドを実行して SQL クエリで test.csv ファイルを操作してみます。
-
beeline -u "jdbc:hive2:///test hive"
赤線箇所はユーザー名です。パスワードを聞かれますが、何も入力せずに Enter で OK です。
上記でアクセス出来ない場合は以下のコマンドも試してみてください。test データベースがない場合は、なお、本記事の hive コマンドの節をご覧ください
- select * from test_table;
+----------------+-----------------------+------------------------+ | test_table.id | test_table.name | test_table.time | +----------------+-----------------------+------------------------+ | 24957 | Mr. Lemuel Schamberg | 2014-01-17 06:50:01.0 | | 25471 | Cornelius Schinner | 2014-01-04 10:56:48.0 | | 29089 | Dr. Buford Schmitt I | 2014-01-17 09:09:54.0 | | 26653 | Kaya Hartmann | 2014-01-12 00:54:56.0 | | 23678 | Dr. Sheila Balistrer | 2013-12-28 04:15:09.0 | | 22632 | Cyrus Hackett | 2014-01-22 20:34:43.0 | | 24794 | Cielo Wolf | 2014-01-10 01:00:27.0 | | 27733 | Kaycee Lindgren | 2014-01-25 18:26:25.0 | | 29774 | Cathrine Harvey | 2014-01-17 11:30:28.0 | | 24616 | Lola Marvin | 2014-01-12 11:18:54.0 | | 22805 | Elisha Crooks | 2014-01-26 08:52:18.0 | | 21365 | Cleve Pagac | 2014-01-22 05:06:21.0 | | 21744 | Eldon Champlin DDS | 2014-01-11 08:02:30.0 | | 25471 | Cornelius Schinner | 2014-01-04 10:56:48.0 | | 23680 | Dr. Sheila Balistrer | 2013-12-28 04:25:09.0 | | 22632 | Cyrus Hackett | 2014-01-22 20:34:43.0 | +----------------+-----------------------+------------------------+
Apache Hive メタストアを確認(MariaDB を利用している場合)
Apache Hive により、メタストアにどのようなデータが作成されたのか確認します。
-
mysql -u root -ptest
- use metastore;
メタストアとして利用しているデータベース名を指定してください。
- select * from COLUMNS_V2;
+-------+---------+--------------+-------------+-------------+ | CD_ID | COMMENT | COLUMN_NAME | TYPE_NAME | INTEGER_IDX | +-------+---------+--------------+-------------+-------------+ | 1 | NULL | id | int | 0 | | 1 | NULL | name | varchar(20) | 1 | | 1 | NULL | time | timestamp | 2 | +-------+---------+--------------+-------------+-------------+
-
select TBL_ID, TBL_NAME from TBLS;
+--------+------------+ | TBL_ID | TBL_NAME | +--------+------------+ | 1 | test_table | +--------+------------+
- select * from SERDE_PARAMS ;
+----------+----------------------+-------------+ | SERDE_ID | PARAM_KEY | PARAM_VALUE | +----------+----------------------+-------------+ | 1 | field.delim | , | | 1 | line.delim | | | 1 | serialization.format | , | +----------+----------------------+-------------+
関連記事
ビッグデータ分析基盤入門シリーズは以下です。
- 【ビッグデータ入門1】ビッグデータ分析基盤
- 【ビッグデータ入門2】ストリーム処理
- 【ビッグデータ入門3】fluentd
- 【ビッグデータ入門4】Elasticsearch
- 【ビッグデータ入門5】Apache Kafka
- 【ビッグデータ入門6】Apache Hadoop
- 【ビッグデータ入門7】Apache Spark
- 【ビッグデータ入門8】Apache Hive


参考にした記事
公式ドキュメント

以下のサイトに参考にさせていただきました。
- https://cwiki.apache.org/confluence/display/Hive/Home
- https://suzuken.hatenablog.jp/entry/2014/07/04/001013
- https://qiita.com/Esfahan/items/a6f2107876e5a712a72c
- https://dev.classmethod.jp/articles/hadoop-advent-calendar-06-hive-introduction/
- https://open-groove.net/hive/hiveserver2-beeline/
- https://www.ne.jp/asahi/hishidama/home/tech/apache/hive/ql.html
- https://open-groove.net/hive/hive-mariadb-as-metastoredb/