ビッグデータとは、通常のソフトウェアでは処理できないほどの大規模な (テラバイト、ペタバイト、エクサバイト規模の) データのことです。
本記事では、ビッグデータを以下のように可視化、分析することをゴールとします。
ビッグデータがスモールデータ用のソフトウェア (Excel や RDB など) で処理できない理由は、以下のようにハードウェアリソースの限界を迎えるためです。
- CPU の限界:計算するデータが多すぎて、業務時間内で処理が終わらない
- メモリの限界:データが多すぎてメモリに乗り切らないため、処理ができない
- ストレージの限界:データが多すぎてストレージに入りきらないため、処理ができない
そこでビッグデータを処理する場合、並列処理が可能なソフトウェアを利用して、複数のコンピュータ (のハードウェアリソース) を利用します。
本記事では、以下の流れに沿ってビッグデータの各用語の意味/可視化/分析方法を説明します。
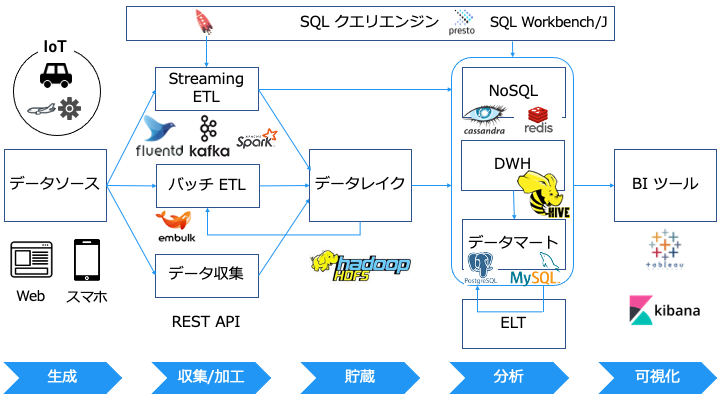
初めに
本記事は以下の書籍を参考にしています。
本記事は、ビッグデータ分析基盤シリーズの「ビッグデータ分析基盤」編です。
- 【ビッグデータ入門1】ビッグデータ分析基盤
- 【ビッグデータ入門2】ストリーム処理
- 【ビッグデータ入門3】fluentd
- 【ビッグデータ入門4】Elasticsearch
- 【ビッグデータ入門5】Apache Kafka
- 【ビッグデータ入門6】Apache Hadoop
- 【ビッグデータ入門7】Apache Spark
- 【ビッグデータ入門8】Apache Hive
なお、ビッグデータ分析では、スモールデータ分析で利用する RDB の知識もあると良いです。
- 【データベース入門1】データベースとは
- 【データベース入門2】SQL コマンド(SQL 文)
- 【データベース入門3】トランザクションと ACID 特性
- 【データベース入門4】クラスター・レプリケーション
- 【データベース入門5】オプティマイザー・実行計画
- 【データベース入門6】テーブル設計・正規化
データソースとは
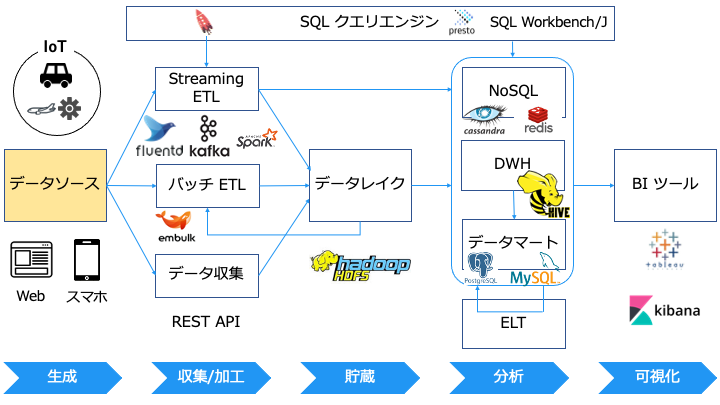
データソースとは、分析したいデータの発生源です。
データソースの具体例は、以下のログやテーブル情報となります。
- Web サーバー
- IoT 機器 (工場や車のセンサーなど)
- モバイル機器 (スマホなど)
なお、データソースという言葉が指す対象は、立ち位置によって変わります。
(例えば、上図の BI ツールから見たデータソースは NoSQL, DWH, データマートです。)
また、データは次の3つの種類に分かれます。
構造化データとは
構造化データの例
構造化データの実例は以下です。
ID,NAME,DATE 1,hoge,2020/08/01 00:00 2,foo,2020/08/02 00:00 3,bar,2020/08/03 00:00
特徴
- コンピュータで扱いやすい (RDB + SQL クエリで操作可能)
- 事前に行と列を定義が必要 (固定スキーマ)
- 保存に手間がかかる (行、列の形にデータを変換する必要あり)
- 各行は、同じ列名を持つ
- ネストしない (テーブルのフィールドの値に、テーブルが含まれることは無い)
- 別のテーブルを参照する場合は JOIN する
非構造化データとは
非構造化データの例
非構造化データの例は以下のとおりです。

非構造化データの実例は以下です。
<6>Feb 28 12:00:00 192.168.0.1 fluentd[11111]: [error] Syslog test
非構造化データには列名がないため、列の意味を理解するのが困難です。
(上記の場合は<6>の意味など)
特徴
半構造化データとは
半構造化データ とは、非構造化データの各要素に属性名 (列名) をつけたデータです。
ただし、表形式では無いです。
半構造化データの例
非構造化データの例は以下のとおりです。他にも Parquet や ORC などが存在します。
非構造化データを半構造化データに変換する例は以下のとおりです。
■非構造化データ (変換前)
<6>Feb 28 12:00:00 192.168.0.1 fluentd[11111]: [error] Syslog test
■半構造化データ (変換後)
{
"jsonPayload": {
"priority": "6",
"host": "192.168.0.1",
"ident": "fluentd",
"pid": "11111",
"message": "[error] Syslog test"
}
}非構造化データでは「6」が何を表すかわかりませんでしたが、半構造化データは属性名がついてるので、「6」が priority であることがわかります。
特徴
- 属性を持つため、コンピュータが扱いやすい (半構造化データ用のクエリなど)
- 事前に属性の定義を必要としない (可変スキーマ)
- いつで新しい属性を追加可能
- 保存が少し楽 (事前にデータの形を決めなくて良い。後から好きに属性を追加できる)
- 各行で異なる属性を持つことが可能
- ネスト可能
構造化/非構造化/半構造化の違い
構造化/非構造化/半構造化の違いをまとめた表は以下のとおりです。
| 構造化 | 非構造化 | 半構造化 | |
|---|---|---|---|
| 表形式 | Yes | No | No (表形式に変換可能) |
| スキーマ (行/列/データ型など) | 固定スキーマ (事前に定義) | スキーマレス | 可変スキーマ (後で属性を追加可能) |
| 保存 | 面倒 固定スキーマで変換 | 容易 無変換 | 少し容易 可変スキーマで変換 |
| クエリ可能 | Yes | No | Yes (対応する DB) |
| サーバー側 JOIN | 必要 データがネスト不可能 | - | 不要 データがネスト可能 |
可変スキーマは、データに合わせてスキーマ側の属性を後から追加できる
データ分析のゴールは、クエリを使って欲しいデータを抽出することです。
そのため、非構造化データを分析するためには、クエリを使えるように構造化データもしくは半構造化データに変換する必要があります。
ETL/ELT とは
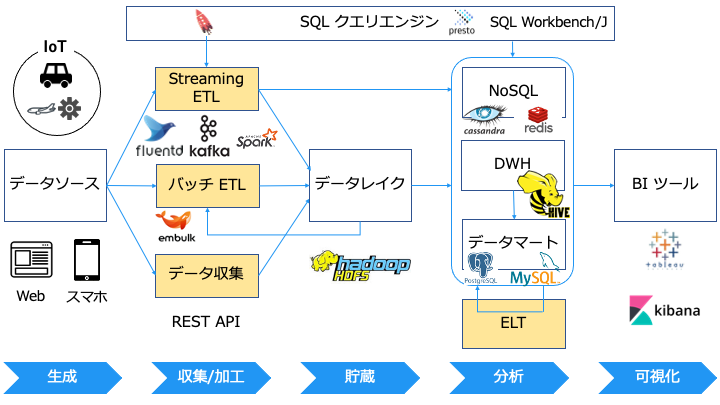
ETL とは、以下の3つの処理を処理のことです。
・Extract - データソースからデータを抽出
・Transform - 抽出したデータを加工/変換
・Load - ターゲットに加工/変換済みのデータをロード
ELT とは、ETL の加工/変換 (Transform) とロード (Load) の順番が入れ替わったものです。
データソース側で加工/変換 (Transform) しないこと理由の一例は以下のとおりです。
- Web サーバー: 運用サーバーに負荷をかけたくない
- IoT機器: 変換処理できるほどのスペックがない
- モバイル機器: お客様の機器で処理できない
なお、ETL には次の2種類があります。
- バッチ ETL
- ストリーミング ETL
| バッチ ETL | ストリーミング ETL | |
|---|---|---|
| 目的 | スループット重視 | リアルタイム重視 |
| 処理するタイミング | 一定の間隔 (毎時、毎晩など) | データが発生した時 |
| 処理にかかる時間 | 数分〜数時間 | 数ミリ秒〜数秒 |
| ユースケース | 夜間バッチ 月次処理 | リアルタイム性の必要な処理 (例:クレジットカードの不正検出など) |
Extract (抽出)
データソースからデータを Extract (抽出) するソフトウェアは以下のとおりです。
(外部から直接 SQL クエリや REST API で抽出する方法もあります。)
| ソフトウェア | ETL の種類 |
|---|---|
| Embulk | バッチ ETL |
| fluentd | ストリーミング ETL |
| beats (Elasticsearch) | ストリーミング ETL |
| Kafka Producer API (Kafka) | ストリーミング ETL |
なお、ストリーミング ETL では、Extract と Transform の間に Pub/Sub メッセージングシステムを置く場合があります。
複数の受信者に同じメッセージを届ける一対多の出版-購読モデル(Pub-Subモデル)による受け渡しに対応しているものもある。
https://e-words.jp/w/%E3%83%A1%E3%83%83%E3%82%BB%E3%83%BC%E3%82%B8%E3%82%AD%E3%83%A5%E3%83%BC%E3%82%A4%E3%83%B3%E3%82%B0.html
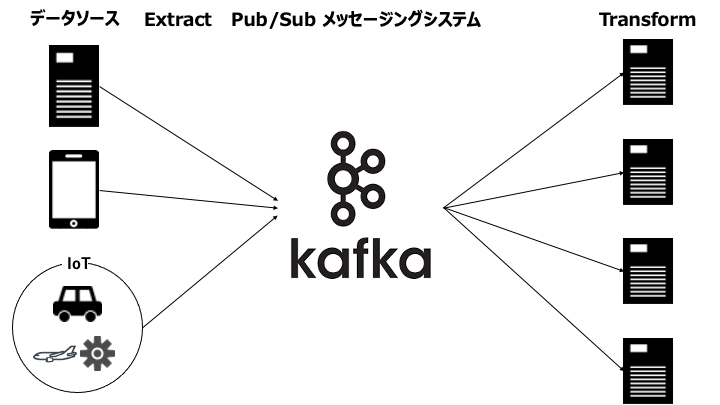
Pub/Sub メッセージングシステムを置く理由は以下のとおりです。
- リアルタイムで Transform を完了するために、複数のコンピュータに処理を分散し高速化
- ピーク時の急激なデータの増加に Transform が間に合わない場合、一時的にデータを保存
Transform (加工/変換)
抽出したデータは、主に以下のソフトウェアで Transform (加工/変換) します。
- SQL クエリ
- pandas
- fluentd
- logstash (Elasticsearch)
- Kafka Streams (Kafka)
- Spark Streaming (Apache Spark)
Transform では、構造化/半構造化データに変換したり、データを追加/削除したりします。
Load (ロード)
Transform で適切な形に変換したデータは、主に以下の4つの宛先に Load します。
- NoSQL
- データレイク
- DWH (データウェアハウス)
- データマート
データレイクとは
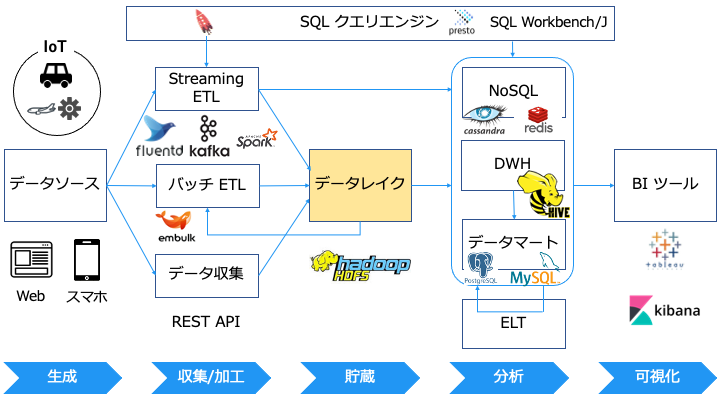
データレイクとは、全てのフォーマット (構造化/非構造化/半構造化) のデータを、将来に備えて無制限に蓄積するストレージです。
データレイクの例
データレイクのサービス/ソフトウェアの例は、以下のとおりです。
- Hadoop HDFS
- Amazon S3
データレイクには、様々な形式のデータを無尽蔵に貯蔵していきます。
そのため、後から容量を追加可能なストレージがデータレイクとして選ばれます。
なお、Hadoop HDFS については以下の記事をご覧ください。
NoSQL データベースとは
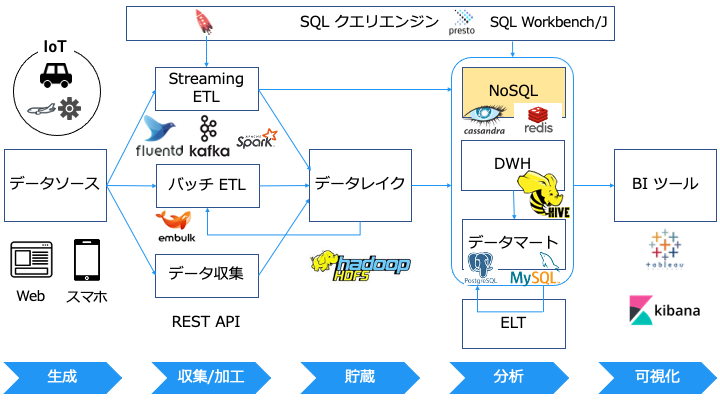
「NoSQL」という名前は、実際には特定の技術を指していないという不幸を背負っています。この言葉は、もともと2009年にオープンソースの非リレーショナルな分散データベースのミートアップのために、目を引きやすいTwitterのハッシュタグとして使われただけのものです
https://amzn.to/3HSO9hK
データ指向アプリケーションデザイン ―信頼性、拡張性、保守性の高い分散システム設計の原理
NoSQL は RDB からなんらかの制約を緩め、パフォーマンスを追求したデータベースです。
(逆に言うと、RDB で満足するパフォーマンスが出る場合は、NoSQL は必要ないかもしれません)
NoSQL と RDB の違い
NoSQL と RDB の違いは以下のとおりです。
| NoSQL | RDB | |
|---|---|---|
| 用途 | 低レイテンシー (ハイパフォーマンス) 処理 | トランザクション処理 |
| データモデル | 非構造化データが多い (Key-Value、ドキュメント、グラフ等) | 構造化データ (リレーショナルモデル) |
| JOIN | クライアント側で JOIN を推奨 サーバー側はデータをネストして対応 | サーバー側で JOIN |
| スキーマ | 可変スキーマが多い | 固定スキーマ |
| 拡張性 | ノードを追加し処理を分散 ※ノード = コンピュータ | ノード自体の性能を上げる 読み取り専用のレプリカノードを追加 |
NoSQL の種類と例
NoSQL の有名なデータモデルの種類は以下のとおりです。
| データモデルの種類 | 説明 | 製品例 |
|---|---|---|
| Key-Value キャッシュ (インメモリ) | キーと対応する値でメモリ上にデータを管理 (連想配列、辞書型) | Memcached Redis |
| Key-Value ストア | キーと対応する値でストレージ上にデータを管理 (連想配列、辞書型) | DynamoDB |
| ワイドカラムストア | テーブル、行、列でデータを管理 (2次元の Key-Value ストア) RDB と異なり、行ごとに列名が違っても OK | Cassandra HBase |
| グラフデータベース | ノード、エッジ、プロパティでデータを管理 | Neo4j |
| ドキュメントストア | 半構造化データ (ドキュメント指向) でデータを管理 | Elasticsearch MongoDB |
データウェアハウス (DWH) とは
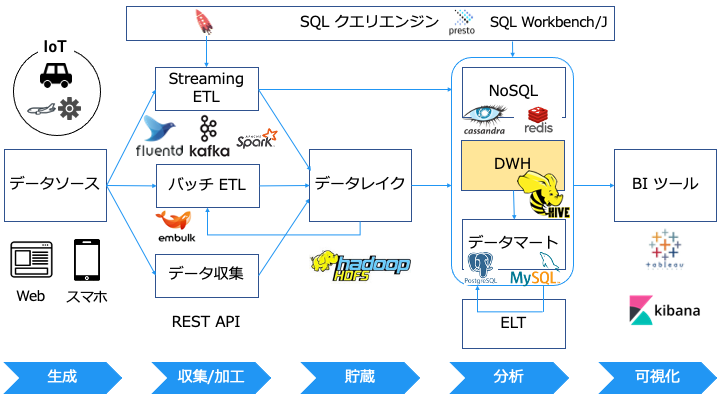
データウェアハウス (DWH) と RDB の違い
データウェアハウス (DWH) と RDB の違いは以下のとおりです。
| データウェアハウス (DWH) | リレーショナルデータベース (RDB) | |
|---|---|---|
| 目的 | 分析 (OLAP) | トランザクション処理 (OLTP) |
| ストレージ | 列指向ストレージ形式 | 行指向ストレージ形式 |
| データ量 | ビッグデータ | スモールデータ |
| データの正規化 | 部分的に非正規化 ・スタースキーマ ・スノーフレークスキーマ | 第三正規形 |
RDB はデータ量が増えると極端に遅くなります。
そのため、大量のデータを分析する場合はデータウェアハウス (DWH) を利用します。
(逆に言うと、高速に分析できるスモールデータの場合は、RDB で OKです。)
列指向データベース (カラムナデータベース) とは
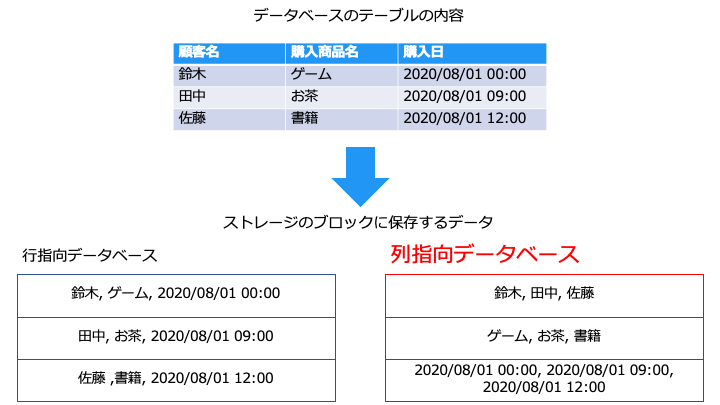
列指向データベースでは、以下のファイル形式 (列指向ストレージ形式) でデータを保存します。
- ORC
- Parquet
また、列指向データベース (列指向ストレージ形式) の特徴は以下の3つです。
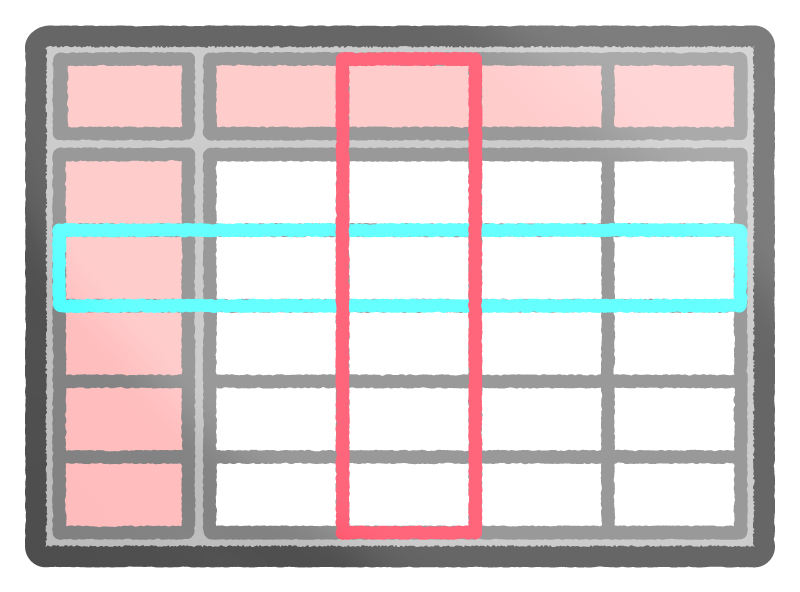
分析時の読み込み効率が良い
列指向データベースでは、不要な列を読み飛ばせるので、読み込み効率が良くなります。
データ分析では、列 (カラム) のみが必要となることが多いです。
例えば、以下のテーブルから注文のピーク時間を分析する場合、「購入日」カラムのみを集計すればよく、テーブル全体を読み込む必要がありません。
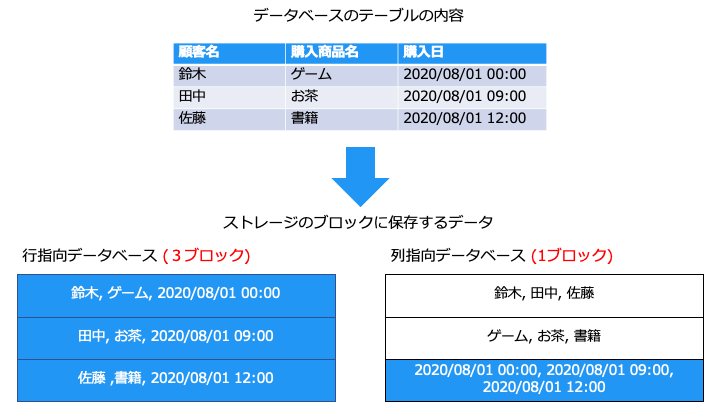
上記の例では、列指向データベースを利用するとブロックの読み取りが 1/3 に削減可能です。
書き込み効率が悪い
列指向データベースでは、書き込むブロックを探す必要があるので、書き込み効率が悪くなります。
各データベースの書き込みの手順は以下のとおりです。
■列指向データベース
- 書き込むブロックを探す
- 列の内容を書き込む
- すべての列に対して1と2を繰り返す
■行指向データベース
- 一番最後のブロックに書き込む
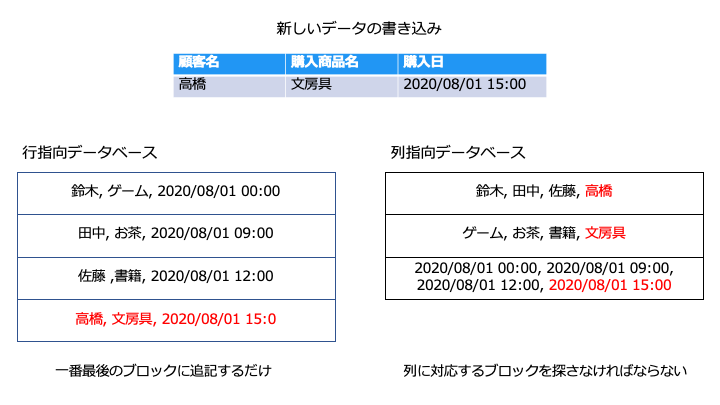
書き込みに関しては、行指向データベースのほうが効率が良いことがわかります。
圧縮率が良い
同じ列には同じデータの型が入るため、列指向データベースでは圧縮効率が良くなります。
例えば、「購入数」カラムでは同じ数字が続きやすいです。この場合圧縮効率がよくなります。
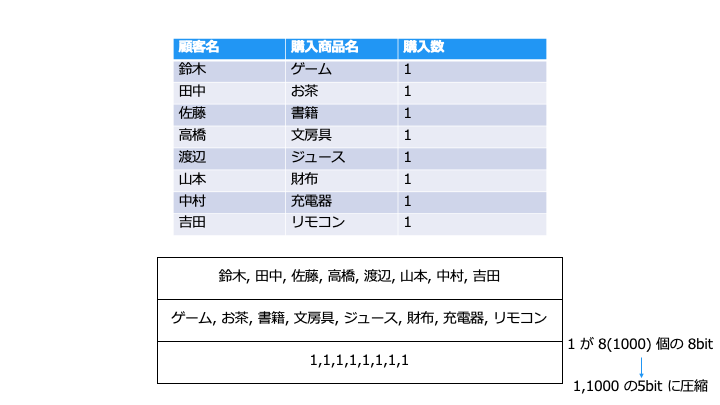
圧縮率が良い場合、一度のストレージアクセスで多くのデータを読み取ることができます。
データウェアハウス (DWH) の例
データウェアハウス (DWH) の具体的なソフトウェアやサービスは以下のとおりです。
なお、Hadoop や Hive については以下の記事をご覧ください。

データレイクと DWH の違い
| データウェアハウス (DWH) | データレイク | |
|---|---|---|
| 目的 | "今" データを最速で分析する | "将来" 利用するデータを溜め込む |
| データフォーマット | 構造化/半構造化 | すべて (構造化/非構造化/半構造化) |
| 保存 | 面倒 (構造化データに変換) | 容易 (無変換で保存) |
| 分析・抽出 | 早い | 遅い (構造化されてないから) |
| 新しいニーズの分析 | 不可 (スキーマ以外のデータを捨てる) | 可能 (すべてのデータを持つ) |
| 容量 | 制限あり | 無制限 |
データマートとは
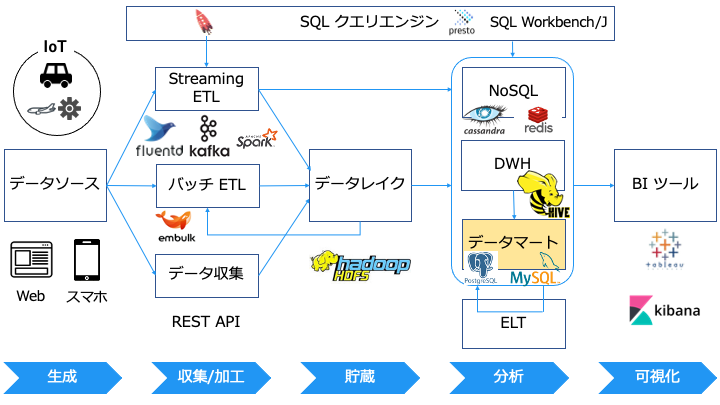
データマートとデータウェアハウス (DWH) の違い
データウェアハウスの規模が小さくなったものがデータマートと言えます。
| データマート | データウェアハウス | |
|---|---|---|
| 目的 | 必要なデータだけを分析 | すべてのデータを分析 |
| 範囲 | 単一部署 | 全部署 |
| サイズ | スモールデータ (100GB 未満) | ビッグデータ (100GB 以上) |
| 少量のデータ分析 | 得意 (高速) | 不得意 (低速) |
| 大量のデータ分析 | 不得意 (低速) | 得意 (高速) |
メモリにすべてのデータが乗る場合、ローカルホスト1台で処理するのが一番早いです。
(ノード間の通信や結果をマージするレイテンシーが無いため)
そのため、分析を高速化する目的で、データウェアハウスから必要なデータだけをデータマートに移動します。
データマートの例
データマートの一例としては以下のものが挙げられます。
上記を見てわかるように、規模が小さく分析可能なデータストアを指します。
SQL クエリエンジンとは
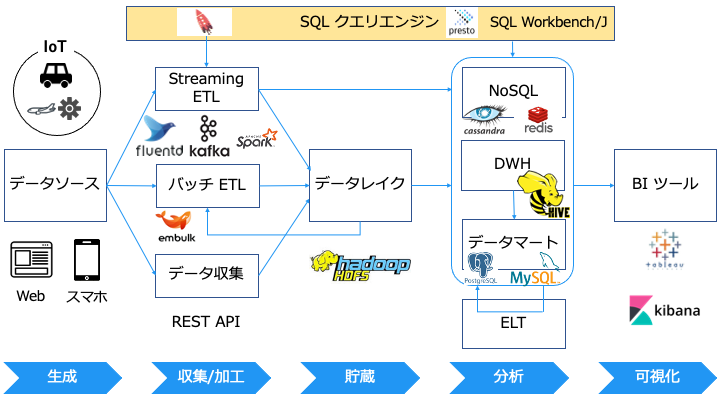
「プログラミングせずに、もっと簡単にデータを操作がしたい」という要望から、SQL クエリエンジンが誕生しました。
SQL クエリについて詳しく知りたい方は、以下の記事をご覧ください。

SQL クエリエンジンの例
SQL クエリエンジンの具体的なソフトウェアやサービスは以下のとおりです。
- ETL
- NoSQL
- Elasticsearch SQL
- PartiQL (Dynamo DB)
- データレイク
- Presto
- Apache Hive
- データウェアハウス
- SQL Workbench/J
- DBeaver
BI (Business Intelligence) ツール
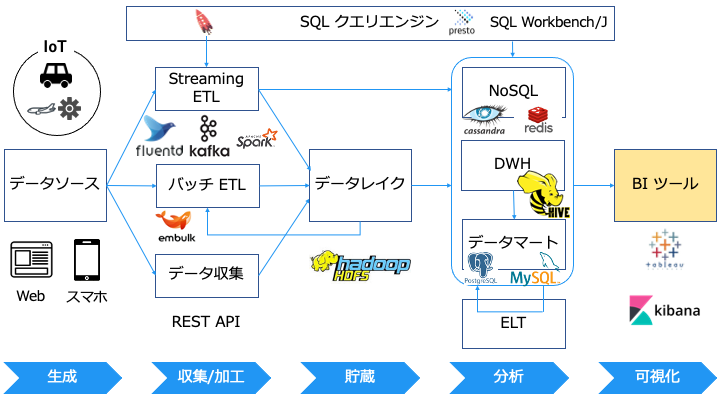
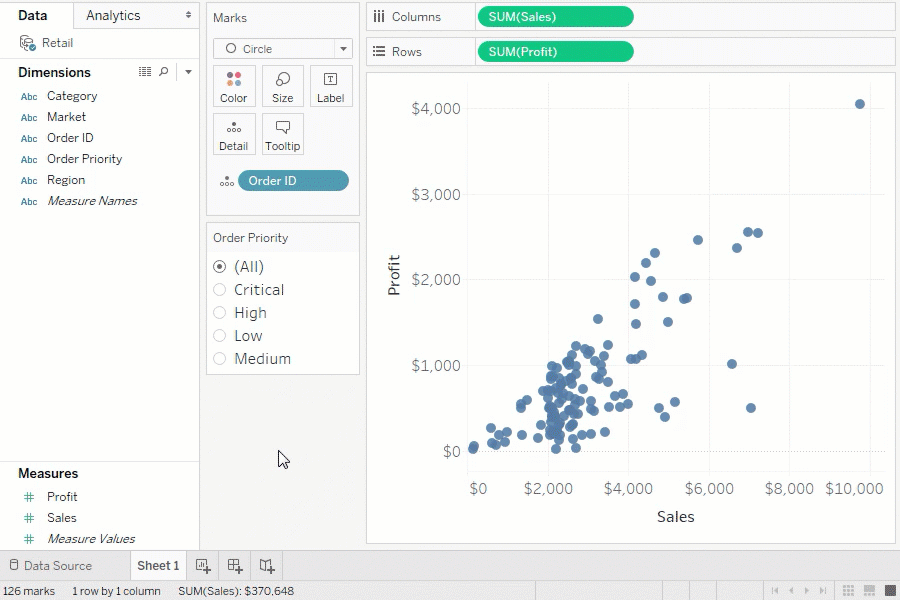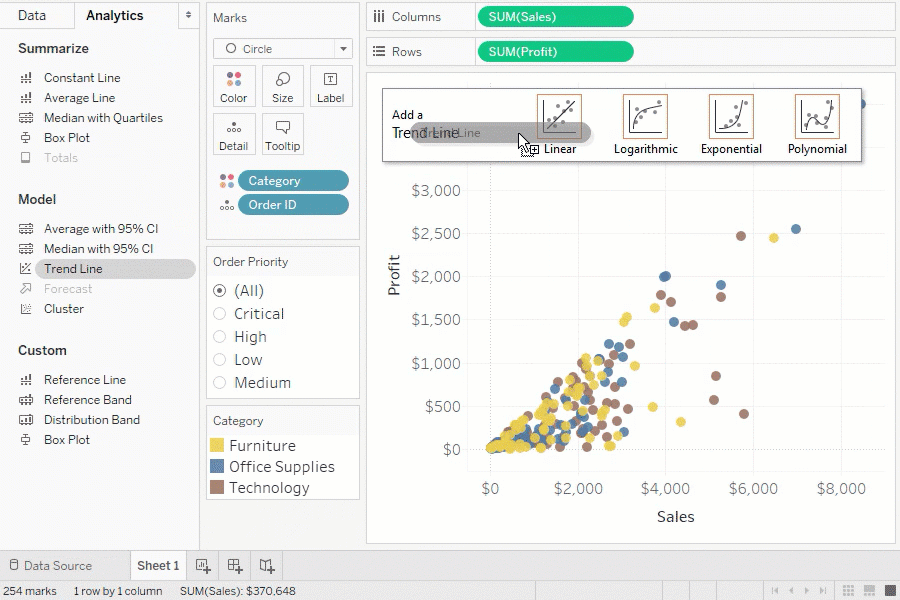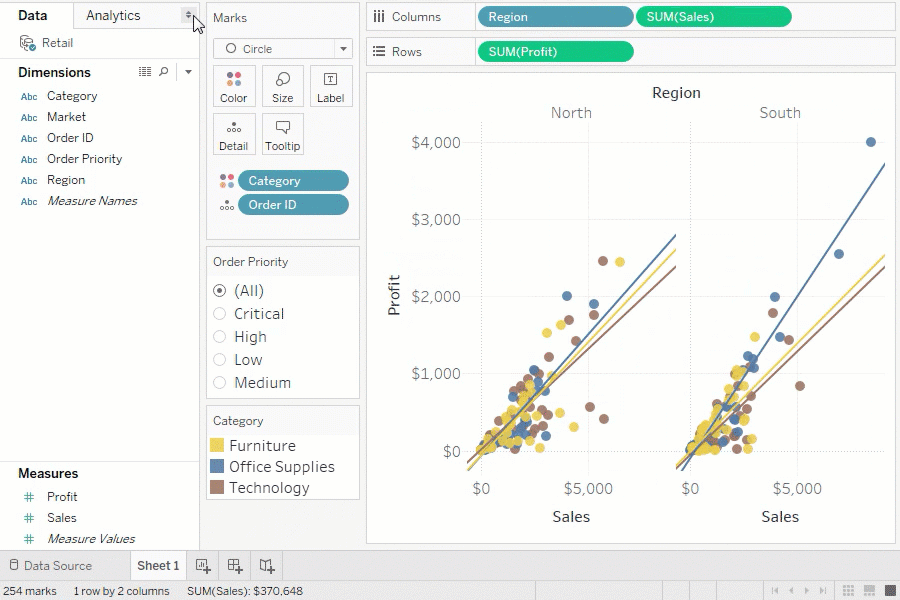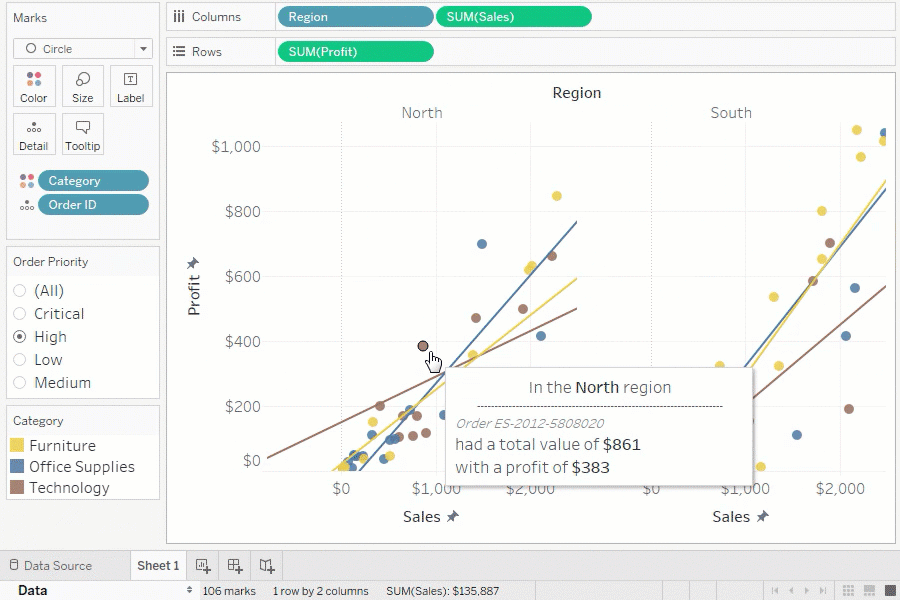
BI ツールの例
代表的な BI ツールは以下のとおりです。
- Tableau
- Grafana
- Kibana (Elasticsearch)
- QuickSight
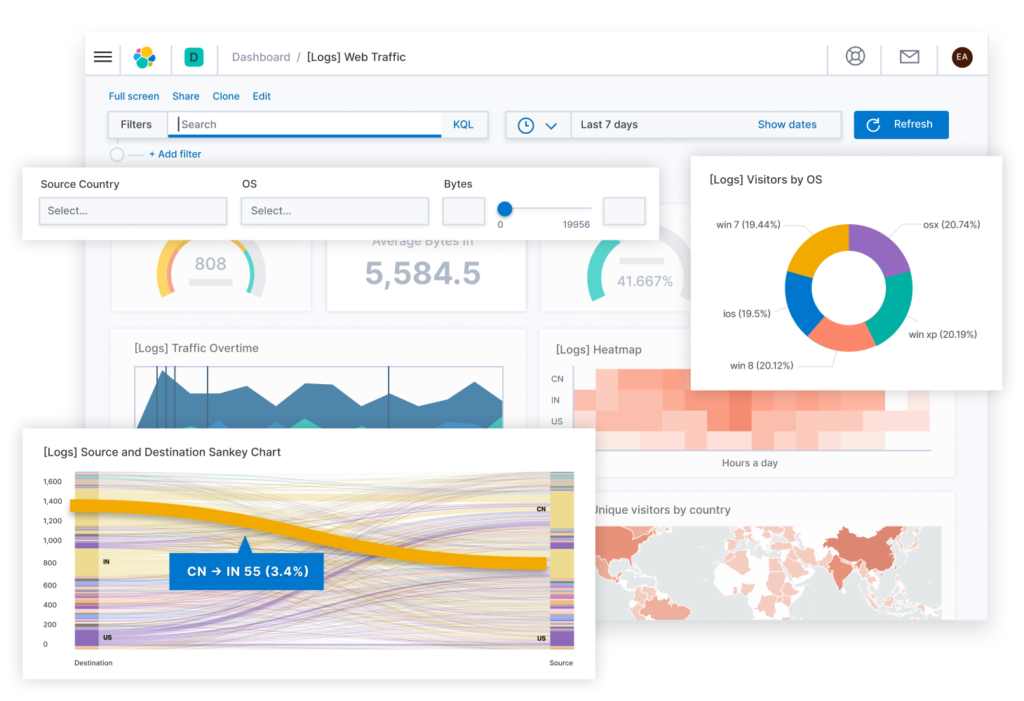
ビッグデータ分析においてはここまで来ればゴールです。お疲れ様でした。
データストアまとめ
RDB とビッグデータ分析基盤でよく利用されるデータストアの違いを表にまとめました。
| RDB | NoSQL | DWH | データレイク | |
|---|---|---|---|---|
| OSS/サービス |  |   |  |   |
| 目的 | トランザクション (OLTP) | 特定のパフォーマンス重視 | 分析 (OLAP) | データを貯蔵 |
| データ構造 | 構造化 | 半構造化 | 構造化 半構造化 | 構造化 非構造化 半構造化 |
| スキーマ | 固定スキーマ | 可変スキーマ | 固定スキーマ | スキーマレス (データカタログ) |
関連記事
ビッグデータ分析基盤入門シリーズの続きは以下です。
- 【ビッグデータ入門1】ビッグデータ分析基盤
- 【ビッグデータ入門2】ストリーム処理
- 【ビッグデータ入門3】fluentd
- 【ビッグデータ入門4】Elasticsearch
- 【ビッグデータ入門5】Apache Kafka
- 【ビッグデータ入門6】Apache Hadoop
- 【ビッグデータ入門7】Apache Spark
- 【ビッグデータ入門8】Apache Hive
参考ページ
