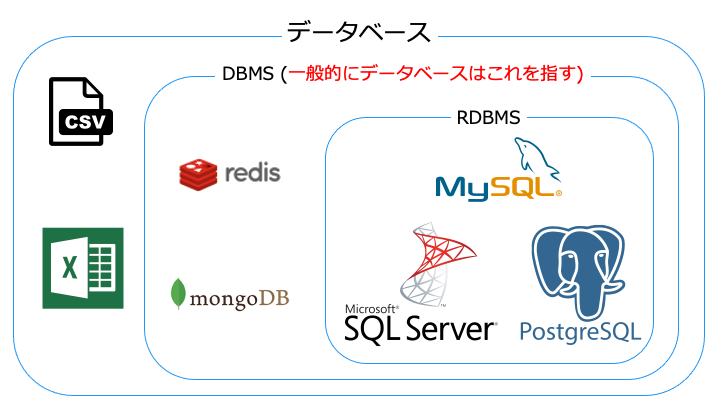
データベースは、Excel から、データベース管理システム (DBMS) まで様々な種類が存在します。
通常、データベースはデータベース管理システム (DBMS) を指すことが多いです。
| 関連記事:データベースの基礎知識編 | |||||
|---|---|---|---|---|---|



| 学習ロードマップ | |||||
|---|---|---|---|---|---|




















DBMS(データベース管理システム)
データベースに DBMS が利用される理由は、DBMS が次のような機能を持つためです。
DBMS の機能の一例
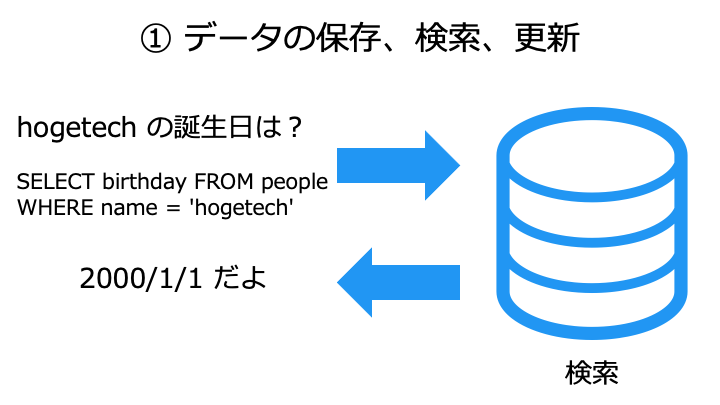
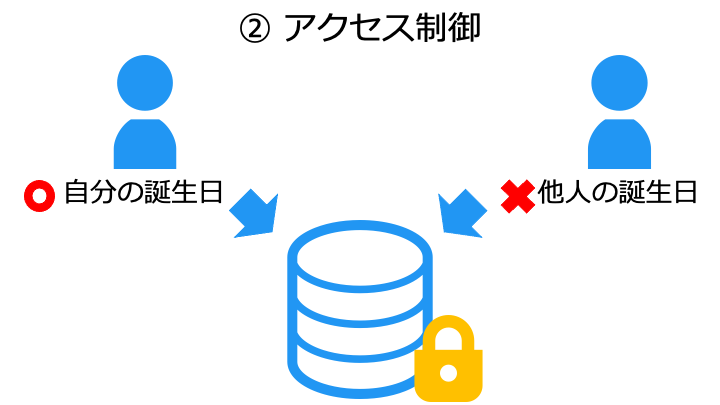
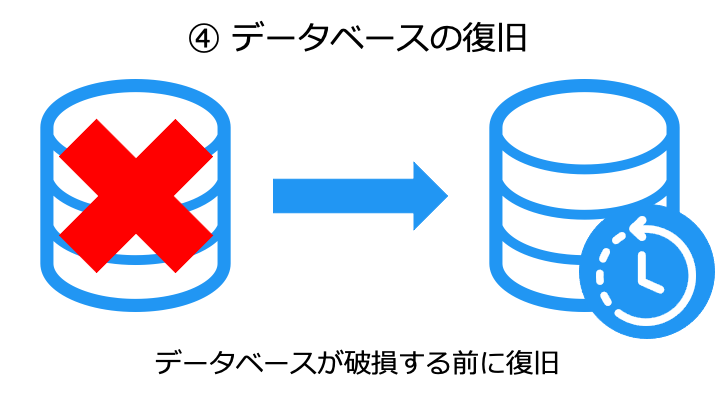
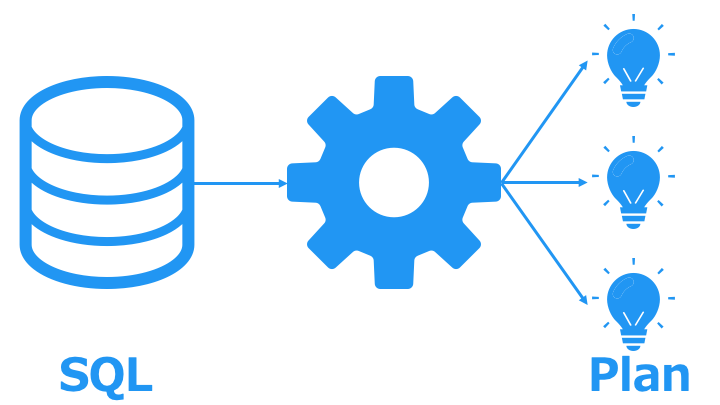
| DBMS が持つ機能の詳細 | |||
|---|---|---|---|


DBMS の種類
現在利用されている DBMS は、主に次の 2 種類が存在します。
- RDBMS (Relational DBMS/関係データベース管理システム)
- NoSQL (Not only SQL)
























RDBMS とは
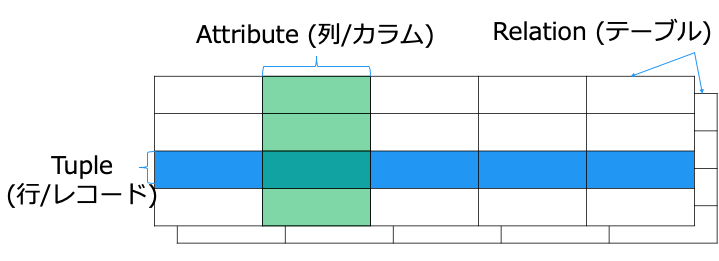

- 上は [ディレクター] という共通の集合なので、テーブルです
- 下は共通する項目がないので、テーブルとは呼びません (ただの 2 次元表です)
なお、以下のように共通点で分割すると、テーブルになります。
([商品] と [ディレクター] テーブルにリレーションシップ (関係性) は無いですが)
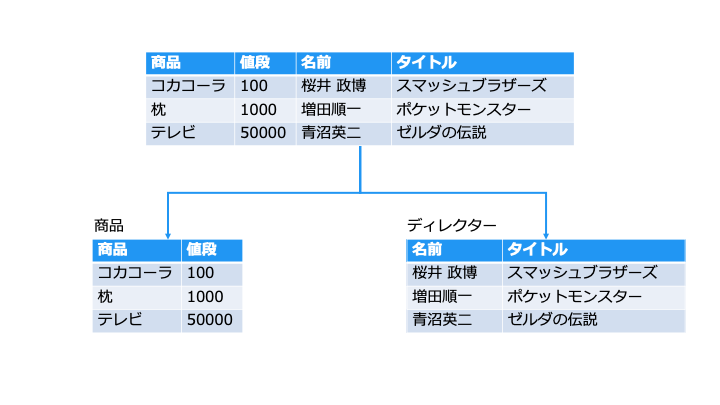
関係スキーマ
Relation (関係) がどの Attribute (属性) 名を持つか表したものを関係スキーマと言います。
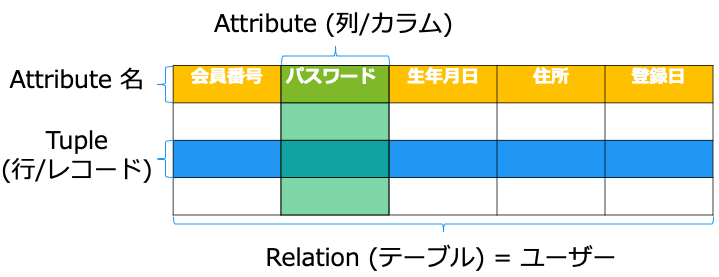
上記の関連スキーマは、「ユーザー (ユーザーID, パスワード, 生年月日, 住所, 登録日)」です。
RDBMS の種類
| RDBMS の例 | 説明 |
|---|---|
 | OSS、初心者向け、広く普及 |
 | MySQL のフォーク、Oracle に MySQL が買収されたため |
 | OSS、機能が豊富 |
 | Microsoft 社製、Windows と親和性が高い |
 | Oracle 社製、2024時点のエンジンランキング1位※ |
RDBMS の構造
RDBMS は次のような階層構造を持ちます。
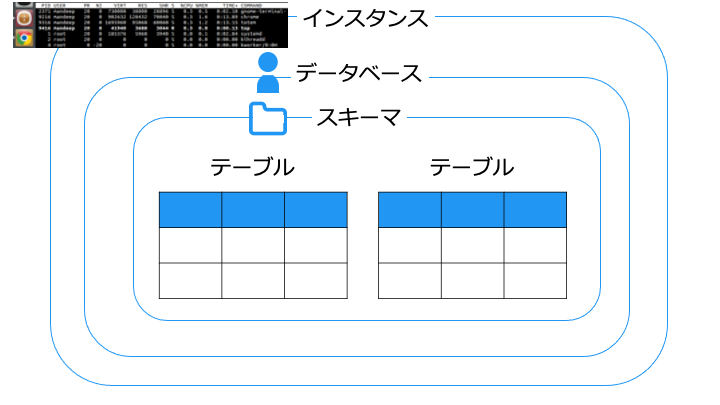
ユーザーは、接続中のデータベース内にあるデータしかアクセスできません。
スキーマは、用途ごとに分けたり、中にあるテーブルの権限を一括設定したりできます。
なお、「3層スキーマ」や「関係スキーマ」もスキーマと呼ばれます。
なお、RDBMS の構造は、以下のように製品によって異なります。
| MySQL/MariaDB | PostgreSQL | SQL Server | Oracle Database | |
|---|---|---|---|---|
| インスタンス | ○ | ○ (サーバーと呼ぶ) | ○ | ○ |
| データベース | ○ ※1, 2 | ○ | ○ | △ ※3 |
| スキーマ | △ ※1, 2 | ○ | ○ | ○ |
| テーブル | ○ | ○ | ○ | ○ |
※1 CREATE SCHEMA is a synonym for CREATE DATABASE
https://dev.mysql.com/doc/refman/8.0/en/create-database.html
※2 In MariaDB Server, schema is a synonym for database.
https://mariadb.com/docs/server/ref/mdb/sql-statements/CREATE_DATABASE/
1つのデータベース・インスタンスは一度に1つのデータベースにのみ関連付けられます。
https://docs.oracle.com/cd/E57425_01/121/CNCPT/startup.htm
































NoSQL とは
昔は、階層型やネットワーク型モデルが存在しましたが、今やリレーショナル型の RDBMS しか存在しません。

そこで、RDBMS 以外のデータベースを発展させようという目的で NoSQL が誕生しました。
NoSQL は、RDBMS で捌ききれないデータ量や、特定の用途に特化したい時に使います。
(つまり、基本は RBDMS でいいです。)
NoSQL と RDBMS の違い
NoSQL と RDBMS の主な違いは以下のとおりです。
- ◎:複数のコンピュータで並列分散処理を行う
- ◎:非構造化データ (2次元テーブルではない形式) を保存できる
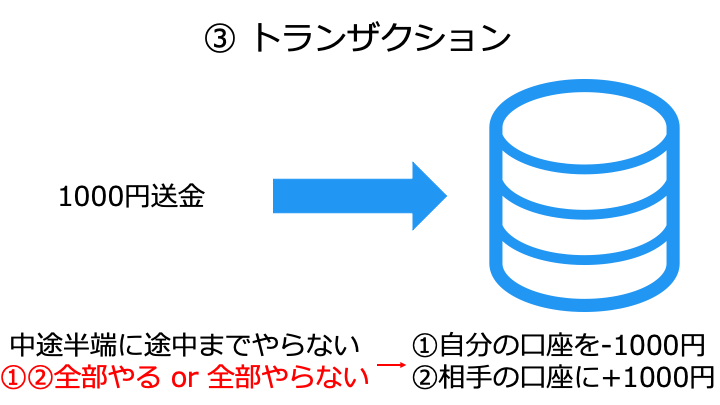
- ×:トランザクション (複数の処理を一括処理) や ACID 特性の一部に未対応
- ×:JOIN (複数のテーブルを結合) はクライアント側で行う
NoSQL は RDBMS の一部機能を犠牲に、目的に特化した機能を持つものが多いです。
ただし、最近の NoSQL はトランザクションに対応してたり、JOIN できたりと、RDB との違いが無くなりつつある製品もあります。
NoSQL の種類
| NoSQL の種類 | 説明 | DBMS の例 |
|---|---|---|
| ドキュメントストア | ドキュメント (JSON など) でデータを格納 |   |
| キーバリューキャッシュ | キーとバリュー (値) でデータを格納 |  |
| ワイドカラムストア | 2次元のキーとバリューでデータを格納 RDBMSと違い、列名が行ごとに異なる場合もある |  |
| グラフデータベース | ノード (頂点)・エッジ (辺)・プロパティ (属性) でデータを格納 |  |
参考資料
| 学習ロードマップ | |||||
|---|---|---|---|---|---|
| 関連記事:データベースの基礎知識編 | |||||
|---|---|---|---|---|---|
| 関連記事:データベース設計 | |||||
|---|---|---|---|---|---|